简介
综合转载于:
第一章 · 初步了解自然语言处理的任务、方法和模型
第 1 节 · 我们要解决什么问题:NLP 任务
自然语言处理领域要实现的终极形态,就是让机器按照人类偏好的方式,与人类通过语言文字高效交互。而人类高等文明中「最高等」的那部分文明,全都是人类在发明了语言文字后才诞生的 —— 物理、数学、生物医药、金融体系、现代通信、航空航天、汽车工业、计算机科学等等。而绘画、音乐等视听刺激,更多来自本能。因此这里船涨再引用《船涨:LLM 革命前夜》中一段话:
从第一性原理角度讲,生成图片的应用广度,远远小于生成文本。文本内容的本质是语言文字的理解与生成,人类历史有 600 万年,但是人类文明历史大概就 6000 年,文明的大发展出现在近 2000 多年的原因,主要来自 3500 多年前人类发明了文字。所以 AI 生成文本,意味着 AI 可以用人类熟悉的方式(语言文字)与人类高效协作,这必将引爆生产力革命。而这必将深入影响电商、内容、游戏、云计算、企业服务等众多领域。
但是语言文字信息没有显式的结构化,其中还有大量的语言学问题,可以说是非常的复杂。也是在相当长时间里,NLP 领域企图完全解构人类的语言文字的所有细节,以期建立起一套理论,就像数学一样,能够精准描述我们在语言文字中显式、隐式包含的信息。这就是人工智能领域的符号主义(Symbolism)路线,它期望通过「知其所以然」,进而「知其然」。
而另一个路线则是希望机器像人类一样,给机器灌输一些文本信息后,机器能够自己抽取其中的特征信息,学会语言文字背后的知识。这一体系整体都基于人工神经网络(Artificial Neural Networks),将多个神经网络层以某种机制连接起来形成一套架构,每层神经网络中又包含数据的输入、输出、对输入的处理方法、处理这些数据所用到的大量参数。这就是人工智能领域的连结主义(Connectionism)路线,它期望先让机器「知其然」,「所以然」这个问题以后再说。连结主义的底层逻辑是经验主义,其交付物是一大堆参数,但是 it works!这是典型的实验科学,如果 AI 的驱动是工业应用的话,这条路线的上游学术研究会被下游的「it works」驱动着跑起来。
那么下游的任务都有什么呢?
1.1、相当长时间里,NLP 领域都有大量细分任务
由于 NLP 领域面对的问题太过庞杂,因此前面很多年 NLP 领域任务都被拆分的非常细,比如(下列任务大家看个感觉就好,暂时不搞懂细节不影响理解):
- 命名实体识别(Named Entity Recognition,NER):比如对于输入语句「擎天柱回到赛博坦」得到输出「B-PER, I-PER, E-PER, O, O, B-LOC, I-LOC, E-LOC」,其中 B、I、E 分别表示开始、中间、结束,PER、LOC 分别表示人物、地点,O 表示其他无关。
- 文本蕴含(Text Entailment):比如对于文本 T「我在杭州」和如下三个假设 H1「我在浙江」、H2「我在上海」、H3「我是杭州人」之间的蕴含关系就是 Positive、Negative、Neutral,其实是个三分类问题。
- 常识推理(Common Sense Reasoning):比如一个测试 LM 是否具备常识推理的例子,在句子 A「奖杯无法放进到箱子里,因为它太了」中的「它」指的谁?在句子 B「奖杯无法放进到箱子里,因为它大了」中「它」指的谁?。
- 问答(Question Answering)。
- 词性标注(POS Tagging)。
- 情感分析(Sentiment Analysis,SA)。
- 自然语言推理(Natural Language Inference,NLI)。
- 总结摘要(Summarization)。
- ……
太多细分任务了,这里不一一举例。每个任务也自然有它的测试数据集,由研究人员开发出新的任务解法(可能是模型创新,也可能是训练方法创新,甚至是一些小 tricks)后去「打榜」,也就是检验下目标任务在测试数据集上的表现如何。下面我引用《A Comprehensive Survey on Pretrained Foundation Models: A History from BERT to ChatGPT》一文中对 NLP 领域数据集的汇总。

1.2、我们始终在追求简洁优雅的技术路线/技术理论
对于上面那么多 NLP 任务类型,大致上我们可以把自然语言处理,分成自然语言理解(Natural Language Understanding,NLU)和自然语言生成(Natural Language Generation,NLG)两大类,而 NLU 任务都要输出判断作为结果,离散的判断就是分类(Classification)问题,连续的判断就是回归(Regression)问题,但是回归问题最终也基本会转换为分类问题。因此可以说 NLP 领域的任务主要就是分类、生成。
- 分类任务(Classification Tasks)更进一步细分,比如包括情感分析(Sentiment Analysis,SA)、命令实体识别(Named Entity Recognition,NER)、自然语言推理(Natural Language Inference,NLI)、文本蕴含(Text Entailment)、词性标注(POS Tagging)、常识推理(Common Sense Reasoning)等等。
- 生成任务(Generation Tasks)更进一步细分,比如包括摘要(Summarization)、机器翻译(Machine Translation)等等。
一方面,这里很多任务,其实都不是最终任务,而属于中间任务。什么叫中间任务?就是为了完成现实中生产生活中的某项任务,而根据某种问题解决方法拆解出来的某个过程目标下的任务。NER、POS Tagging 等等都属于中间任务。从技术的优雅发展角度看,我们希望这些繁杂的技术路线都被替代掉。
另一方面,即使是分类任务,最终也要有输出。那么如果对分类任务做一些改造,其输出就是另一种形式的「生成」。本篇会提到的 T5 模型在这条路线上的研究领域具有关键意义。
所以回到本篇开头处的探讨,既然高等文明的各项成功都建立在语言文字诞生的基础上,那么回归我们的直觉,机器在交互形式层面,如果能对语言文字进行听说读写,也就能达到人类对自然语言处理领域的终极诉求。听和读是输入,说和写是输出。说和写就对应着文本生成,而能「正确地」说和写就意味着已经能「正确地」听和读了,那从这个意义上说,自然语言处理是不是就等价于文本生成问题?
是这样吗?从近几年大型语言模型(Large Language Model,LLM)一路走过来看,似乎是这样。看过《船涨:LLM 革命前夜》文章的朋友们应该还记得,在连结主义的路线上,人工神经网络的基础模型架构是如何从统计语言模型(Statistical Language Models)发展为神经语言模型(Neural Language Models),并在神经语言模型的道路上经历了从 MLP 到最终 Transformer 的迭代演化。Transformer 问世后几乎统一了 NLP 领域的基础模型架构,而一代又一代的模型在这几年时间里大爆发,向通用人工智能(Artificial General Intelligence)方向加速推进了 NLP 的进程,直到大家觉得几乎要逼近奇点的 ChatGPT 出现。这过程中,解决 NLP 问题的技术思路是怎么发展过来的?
已经说了「要解决什么问题」,所以接下来我们要开始探讨下「解决问题的思路」。既然沿着连结主义的人工神经网络往前走,回忆下《船涨:LLM 革命前夜》中我们提到的神经网络的基本研究范式。先要把文本转换为一组组的数字(文本表示,Word Representation),再由计算机寻找这些数字之间潜在关联(特征抽取,Feature Extraction)去优化参数(训练,Training)得到一个模型,然后就可以用它处理任务了。因此概括起来,解决问题的思路就变成了如何设计模型架构、设计学习方法。
- 模型架构(Model Architecture)的设计:这包括如何表示文本、抽取文本特征、以及围绕特征抽取对输入/输出的各种处理方法。
- 学习方法(Learning Methods)的设计:这包括优化目标函数的选定、训练数据的预处理、训练方法设计。
这两个问题是相互交织在一起的。整体上 2017 年后的主流模型基本都以 Transformer 为基础架构做变体,但是模型如何学习则经历了很大的范式转换。
第 2 节 · 解决问题的思路之方法:神经网络模型学习方法的三个范式阶段
如果你了解前篇《船涨:LLM 革命前夜》的 2.7 节中的「简述如何训练一个神经网络模型」的话,下面我们可以看下基于此,NLP 领域在几个阶段的不同学习范式。
卡耐基梅隆大学几位学者在 2021 年的论文《Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing》中对 NLP 领域到那个时间点的学习范式演进做了总结,我在其基础上做了一些修改,写一下我自己的理解。
2.1、第一阶段:完全监督学习(Fully Supervised Learning)范式
先了解下什么是监督学习(Supervised Learning for NLP)。拿「英语翻译成中文」这个机器翻译任务举例,最容易想到的就是如果我们知道很多正确的「输入的英语 x,对应的翻译中文 y」,其中 y 一般叫做输入数据的标签(label)。我们就可以让模型去学习一组$\left(x_i, y_i\right)_{i=1}^n$这样的数据,来训练好模型中的所有参数。然后在使用模型时,直接面向目标任务的英文输入 x 通过模型输出中文翻译。这种输入数据有标签的方法就叫监督学习,而标签是需要人工标注的。
这里顺便提一下,既然有监督学习,相应地还有:1)非监督学习(Unsupervised Learning),训练使用的输入数据是没有标记的;2)半监督学习(Semi-Supervised Learning),则是用少量有标记的数据和大量无标记的数据训练模型;3)自监督学习(Self-Supervised Learning)则是训练所用的数据虽然没有标记,但是可以被模型生成标记,一般采用自监督学习的典型 NLP 任务是语言建模。
早期的 NLP 模型还是统计模型时就有监督学习方法,那时很重要的一个环节是研究人员要自己定义特征模板,进而抽取特征。后来神经网络出现后,通过 MLP、CNN、RNN、LSTM、Transformer 等都可以通过训练自己的过程就顺便又比较黑盒地抽取了特征。
这样完全监督学习大概也分成两个「子阶段」,其时间和核心工作如下:
- 非神经网络的完全监督学习(Fully Supervised Learning base on Non-Neural Networks),大概在 2011 年之前,核心工作则聚焦在了特征工程(Feature Engineering)。
- 基于神经网络的完全监督学习(Fully Supervised Learning base on Neural Networks),大概在 2011-2017 年间,这一阶段,我们把特征抽取这件事儿交给了模型自己(它的特征工程能力已远超人类),而核心工作变成了如何设计、优化出适合目标任务的模型架构,这其实是相对宏观地来调节特征抽取,例如 MLP、CNN、RNN、LSTM 等基础模型被提出,都有其各自特点适应不同的任务。
2.2、第二阶段:预训练(Pre-train)范式 —— 为了更好的泛化性(Generalization)
完全监督学习的范式非常不优雅,一方面上游标注数据难搞(记作「短板一」),另一方面因为针对特定任务训练,所以下游使用时只能对特定任务起作用(记作「短板二」)。这两个显著的短板,引出下面几个研究的技术路线,跟船涨一起从逻辑上来理解一下。
思路一:构建 NLP 自己的 ImageNet。针对「短板一」是比较为难的,因为自然语言处理 (NLP) 的最大挑战之一就是训练标注数据的匮乏,这与计算机视觉(CV)领域形成鲜明对比。由于 NLP 任务的多元化,因此研究人员都在面向不同任务领域,各领域也只能有各自的、围绕目标任务的标记数据,很难全领域形成合力构筑统一的、海量的训练标记数据。然而,近些年 NLP 深度学习发展到了比拼大模型的阶段,这些大模型对有标注的大数据量有极度的渴求。填补这个 GAP 的其中一种思路就出现了:搞个 NLP 人的 ImageNet。ImageNet 是包含了超过 1400 万张手动标注图像、涵盖 2 万多个类别的大型图像数据库,这一直让 NLP 领域研究人员非常羡慕搞 CV 的,这些年围绕「NLP 的 ImageNet 时刻到来」的说法不少,也有不少相关研究是朝这个方向努力,但其实一直无法真正和 ImageNet 相提并论。
思路二:设计一套免标注的训练方法。仍然是沿着上面这个问题,但是填补这个 GAP 的想法是,能否搞出一套无标注数据(或者是少量标注数据)也能训练的方法。
思路三:上游学习,下游迁移。针对「短板二」,针对特定任务训练的模型,泛化性都很差。那么能否把针对 $\operatorname{Task}_1$任务训练出的模型 MM,用一些办法迁移到 $\operatorname{Task}_2$上也能跑呢?所以就有了「迁移学习(Transfer Learning)」。
思路四:上游多任务学习。在迁移学习的路线里,还延伸出一个思路,就是不要模型都训练好了再去迁移,而是一开始训练的时候,就让模型 $M$ 对 $\operatorname{Task}_1$、$\operatorname{Task}_2$ 甚至到 $\operatorname{Task}_n$ 一起训练,训练好后再去使用。这种方法就叫「多任务学习(Multi-Task Learning)」。
2.2.1、这四个思路的交汇点:「预训练-微调」学习范式
本小节标题已经剧透了答案,但我们还是按照逻辑思路理一下。上船!
我们先看「思路三」和「思路四」。两个思路都是把学习过程分成了两个阶段,三是希望学过某个任务的模型,下游稍微调整一下(也要更新模型参数)后也会解决另一个任务。但四是对三的进一步发展,希望上游学过一堆任务后,下游最好能经过一些调整能解决任何 NLP 任务。这样的两阶段学学习方法,第一阶段叫「预训练(Pre-train)」,第二阶段叫「微调(Fine-tune)」。
我们再说「思路二」,免除大量标注工作就能训练模型,NLP 里什么任务具备这个特点呢?就是文本生成任务,人类有海量的文本预料拿来把任意一段话、一句话做截断,前面部分就是$x$,后面部分就是$y$,天然可以作为文本生成的训练数据。这样在语料库中自己构建标记数据的方法,叫「自监督学习(Self-Supervised Learning)」,后面要讲到的 GPT-1 就是这样做的。但是这样是不是只能解决「文本生成」任务?这就与我们前面在 1.2 节聊到的话题对上了,第二章开始讲的模型发展一直到 Google T5 提出的文本生成统一 NLP 任务,就是在回答这个问题。
最后看下,如果沿着「思路一」搞下去,先说结论,应该不是做出一个类似 ImageNet 的什么 WordNet、TextNet 之类的数据库,而应该是语言建模。我们想一下,人类对图像、文本的理解使用是不同的。对于图像,与具备视觉感受器的生物的原始本能有关,认出它是啥是人类最朴素的目的,然后用于人脸识别、道路标记识别等等,核心是一种「识别」能力。而对于文本,根据不同输入目的,给予不同的输出反馈,例如分类、总结、回答等等,核心是一种「对话」能力。所以对于「聚焦识别」的 CV 领域,构建一个识别好(即标注好)的数据库 ImageNet 是好的解法,而不会去构建一个「人来发图、AI 回复个图」的「斗图对话」系统,或者基于其他什么核心能力的系统;而对于「聚焦对话」的 NLP 领域,构建一个识别好的文本数据库并非好的解法,这个数据库离最终任务距离还很远,而需要的是一个「能对话」的文本系统,所以用「语言建模」作为任务训练模型,然后下游再执行具体任务,这样的方法被提出并验证效果不错,此后逐渐成为预训练的基本范式。
四个思路所提出的问题和逻辑推演,都 make sense 的话,这些就引导者学界和业界的人们走向了同一个方向:分「预训练-微调」两阶段的训练方法,且预训练阶段的任务是语言建模。
- 预训练-微调(Pre-train and Fine-tune)学习范式:具体说应该是「语言建模预训练-微调(Pre-train LM and Fine-tune)」范式。一方面以 word2vec、GloVe 等一系列文本表示方法在推动「预训练」先用文本表示做语言建模,这是一股力量,ELMo 在 2018 年的出现是这种思路发展的一个巅峰;另一方面 2017 年出现的 Transformer 能够极强地抽取文本特征进而更好地通过语言建模完成预训练,GPT-1、BERT 等模型都是典型代表,尤其 BERT 把这种范式下的 NLP 研究推向了一个高潮,下面我在本篇第 7 节 BERT 部分会详细讲解。因此这种范式大概从 2017 年开始盛行,要注意微调本身也是一个训练过程,需要更新模型参数。这个阶段的重要研究工作,在于下游微调任务的目标优化,
因为语言建模的任务边界非常模糊,因为你很难孤立地用某一个语料集,说它训练后就是完备的,不需要任何其他语料补充。要实现一个使用体验较好的语言建模,需要的语料库是很大的,相应地,构建出来的语言模型的参数规模也要很大才能体现出语料库大的优势。因此,大语言模型(Large Language Models,LLM)就是在这一阶段被提出的。
2.2.2、解决 LLM 微调成本高的问题:「预训练-提示」学习范式
LLM 模型参数规模非常大,以大家熟悉的 2020 年出现的 GPT-3 为例,模型参数就达到了 1750 亿个。这样下游再去「微调」时,针对一个特定任务,都要更新一个巨大的模型,成本就有点高了。变相地拉高了「预训练-微调」范式的泛化成本。
如果面对下游任务时,不用更新参数就好了 —— 也就是预训练之后不用微调。能实现吗?2018、2019 年在这方面的探索蛮多的,例如 Salesforce Research 在 2018 年 6 月、DeepMind 在 2019 年 1 月、OpenAI 在 2019 年 2 月 都提出了这方面类似的论断:语言模型应该可以解决一切文本任务。船涨会在本篇第 8 节 GPT-2 部分重点讲到。这里隐含着语言模型从大量语料里「隐式地」学到了很多任务该怎么做。既然学到了,下游可能就不用微调了,但是你可能需要给出一些「显式」的提醒来唤醒模型学到的「隐式」任务概念,这就是预训练范式下的第二个阶段:
- 预训练-提示(Pre-train and Prompt)学习范式:同样也可以具体说成是「语言建模预训练 - 提示」范式,举例来说比如你在使用模型时输入「北京,中国;纽约,美国;大阪,日本;悉尼,XXX。XXX 应该是什么?」,模型输出「澳大利亚」,这个输入的部分就是「提示(Prompt)」。Prompt 与 Fine-tune 最大的区别,是 Prompt 是不更新模型参数的,这是一种「上下文学习(In-Context Learning,ICL)」能力,这是一个非常重要的议题,因此本篇第四章将用一整章来探讨 ICL。
这样就从让预训练模型经过「微调」的笨重方式去缩短与下游任务距离的范式,切换到了让下游任务经过「提示」的轻便方式去缩短与预训练模型的距离。
这个「预训练-提示」范式以 2019 年登场的 GPT-2 模型开始为代表,到 GPT-3 推出后被推向了顶峰,尤其到了 2021 年,甚至衍生出了「提示工程(Prompt Engineering)」。围绕于此的研究论文也井喷式出现(下图引用自 pretrain.nlpedit.ai):

2.2.3、特定领域的更优解:「预训练-微调-提示」学习范式
对于现实中特定领域的实际应用来说,比如法律、客服、医疗等领域,在「预训练-提示」的范式上也加上针对特定领域的一些训练数据来微调,应用效果会更进一步提高,因此也出现了这样的范式:
- 预训练-微调-提示(Pre-train, Fine-tune and Prompt)学习范式:OpenAI 在开放 GPT-3 API 后,也推出了 fine-tune 的 API,不过后者价格就贵多了,而且把 fine-tune、使用两个环节分开收费,具体费用汇总可以看《AI 应用第一次大爆发来了:一文入门 ChatGPT 官方 API 文档解读》第一部分的第 5 小节「定价」。
虽然会有上面说的「微调 LLM 成本高」的问题,但是对于商业化的应用领域,LLM 带来的 AI 性能显著提升,是值得用微调成本换取商业收益的,而且通常这些领域还有私有数据授权的问题,比如 2023 年 3 月 Meta 放出 LLaMA 并提供预训练好的模型下载后,业界很多人在其上开始使用自己的商业敏感数据进行微调再提供服务。
2.3、第三阶段:「预训练-人工反馈强化学习-提示(Pre-train, RLHF and Prompt)」学习范式
发展到「预训练」范式阶段,还有什么显而易见的问题?第一是预训练语言模型对数据、模型、算力的要求都太高了,就像当年计算机刚出来时候占满一栋楼一样。第二是 LLM 没有与人类的价值观、道德伦理等方面对齐,存在风险,因此需要推进 helpful、harmless、honest 的模型出现,这就是「对齐(Alignment)」议题。
由于 LLM 能力太强,因此带来的负面影响亟需兜底策略,否则可能会对人工智能领域发展带来毁灭式的巨大风险,所以对齐问题的优先级从「预训练」范式蓬勃发展后就变得异常之高,也就引出了第三阶段的范式。而第二阶段的范式热潮几乎一直延续到现在(本篇初步成文于 2023 年 1 月春节期间,后又做内容补充发表),但是与之交叠在一起出现的新范式是 2022 上半年,在「预训练-提示」的基础上增加了「人工反馈强化学习」来通过人工干预解决对齐问题,主流模型里 InstructGPT 是率先这样训练的,我会在本篇的第 18 节 InstructGPT 部分详细介绍对齐相关议题。这里我们继续讨论范式。
先了解下什么是「强化学习(Reinforcement Learning)」。强化学习就类似人类的考试,是有一套标准答案(叫 「奖励模型(Reward Model)」来评判 AI 学习效果的。监督学习在训练时,是模型针对 x 给出的输出值被拿去与标签 y 对比计算损失,进而优化模型参数;而强化学习在训练时,是模型针对 x 给出的输出被拿去由环境反馈评价,进而优化模型参数。
要将人的伦理道德观念注入给 LLM,所以强化学习中的环境反馈就是「人工反馈」了,因此「人工反馈的强化学习(Reinforcement Learning with Human Feedback,RLHF)」被引入「预训练-提示」范式中,变成了:
- 预训练-人工反馈强化学习-提示(Pre-train, RLHF and Prompt)学习范式:RLHF 方法最早由 OpenAI 在 2017 年论文《Deep reinforcement learning from human preferences》中提出,后来 GPT-2、GPT-3 相继发布后出现了虚假新闻、教唆犯罪、消极暗示等大量使用 GPT 系列的负面案例,于是 OpenAI 开始重视 Alignment 并最终在 2022 年上半年的 InstructGPT 上引入 RLHF 方法对齐人类道德伦理,起到很好的效果,后来这也被迭代回了 GPT-3 中以保障 API 调用时遵循人类道德伦理观念。这套范式也被用于大家熟悉的 ChatGPT 中,成为了目前的主流范式。
与第二阶段类似的,对于特定领域应用,也可以下游的 fine-tune,以期进一步提升效果,即如下范式:
- 预训练-人工反馈强化学习-微调-提示(Pre-train, RLHF, Fine-tune and Prompt)学习范式:预训练-人工反馈强化学习,都是上游阶段,微调和提示属于下游阶段。目前提供 fine-tune 的 GPT API 背后的 GPT 模型也是有 RLHF 的,已经不是最初没有考虑 alignment 的 GPT 版本了。可以看到 GPT 官方 API 文档中有 Moderation API
第 3 节 · 解决问题的思路之模型:初识预训练语言模型
语言模型(Language Model)就是词序列的概率分布,因为在给定词序列后能预测下一个词,所以语言模型本身任务就是文本生成。按照技术路线,可以分为统计语言模型(Statistical Language Model)和神经语言模型(Neural Language Model)。《船涨:LLM 革命前夜》中提到的 N 元文法就属于统计语言模型,MLP、CNN、RNN、LSTM、Transformer 等等都属于神经语言模型。
本篇第 3 节提到,从第二阶段的「预训练」范式成为主流开始一直到当下,NLP 领域在模型架构上的探讨,就变成了如何打造一个更强有力抽取语言特征并生成文本的语言模型问题。目前主流语言模型已经全面拥抱 Transformer,甚至可以说 NLP 乃至很多其他 AI 领域也都拥抱了 Transformer。Transformer 变体而来的语言模型,有如下这几类(下图引用自 Liu et al., 2021)。

有些文献里,比如 Google 的 T5 论文中(Raffel et al. 2019)没有把 Masked LM(或叫 Auto-Encoding LM)看做语言模型,只把最后有自左向右根据 x 输出 y 的当做了语言模型,从这点上说其他三个模型从右侧看都是这样。
自回归语言模型(Auto-Regressive Language Models)也被一些文献叫做「从左到右语言模型(Left-to-Right LM)」会用已生成的预测结果做后续新的预测,简单说就是「Guess the Next」,然后把生成的词再放回到输入里组成新的输入继续 Guess the Next,从而使模型的注意力都集中在前面的文本上,从注意力机制上说就是 Casual Multi-Head Self-Attention。TransformerXL、XLNet、OpenAI 的 GPT 系列都属于自回归模型。自回归模型需要学习各词、各词组的文本内部依赖关系。从自回归模型的定义你可以看出,文本生成就是一个典型的要使用自回归模型的任务。曾经一度 NLP 领域还会像上面那样把文本拆分的很细,在所有任务都可以转换成文本生成文本任务的思想统一 NLP 江湖后,你就知道自回归模型其实有着最强大的潜力。
The way Auto-Regression Models actually work is that after each token is produced, that token is added to the sequence of inputs. And that new sequence becomes the input to the model in its next step. This is an idea called “Auto-Regression”. —— Cited from jalammar.github.io
自编码语言模型(Auto-Encoding Language Models)是通过破坏文本再尝试恢复来学习语言的,简单说就是「完形填空」,会用掩码(Mask,跟计算机网络里说的掩码是一回事儿)挖掉训练预测的词,所以涉及到怎么挖(破坏方法 Corruption)、挖多少(破坏比率 Corruption Rate)、挖多长(破坏长度 Corruption Length),对这类 Corruption 的实验可以看本文 T5 模型的第 3 小节。也因此这类模型也叫 掩码语言模型(Masked Language Models,MLM),或者掩蔽语言模型。从注意力机制上说,是 Masked Multi-Head Self-Attention。相比自回归模型,自编码模型的学习过程,能看到待预测词的前后内容,所以对文本的理解是更深入的,在同等成本的情况下理论上自编码模型对文本的分类、回归方面的 NLU 问题会有更好性能表现。典型的自编码模型有 BERT、ERNIE、ALBERT、RoBERTa、DistilBERT、ConvBERT、XLM、XLM-RoBERTa、FlauBERT、ELECTRA、Funnel Transformer。
前缀语言模型(Prefix LM):也算是 Left-to-Right 模式的,但是与自回归语言模型相比,前缀语言模型在抽取输入文本特征时用了 Fully-Visible Mask(Encoder 用的掩码,能看到「过去」和「未来」)而不是 Future Mask(Decoder 用的掩码,只能看到「过去」),而生成本文部分则与自回归语言模型一样,只看到左侧。从注意力机制上讲,用到了 Masked Multi-Head Self-Attention 和 Casual Multi-Head Self-Attention。采用此架构的模型有 UniLM(Dong et al., 2019)、UniLMv2(Bao et al., 2020)、ERNIE-M(Ouyang et al., 2020)。
编码器-解码器语言模型(Encoder-Decoder LM)是把 Transformer 的 Encoder 和 Decoder 都包括在内。其注意力机制,Encoder 部分是 Masked Multi-Head Self-Attention,Decoder 部分是 Casual Multi-Head Cross-Attention 和 Casual Multi-Head Self-Attention 兼具。典型的 Encoder-Decoder 语言模型有 BART(Lewis et al., 2020a)、T5(Raffel et al, 2020)、MASS(Song et al., 2019)。
本小节参考
- https://arxiv.org/abs/2107.13586
- https://zhuanlan.zhihu.com/p/395115779
- http://pretrain.nlpedia.ai
- https://arxiv.org/abs/1905.02450
- http://pretrain.nlpedia.ai/data/pdf/plm.pdf
- https://lifearchitect.ai/chatgpt/
- https://huggingface.co/docs/transformers/model_summary
- https://zhuanlan.zhihu.com/p/608047052
- https://arxiv.org/abs/1905.03197
- https://arxiv.org/abs/2002.12804
- https://zhuanlan.zhihu.com/p/424631681
- https://arxiv.org/abs/1910.10683
- https://zhuanlan.zhihu.com/p/198964217
- https://arxiv.org/abs/1910.13461
- https://zhuanlan.zhihu.com/p/395115779
- https://web.stanford.edu/class/archive/cs/cs224n/cs224n.1184/lectures/lecture17.pdf
- https://speech.ee.ntu.edu.tw/~hylee/ml/2021-spring.php
- https://arxiv.org/abs/1301.3781
- https://arxiv.org/abs/2012.15674
第二章 · LLM 关键发展节点与主流模型(2018 - 2021)
第 4 节 · Transformer(2017 年 6 月)
船涨在《船涨:LLM 革命前夜》中讲述了 NLP 领域基础模型如何发展出 Transformer 的。Transformer 最初只不过想解决机器翻译问题,输入 A 语言的文本序列,输出 B 语言的文本序列,但其强大的能力让其几乎正在统一 AI 个研究领域。Transformer 模型的最大亮点有两方面:
- 特征提取能力强:捕获更大范围内的语言结构(Capture longer range linguistic structure)。
- 非常好的并行性。
Transformer 由 Encoder 和 Decoder 组成,其诞生之后各主流语言模型要么基于 Encoder,大致结构示意如下:

要么基于 Decoder,大致结构示意如下:

要么基于 Encoder 和 Decoder 整体,比如 Google 推出的 T5。如果想搞懂 Transformer Encoder-Decoder 结构再继续阅读本文的话,建议先看《船涨:LLM 革命前夜》。如果你已经大致了解了,后续提到 Encoder、Decoder 部分则不会有疑问,请跟随船涨继续下去啦。
第 5 节 · ELMo:词所在的上下文很重要(2018 年 2 月)

尽管在 2017 年的 Transformer 之后第一个在 NLP 圈子里爆火的模型是 ELMo,但它并不是基于 Transformer 架构。甚至现在回头看它的核心价值都不是完成目标任务方面的出色程度,而是词的表示(Word Presentation),但它对于双向语言模型、词向量等的后续发展都产生了很大影响。
需要提一下的是,ELMo 的作者们在 2017 年时提出过「TagLM」模型,其思路在 ELMo 推出后回头来看算是一个过渡阶段的思考方案,ELMo 对其思路方向是一个完善。这一阶段的一系列模型(TagLM、ELMo、ULMFiT 等),概括起来都是在从 Word Embeddings 升级为更先进的 Embeddings。
我们还是重点讲解下最受认可且结构简单清爽的 ELMo 语言模型,先看下 ELMo 解决的最核心问题:一词多义。
5.1、一词多义问题
无论是 word2vec 还是 GloVe,对于多义词始终没有处理好。这些词嵌入(Word Embeddings)方法都是在语料库中词之间的共现(co-occurrence)统计进行预训练的。比如下面这个例子中,king 和 queen 就会得到完全一样的 word embedding:

尽管这被 GloVe 方法考虑更大范围词频共现后一定程度解决了(没有完全解决)。然而另外一个问题才是最致命的,就是对任何一个词,这类方法都是采用固定的向量,完全没有考虑上下文语境 —— 换句话说,一词多义问题无法解决,比如:

那为什么不考虑上下文呢?实际上,到 2018 年初那个时间点,主流的语言模型基本都只看单向的上下文,即上文(Left Context)或者下文(Right Context)。这与人类在自然语言理解(Natural Language Understanding,NLU)上的真正方式 —— 上下文双向理解 —— 是不一样的。于是很自然的问题就是,实现一个双向的语言模型呀?那为什么一直到 2018 年语言模型还都是单向的?
5.2、See-Themselves 问题
BERT 作者 Jacob Devlin 总结过「到 2018 年时为什么主流语言模型一直未出现双向」的原因:
Words can “see themselves”.
这个问题就是 See-Themselve 问题,也被一些人叫做 See-Itself 问题,就是在预训练的词向量生成过程中,当学习输入的文本语料时,其中已经包含了自己,则在词表示上形成了递归,如下图则是对这个问题的抽象表示(左侧是单向 LM,右侧是双向 LM):

简单地说,存在标签泄露问题
那么是否存在可以解决 See-Themselves 问题的双向模型呢?
5.3、ELMo:基于两个单向 LSTM 的语言模型
2018 年 2 月 AI2(Allan Institution for AI)在论文《Deep contextualized word representations》中提出了 ELMo 模型。该论文同时被 ICLR、NAACL 接受,并获得 NAACL 最佳论文奖。ELMo 是「Embeddings from Language Model」的意思,也是呼应美国知名儿童电视节目《芝麻街》里的角色 Elmo,这样给模型起名是比较容易口口相传的。
ELMo 会根据上下文信息给一个词编码出一个词向量。这样类似下面的 bank 在两个句子中含义不同,则有不同的词向量:

这样的词表示方法在《Linguistic Knowledge and Transferability of Contextual Representations》中被称为「Contextual Word Representations,CWRs」,后来出现的 GPT、BERT 也都是用关注上下文的方法做词表示(只不过关注的范围有差异),到 2023 年初我写文本的当下,关注上下文的词表示法已经是共识(从语言学上,向这个方向演化也是对的)。
本节要介绍的这个 ELMo 模型,在解决了一词多义问题的同时,也避开了 See-Themselves 问题。如本小节的剧透,ELMo 用了 BiLSTM(快速了解 BiLSTM,看《人工智能 LLM 革命前夜:一文读懂横扫自然语言处理的 Transformer 模型》这篇文章的 4.4、4.5 节)。其结构很好理解,对于任何一个输入文本,用一个 Left-to-Right 的单向 LSTM 模型和一个 Right-to-Left 的单向 LSTM 模型,从而避免了「See-Themselves」问题,如下所示:

这样每个词的词向量表示都考虑了上下文。这样用 ELMo 得到的文本词向量作为预训练词嵌入(Pre-trained Embeddings),可以作为词嵌入输入给其他流行的模型架构:

下面是一个 ELMo 执行文本预测任务的过程,以此来说明 ELMo 的模型结构(这里只展示了 Left-to-Right 单向 LSTM 部分,Right-to-Left 与之相似略去):对输入文本先 Word Embedding 提取单词特征,然后经过两层 LSTM,研究表名第一层 LSTM 能够捕获句法特征,第二层 LSTM 能够提取到语义特征。最后到输出层(FFNN 前馈神经网络 + Softmax 回归,这两个概念也在船涨的《人工智能 LLM 革命前夜:一文读懂横扫自然语言处理的 Transformer 模型》的 2.8、2.5 中有简洁讲述)得到预测概率最高的词。

更详细地结构描述中,补充一点,即在 ELMo 的第一第二层之间,还有一个 ResNet(ResNet 的快速了解可参考船涨上一篇《人工智能 LLM 革命前夜:一文读懂横扫自然语言处理的 Transformer 模型》)的第 9 节),这样可以增加模型的稳定性。
5.4、ELMo 训练及使用
第一阶段是预训练,就是灌入大量语料给 ELMo,目标是构建语言模型。首先是对输入词的 Embedding,然后经过两层 LSTM,分别提取目标词的 Context-Before 和 Context-After 的特征,之后输出层的细节就不展开了。剩下的就是神经网络基本的反向传播、梯度更新、优化目标函数。预训练结束后我们就得到了一个 ELMo,其包含大量被预训练好的参数,等待用于下游任务。
第二阶段是下游任务使用。一个具体的下游任务的输入 X,经过第一步预训练好的 ELMo 得到 Pre-trained Embeddings 作为新的输入,给到下游任务模型。因此新的输入 Pre-trained Embeddings 比只是 Word Embeddings 要提取了更多特征,所以第一步的这种预训练也叫 Feature-based Pre-training。
5.5、双向语言模型,是灯塔吗?
尽管 AI2 官方称,ELMo 在问答(Question Answering,QA)、文本蕴含(Textual Entailment,TE)、情感分析(sentiment analysis)三类 NLP 任务上取得 SOTA。但是我们回顾下本节前面提到的:
在 2018 年初那个时间点,主流的语言模型基本都只看单向的上下文,即上文(Left Context)或者下文(Right Context)。这与人类在自然语言理解(Natural Language Understanding,NLU)上的真正方式 —— 上下文双向理解 —— 是不一样的。
注意这里提到的是 NLU,不是 NLG。对于 NLU,我们在处理文本内容时,通常都是通过上下文来理解的(双向)。而对于 NLG,通常通过上文来影响下文(单向)。但是从自然语言的任务角度说,NLU 和 NLG 其实并没有明显的界限。一个 NLU 任务,最终也要有输出,那么这类任务就可以对输入进行改造变成 NLG 的「形式」。这里先按下不表,在下面 T5 模型时我们会再次提到。
所以双向语言模型是灯塔吗?上下文一定要都知道才对吗?更具体地说,Left-to-Right 和 Right-to-Left 都要兼顾到的模型才是唯一正确的方向吗?我们继续往下把本章看完再讨论这个话题。
5.6、ELMo 的局限性
在 2018 年 Transformer 已经发布并引起普遍关注的情况下,ELMo 依然选择了基于 LSTM 的架构。因此要讲 ELMo 的局限性,其实主要就是这个视角。相比这一点,对其训练方法、数据集等等的关注显得避重就轻了。所以以下说两点:
- LSTM 特征提取能力的局限:尽管 ELMo 在特征提取上,已经显著优于此前仅依靠 Word Embedding 方法的 word2vec、GloVe 等。但是回头看,后续一系列 Transformer 架构之上的模型表现,都远优于 LSTM 架构的模型,两者的特征抽取能力差距显著。也是因为 Transformer 如此的优秀,后续基本统一了 NLP 的技术路线。
- 双向 LSTM 拼接的局限:EMLo 采用了双向模型,但是没有采用 Transformer Encoder 的架构,而是用双向 LSTM 拼接的方式,相比 Transformer 效果要差。
本小节参考
- https://allenai.org/allennlp/software/elmo
- https://jalammar.github.io/illustrated-bert/
- https://arxiv.org/abs/1802.05365
- https://nlp.stanford.edu/seminar/details/jdevlin.pdf
- https://zhuanlan.zhihu.com/p/51679783
- https://arxiv.org/abs/1903.08855
- https://zhuanlan.zhihu.com/p/72839501
- https://www.jianshu.com/p/81dddec296fa
第 6 节 · GPT(2018 年 6 月)

由于 GPT 系列模型已经成为当下阶段 LLM 领域的绝对领导者,因此本文中关于 GPT 系列的每个模型细节的着墨都会稍多一些。
6.1、GPT 出现的背景:监督学习模型为主,但标注和泛化成为卡点
在介绍 GPT 之前,我们说一下它出现的那个时间点的 NLP 模型发展情况。那时 NLP 领域绝大多数的 SOTA 模型,都是针对特定类型任务进行监督学习训练得到的,而监督学习模型有两个严重的限制:
- 标注成本极高:面对特定任务,需要大量的标注数据用于训练。
- 泛化能力极差:除了训练过的特定任务,模型很难泛化去做其他任务。
这两个问题不解决,AI 技术在 NLP 领域很难带来应用的广泛性,更不要提准确性问题了。但是 GPT 的出现,拉开了 NLP 领域预训练大模型对任务大一统的大幕。而后 T5 模型则明确提出了这个断言,而后续 GPT-3 基本实现了这一点。
OpenAI 官方所称的 GPT,根据其官方定义是 Generative Pre-trained Transformer 缩写,这里大家注意并不是一些文中误传的 Generative Pre-Trained,因为架构的核心理念是 Transformer。
6.2、GPT-1:基于 Transformer Decoder 的自监督训练语言模型
在 2018 年 1 月,Google Brain 团队在文章《Generating Wikipedia by Summarizing Long Sequences》中提出了一种基于 Transformer 改进,但只有 Decoder 架构的模型,也可以用于构建语言模型。相应地,因为没有 Encoder,这种架构里自然去掉了 Decoder 中的 Encoder-Decoder 注意力层。Google AI Language 团队在《Character-Level Language Modeling with Deeper Self-Attention》论文的工作中验证了用类似架构构建的语言模型可以逐一生成词。
OpenAI 在 2018 年 6 月其博客上发布一篇名为《Improving Language Understanding with Unsupervised Learning》的文章提出了一种模型,该模型的打造方法包括生成式预训练(Generative Pre-training)和判别式微调(Discriminative Fine-tuning)两个关键阶段,并在一系列不同语言任务上获得了 SOTA 的结果。其实这种方法,早在 GPT-1 推出几年前在 CV(计算机视觉)领域就已经很主流了,其中预训练环节在 CV 领域用的都是大名鼎鼎的 ImageNet。而因为 NLP 领域没有类似 ImageNet 这种海量标注数据可用。最初,大家甚至不知道该称呼它叫什么,所以那段时间提到它的相关文章里你会看到 Fine-tune Transformer、Fine-tuned Transformer、OpenAI Transformer 等等,后来 GPT-2 推出后,大家也就叫 2018 年这个为 GPT-1 了,下文也用该说法。
GPT-1 与当时主流的 NLP 模型最大的区别是什么?
首先是基础架构(Architecture),与 Google Brain 团队 2018 年 1 月提出的模式一样,下图是 GPT 采用的 Transformer 模型变体,也用的是 Transformer Decoder,同样因为没有 Encoder 自然也就移除了 Encoder-Decoder Attention,而只采用多头自注意力(Multi-Headed Self-Attention,关于此的介绍可见《船涨:LLM 革命前夜》的第 7、8 节),中间的 transformer blocks 一共用了 12 层(作为对比,后续的 GPT-2、GPT-3 分别达到了 48 层、96 层)。

其次是核心方法(Method),GPT-1 采用的是「无监督预训练 + 监督微调」,当时 OpenAI 把这种方法仍然归类为半监督学习,但后来学界和业界都把这种叫做「自监督学习(Self-Supervised Learning)」,后面要介绍的 BERT 也采用这种方法。
关于架构和这两段式的训练方法,我们分四个小节来看下。
6.3、GPT-1 为什么用 Transformer 而不是 LSTM?
回到 2017 年的背景下(虽然是 2018 年初发布,但 GPT-1 的研发是从 2017 年 Transformer 发布后就开始的),哪怕知道 Transformer 是个不错的基础模型,但是当时一个新的语言模型采用 LSTM/RNN 还是 Transformer 并没有现在这么显而易见。为什么选择 Transformer?OpenAI 给出了两个原因。但是船涨认为,按学界的通常情况,都是试出了结果再尝试归因,肯定不是分析出哪个模型更有效然后指哪打哪的。这并非吐槽,因为与理论科学不同,实验科学其实就要这样。
我们来看下 OpenAI 给出的归因。
首先一个原因,是 Transformer 有更结构化的记忆可以处理长距离依赖关系(可以理解为更能搞定长文本),这样就意味着不仅是句子维度,甚至段落维度、文章维度上的信息也可以被 Transformer 学习到。
其次,OpenAI 在做迁移学习的时候,同样不做监督微调的情况下,发现 Transformer 比 LSTM 架构有更好的表现。如下图:

6.4、GPT-1 的无监督预训练(Unsupervised Pre-training)
能用末标注的数据做无监督的预训练,已经很不容易了,尽管 GPT-1 并不是第一个这样做的(2014 年的 Word2Vec 词嵌入模型也是用的大 量无标注文本) 。下面我们来理解一下无监督预训练的过程。 $\mathcal{U}=u_1, \ldots, u_n$ 是一个无监督词序列语料,那么语言模型给出这样一个词序 列的概率是:
如果模型的上下文窗口 (Context Windows) 大小是 $k$ 的话,则上式可近似转化为:
我们的目标就是让这个概率 $P(\mathcal{U})$ 最大化,因此我们定义一下目标,即最大化对数似然函数。再将模型的参数 $\Theta$ 也考虑进来,则其定义如 下:
明确了上面目标函数后,我们来看下 GPT-1 预训练模型。 $U=\left(u_{-k}, \ldots, u_{-1}\right)$ 是考虑了上下文的输入词向量矩阵, $W_e$ 是词嵌入矩阵, $W_p$ 是位置编码(或叫位置嵌入)矩阵。所有隐藏层都是 transformer_block,第一个隐藏层的输入是 $h_0$ ,每 $\mathrm{i}$ 个隐藏层的输出是 $h_i$ 。那么 GPT-1 预训练模型可以表示为:
如果你在《船涨:LLM 革命前夜》中已经理解了位置编码(Positional Encoding),那么在 GPT-1 模型里, $U$ 经过 $W_e$ 处理后每一行就得 到了特征 (特征抽取) 。文本的有序性决定了「位置」本身就是有信息量的,因此垣加 $W_p$ 则保留了位置相关(position-wise)信息。
以最大化 $L_1$ 为目标,经过这样学习大量文本语料后,就得到了一个预训练模型。
6.5、GPT-1 的监督微调(Supervised Fine-Tuning,SFT)
现在我们已经有了一个预训练好的模型了,这一步就是要 fine-tune 它的参数,来适应下游的监督学习任务。对于不同的任务,在 fine-tune 阶段将所有任务的输入结构都转换成 token 序列,喂给已经预训练好的模型来 fine-tune,然后再接一个 linear+softmax。流程结构上表达如下:

设我们有一个标注过的数据集 $\mathcal{C}$ ,组成它的每个样本都包括一个文本序列 $x=x^1, \ldots, x^m$ 和一个标签 $y$ 。微调时,就是把输入 $x$ 经过预训 练模型后在最后一个 Decoder 输出的 $y$ ,进行线性变换和 softmax 回归:
这个过程中,就学习到了 $W_l \in \mathbb{R}^{m \times c}$ 参数矩阵,其中 $c$ 是下游任务目标类别的数量,比如情感分类(positive、neutral、negative)的 $c$ 为 3。在模型使用时,最后得到的 $\operatorname{softmax}\left(y W_y\right)$ 就能得到一组关于目标类别的概率分布了,其中最大的概率值即可看做是结果。
监督微调的目标,也是最大化对数似然函数:
这样整体看,我们把两个训练过程(无监督预训练、监督训练)联合起来。其中在无监督预训练过程中,我们顺手完成了语言建模,它其实相当于我们的一个辅助目标。我们发现这个辅助目标有两个好处:
- 提升了监督模型的泛化能力;
- 加速模型收敛。
这并非 GPT-1 首次提出,此前剑桥大学的 Marek Rei 在 2017 年 4 月 24 日发表的论文《Semi-supervised Multitask Learning for Sequence Labeling》中就得出过同样的结论:
We found that the additional language modeling objective provided consistent performance improvements on every benchmark.
同样在 2017 年,AI2 的 Matthew E. Peters 等四位学者在 4 月 29 日发表的论文《Semi-supervised sequence tagging with bidirectional language models》 中也提到了半监督预训练一个语言模型后在 NER 和 Chunking 数据集上都有显著的表现提升:
In this paper, we proposed a simple and general semi-supervised method using pre-trained neural language models to augment token representations in sequence tagging models. Our method significantly outperforms current state of the art models in two popular datasets for NER and Chunking.
在这样的「无监督预训练 + 监督训练」方法下,目标函数就是最大化下面这个组合 (引入一个 $\lambda$ 超参数控制无监督预训练权重):
以上整个架构与方法,为后来 GPT 的发展确定了基本的模式,甚至包括后来的商业化。OpenAl 在 2020 年 6 月开放了 GPT 的 API (不过 那时候已经不是 GPT-1 了) 后,其实提供的是预训练后的模型,另外还给开发者提供了 SFT 的 API。
6.6、GPT-1 的预训练数据集
在最初 GPT-1 的论文中,对于预训练数据集的来源和内容,只轻描淡写地提了一句:
We use the BooksCorpus dataset of training the language model.
论文中所说的这个 BooksCorpus,其实是把 BookCorpus 拼写错误了。BookCorpus 也被称为 Toronto BookCorpus,是一个包含未出版的、免费的书籍内容的数据集,这些书籍都是来自 SmashWords 电子书网站(这个网站自称是全球最大独立电子书分销商,独立电子书的概念可以类比独立电影、独立游戏)。2018 年 OpenAI 训练 GPT-1 时,OpenAI 称该数据集包含 7000 多本未出版的书籍,4.6 GB 数据。
为什么用未出版的小说书籍训练呢?在船涨的理解里,这是为了在一个相对隔离的数据集上训练,然后在真实世界中我们可能遇到的问题上做测试,这样可以更好地检验模型的泛化能力。因为 BookCorpus 这些书都是未公开的,而且小说又不像其他书籍,理论上构成的语料也都是原创性的,这样就能更好地检验泛化能力。
在 2021 年时,一份对 BookCorpus 当时 11038 本书籍各类目分布的统计分析如下(来自 Alan D. Thompson, March 2022, What’S IN MY AI? ),从这个分布里大概能推测 GPT-1 用其中 7000 本书都学了什么:

6.7、小结
从性能表现上来看,在如下这些数据集上的表现大都是超越此前的模型的:

GPT-1 给 NLP 领域带来了两个重要启示与指引:
- GPT-1 基于 Transformer 架构,不同于当时主流模型采用的 LSTM。具体说,是 Transformer 的 Decoder 部分,并移除 Transformer 定义的 Encoder-Decoder Attention(毕竟没有 Encoder)。这样的架构,先天地可以实现无监督训练,让世界上所有自然语言(甚至代码)都有了成为其语料的可能。
- 尽管并非 GPT-1 首创,但是它采用自监督学习的训练方法,具体是语言建模的无监督预训练 + 监督微调训练,为模型带来了更强的泛化能力、更快的收敛速度。
虽然那个时间点学界与业界觉得 GPT-1 规模不小,但现在回头看它的各维度都还不算暴力。预训练数据量为 4.6GB、上下文滑动窗口为 512 tokens、drop rate 为 0.1,其他基本信息如下:

另外,OpenAI 也公布了 GPT-1 的源码和训练好的模型,那时的 OpenAI 还是很 Open 的。
而就在 OpenAI 发布 GPT-1 后没多久,提出 Transformer 模型的 Google 发布了后来几年产生深远影响的、基于 Transformer Encoder 架构的语言模型 —— BERT。
本小节参考
- https://openai.com/blog/language-unsupervised/
- https://transformer.huggingface.co/doc/gpt
- https://huggingface.co/docs/transformers/model_doc/openai-gpt
- https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
- https://lifearchitect.ai/whats-in-my-ai/
- https://zhuanlan.zhihu.com/p/362929145
- https://medium.com/the-artificial-impostor/notes-improving-language-understanding-by-generative-pre-training-4c9d4214369c
- https://arxiv.org/abs/1705.00108
- https://arxiv.org/abs/1704.07156
第 7 节 · BERT(2018 年 10 月)
OpenAI 发布 GPT-1 后,Google 大受震撼。在其发布 4 个月后的 2018 年 10 月,Google 终于推出了 BERT,它有两个版本 BERT-Base 和 BERT-Large。从性能表现上看,参数规模相当的情况下,BERT-Base 超越 GPT-1,而参数规模更大的 BERT-Large 又远好于 BERT-Base,可以说 Google 又穿上了黄色领骑衫。
BERT 的名字,在船涨看来也是作者们硬凑出来的,就是为了呼应 ELMo 这种芝麻街角色名字系列。BERT 是 Bidirectional Encoder Representations from Transformers 的缩写。下面是 BERT 的基本信息。

BERT 公布了源码和训练好的模型参数供下载。Google 团队希望 BERT 能够让业内人士,用几个小时甚至几十分钟,就能训练好一个 SOTA 小模型。Google 在论文中称可以在 11 个 NLP 任务上取得 SOTA 结果,甚至包括非常挑战的 SQuAD v1.1 数据集。
BERT 发布一年半后的 2020 年 3 Google 又为 BERT 发布了一系列 24 种小模型共各种场景使用,开源精神一直都贯穿在 Google 的技术路线上。这些小模型有不同的层数和自注意力头数,具体如下:

以下阅读前需要你初步了解 Transformer 基本架构。如果你此前不了解 Transformer Encoder、Decoder 的架构特点,可以看《船涨:LLM 革命前夜》中的第二章。
下面我们来看看在 Transformer 模型基础上研发的 BERT 吧。
7.1、BERT 的模型架构:双向
与 GPT 不同,BERT 采用的是 Transformer 的编码器。但是这样在技术路线上选择的分野,带来的影响非常的大。Transformer 的编码器就像完形填空,在预测每个词时,是知道前后(过去和未来)的文本内容的;但是 Transformer 的解码器仅知道前面的文本(过去)来预测词,相当于在预测未来。
在 ELMo 一节我们介绍过双向语言模型,这里将单向与双向作对比,举例来说,对于同一句话「I accessed the bank account」,GPT 单向语言模型的学习方法是:
1 | I -> I accessed |
而 BERT、ELMo 双向语言模型的学习方法是:
1 | I accessed the [MASK] account -> [MASK]=bank |
这里就涉及到两个关键点:首先,上面在 ELMo 提到的,双向语言模型需要解决的「See-Itself 或 See-Themselves」问题。其次,BERT 如何挖词来做完形填空,即 Corruption Technique。
可以说 OpenAI 做了一个价值更大、难度更大的技术选型,因此如果在类似数据规模、模型规模、训练方法的情况下,GPT 是难有超过 BERT 的表现的。BERT 问世后的几年内,学界与业界的很多人都以为 BERT 是一统江湖的正途,甚至都认为 OpenAI 的 GPT 选择错了技术路线还硬着头皮坚持。这与 2022 年底 ChatGPT 彻底轰动世界形成了鲜明的对比。

上图展示了 BERT 与当时另外两大主流 NLP 模型 GPT-1、ELMo 的对比。BERT 与 GPT 的共同点是都基于 Transformer 架构,而 BERT 与 ELMo 的共同点是都用了双向架构。
7.1.1、BERT 是深度双向(Deeply Bidirectional),ELMo 是浅度双向(Shallowly Bidrectional)
由于自注意力层的加持,Transformer 有着极其强大的特征提取能力,这使得 Google 在其官方博客上有底气说 BERT 是深度双向模型,而 ELMo 基于双向 LSTM 提取特征的能力只算是浅度双向模型,提出 ELMo 的 AI2 对此也无法辩驳。
同样基于 Transformer、得益于自注意力,双向模型比单向模型对自然语言有更好的理解,因此在 NLU(Natural Langauge Understanding,NLU)问题上可以轻松取得比单向模型好得多的表现,这也是 GPT-1 相对吃亏的地方。
7.1.2、基于 Transformer Encoder 之上 BERT 做了哪些架构改进
首先是 Input Embedding 处理得到优化,BERT 的 Input Embedding 是三种 Embedding 的求和。

- 单词嵌入(Token Embedding)。
- 位置嵌入(Position Embedding):在 NLP 任务中,词的位置信息非常有影响。
- 片段嵌入(Segment Embedding):或者叫「句子嵌入」,增加对句子结构的理解。
7.2、BERT 的训练方法
BERT 也是采用「无监督预训练 + 监督微调」的方法,与 GPT-1 相同。但毕竟是双向语言模型,BERT 的预训练任务与 GPT-1 不同,有如下两个:Masked Language Modeling(在某些文献中也叫 Mask Language Modeling,MLM)和 Next Sentence Prediction(NSP)。
7.2.1、Masked Language Modeling(MLM)预训练任务
BERT 具体采用的方法是,随机选择 15% 的 tokens 出来,但是并非把它们全部都 MASK 掉,而是:
- 其中的 80% 被替换为 [MASK],类似
my dog is hairy -> my dog is [MASK]。 - 其中的 10% 被替换为一个随机 token,类似
my dog is hairy -> my dog is apple。 - 剩余的 10% 不变。
这个 80-10-10 是怎么定出来的,Google 团队也是脑拍了几种数字组合试出来的,如下图:

- MNLI 任务:Multi-Genre Natural Language Inference 是一个大规模的众包蕴含(entailment)分类任务(Williams et al., 2018)。给定一对句子,预测第二个句子相对于第一个句子是蕴含、矛盾还是中性。
- NER 任务:Named Entity Recognition 命名实体识别任务,比如对于输入语句「擎天柱回到赛博坦」得到输出「B-PER, I-PER, E-PER, O, O, B-LOC, I-LOC, E-LOC」,其中 B、I、E 分别表示开始、中间、结束,PER、LOC 分别表示人物、地点,O 表示其他无关。
7.2.2、Next Sentence Prediction(NSP)预训练任务
许多 NLP 任务 (比如问答、推理等等) 都涉及到句子之间关系的理解,这不会被一般性的语言建模过程学习到。因此 Google 想用预训练 阶段的 NSP 任务来解决这个痛点。NSP 预训练任务所准备的数据,是从单一语种的语料库中取出两个句子 $S_i$ 和 $S_j$ ,其中 $50 \%$ 的情况下 $B$ 就是实际跟在 A 后面的句子, $50 \%$ 的情况下 $B$ 是随机取的。这样语言模型就是在面对一个二元分类问题进行预训练,例如:
1 | INPUT: [CLS] the man went to [MASK] store [SEP] |
1 | INPUT: [CLS] the man [MASK] to the store [SEP] |
CLS 是一个表示「classification」的 token,SEP 是一个表示「separate」的 token。这样的预训练任务,让 BERT 在词维度的语言知识外,也让 BERT 学习到一些句子维度的语言结构。
7.3、BERT 的哪些改进是带来最显著性能提升的?
BERT 与其他几个主流模型的性能对比如下:

可以看到 BERT 在当时有着极其出色的表现。那么对于这么出色的表现,从上面 BERT 的架构特色到训练方法,到底什么改进对 BERT 性能的积极影响是最大的?这就要依赖消融研究(Ablation Studies,也可以叫消融实验)了。什么是消融研究?你在一些论文中会经常看到,就是指删除模型或算法的某些「功能」并查看其如何影响性能,也就是物理实验中大家最熟悉的「控制变量」法,我们下面具体看下 Google 对 BERT 做的消融研究实验:

上表中对如下四项做了对比:
- BERT-Base:这个是 baseline,其他所有「变量」都基于此。
- No NSP:在 BERT-Base 上移除「Next Sentence Prediction」预训练任务。
- LTR & No NSP:LTR 就是 Left To Right,也就是变成了 GPT 的 Auto-Regression Model 架构,同时也把 NSP 预训练任务移除。
- +BiLSTM:在 fine-tuning 期间,基于「LTR & No NSP」架构之上增加随机初始化的 BiLSTM。
可以看到,「LTR & No NSP」与「No NSP」对比,在 5 个任务中的 4 个都显著大幅下降,说明双向结构的正向影响是最显著的。而单独移除 NSP 后,各任务上的表现只小幅下降,但其中在 QNLI 任务上大幅下降(QNLI,Question Natural Language Inference 是基于 Stanford Question Dataset 之上的一个测试推理能力的二元分类任务),这说明增加句子维度的学习对「推理」有帮助。再看在「LTR & No NSP」上加「BiLSTM」也未能拯救性能(只有 SQuAD 提升多一些),说明 Transformer 特征抽取能力比 BiLSTM 强很多。
7.4、BERT 的数据集
BERT 比 GPT-1 用的训练数据集要大得多。BERT 同样也用了 BookCorpus(并且继承了 GPT-1 在论文中的拼写谬误「BooksCorpus」)约含 8 亿个词,以及英文维基百科(English Wikipedia)约含 25 亿词。整体来看,BERT 训练数据集大小差不多是 GPT-1 训练数据集的 4 倍左右。
7.5、BERT 小节
- 用足够硬的打榜成绩夯实了「预训练 + 微调」学习范式:过去我们都是针对某个任务进行训练,让模型成为这个任务领域的专家。但是 NLP 的很多知识是有交叉的,比如语言知识、推理能力等等,各个任务的边界并不泾渭分明,因此总是为了更好解决特定任务而要学习补充其他知识。逐渐地,领域知识的边界越来越模糊,知识范围越来越广,就逐渐自然地向着大语言模型的方向发展了,于是就出现了 GPT、BERT 这种「预训练 + 微调」的学习范式。但是 BERT 对特定任务微调后,由于参数被更新,相应地在其他一些任务上的表现可能就会下降,这就导致模型的泛化能力受到局限。而后来的 GPT-3、InstructGPT 到 ChatGPT,则是在预训练完成后并不针对任何下游任务更新参数。这样的好处是模型泛化能力很好,但是针对到特定任务身上,很肯定没有监督微调的 BERT 好,尤其是在 NLU 类型的任务上。
- 开源并开放各种规格的模型下载:成为了 2018 到几乎 ChatGPT 出现之前 NLP 领域研究的核心模型。
- Transformer Encoder 双向模型的特征抽取能力,被充分认可。但其实双向语言模型在生成类任务上并不符合人类自然的语言文字「从前向后」的交互模式,这也为后来 GPT 系列反超埋下伏笔。
- 掀起了模型轻量化的研究热点,尤其在 2020 年推出 24 个小模型后。
- NSP 预训练任务增加了句子层面的语言结构理解。
7.6、动手小实践
BERT 是主流大模型里,开放源代码和模型参数最好的。我们在本小节用 bert-as-service 来跑个简单的例子,为了让大家在任何个人电脑上都跑的起来,这个例子比较小,我们主要是为了简单实践一下找找感觉。
7.6.1、安装 BERT 所需要的各种依赖
1 | conda install tensorflow==1.14.0 |
验证 tensorflow 是否安装正确:
1 | import tensorflow as tf |
7.6.2、下载一个预训练(Pre-Train)过的 BERT 模型
官方的模型在这里浏览:https://github.com/google-research/bert#pre-trained-models
也有一些中文的模型,以下是 ChatGPT 推荐的三个:
- BERT-Base, Chinese:这是 Google 官方提供的中文 BERT 模型,在中文 NLP 任务中表现良好。你可以从 这里下载这个模型。
- ERNIE:这是由中科院自然语言所提供的中文 BERT 模型,包含了额外的语义信息。你可以从 这里下载这个模型。
- RoBERTa-wwm-ext:这是由清华大学自然语言处理实验室提供的中文 BERT 模型,在多种中文 NLP 任务中表现良好。你可以从 这里下载这个模型。
7.6.3、安装 BERT 的服务端和客户端
这里我们使用 bert-as-service,bert-as-service 是一种将 BERT 模型部署为服务的方式。该工具使用 TensorFlow Serving 来运行 BERT 模型,并允许通过 REST API 进行调用。根据 bert-as-service 的文档,它已经在 TensorFlow 1.14.0 上测试过。
在你激活的 conda 环境里,安装 bert-as-service:
1 | # 安装服务端和客户端 |
7.6.4、启动 BERT 服务端
1 | # 命令行下启动BERT服务 |
7.6.5、编写程序实现 BERT 客户端
这里有一个客户端例子可以参考:https://cloud.tencent.com/developer/article/1886981
1 | from bert_serving.client import BertClient |
7.6.6、测试效果
在使用 bert-serving-client 连接 bert-serving-server 时,你需要确保 bert-serving-server 使用的模型和 bert-serving-client 使用的模型是匹配的,否则会出现错误。
程序正常运行后,将要求你输入两句话,然后 BERT 计算两句话的相似性。
1 | 请输入语句1: |
两句输入好确认后,得到如下形式的结果:
1 | a_vec shape : (768,) |
本小节参考
- https://nlp.stanford.edu/seminar/details/jdevlin.pdf
- https://zhuanlan.zhihu.com/p/49271699
- https://arxiv.org/abs/2302.09419
- https://zhuanlan.zhihu.com/p/530524533
- https://arxiv.org/abs/1704.05426
- https://github.com/hanxiao/bert-as-service
- https://cloud.tencent.com/developer/article/1886981
第 8 节 · GPT-2(2019 年 2 月)

虽然 BERT 似乎在结果上「打败」了 GPT-1,但是用 Transformer Encoder(更容易)并且数据规模和参数规模都显著提升,多少有点「胜之不武」,OpenAI 自然不服。BERT 发布后又过了 4 个月,OpenAI 发布了比 BERT 更大的 GPT-2,俨然进入了军备竞赛。前面船涨介绍 GPT-1 时仍以结构理念、训练方法为主,现在介绍这个扩展自 GPT-1 的 GPT-2,则我们主要以它在结构、方法、数据等方面改进了什么为讲解线索。
8.1、GPT-2 是对 GPT-1 的直接扩展,但更笃定地追逐「通用语言模型」的理想
在 2018 年 6 月,Salesforce Research 团队在论文《The Natural Language Decathlon: Multitask Learning as Question Answering》中提出「通用 NLP 模型是无法诞生于一个只着眼在单一度量、数据集和任务的范式中的」,同时提出将 NLP 的十项全能任务(Natural Language Decathlon,decaNLP),主张所有 NLP 任务可以转换成问答任务,并且提出了一个基于该思路的实验模型 MQAN 来挑战 decaNLP,尽管性能表现还有差距。
DeepMind 团队对 Salesforce Research 提出的假设非常认同,并在 2019 年 1 月发表的论文《Learning and Evaluating General Linguistic Intelligence》中提到:
A perfect language model should in theory be able to do any linguistic task.
理论上,完美的语言模型应该能够执行任何语言任务。We believe that continued progress on generative language models will drive progress on general linguistic intelligence.
我们相信,对生成式语言模型的持续进展,将推动通用语言智能的发展。
OpenAI 也认同这些理念假设,所以期待构建出能解决任何 NLP 任务的语言模型。OpenAI 在 GPT-2 的工作中,把这些理念假设概括为「由于(所训练的)这些任务是通用语言建模的子集,因此我们可以预期随着更多算力和训练数据的使用,性能将进一步提高。」
2019 年的情人节,OpenAI 在其官方发布了一篇 blog《Better Language Models and Their Implications》,后又发布了介绍 GPT-2 的论文《Language Models are Unsupervised Multitask Learners》。GPT-2 是 GPT-1 的直接扩展,因此还是基于 Transformer Decoder 架构,但是参数扩 10 倍左右,训练数据集扩 10 倍左右。GPT-2 的训练目标也很简单,就是基于一段文本中前面的所有词,预测下一个词。训练方法上,GPT-2 没有对任何任务的任何数据集做针对性的训练,都是直接评估并作为最终结果。
GPT-2 模型的基本信息如下表,其中可以看出 117M 参数版本的 GPT-2 是对标 BERT-Base,15 亿参数版本的 GPT-2 是对标 BERT-Large。

在 AI2 网站上可以在线试用基于 GPT-2 的 Next-Token 的语言模型:https://demo.allennlp.org/next-token-lm。

GPT-2 模型架构在 GPT-1 做了一些优化,如下几点:
- Layer Normalization 移到了输入部分,并在自注意力之后也加了 Layer Normalization。
- 残差层 (Residual Layers) 的初始化权重用 $1 / \sqrt{N}$ 缩放,其中 $N$ 是残差层数。
- 词汇表扩展至 50,257.
- 上下文窗口从 512 扩展至 1024.
- GPT-2 的 batch size 是 512 .
但更重要的亮点在于其对更先进训练方法的成功验证。
8.2、GPT-2 大幅改进训练方法
GPT-2 的核心亮点,都体现在其论文标题「Language Models are Unsupervised Multitask Learners」中。第一个亮点即「Unsupervised」,可不只是预训练过程无监督,整个学习过程都可以无监督。第二个亮点是「Multitask」,在无监督的情况下还可以把多种不同的任务混合起来学。
8.2.1、Zero-Shot:无需监督微调即可执行下游任务,不用 fine-tune
GPT-2 的首个重要改进,就是其论文摘要中的前两句话总结:
Natural language processing tasks, such as question answering, machine translation, reading comprehension, and summarization, are typically approached with supervised learning on task-specific datasets. We demonstrate that language models begin to learn these tasks without any explicit supervision when trained on a new dataset of millions of webpages called WebText.
GPT-1 及当时所有语言模型的局限性在于,即便采取无监督预训练,仍然需要对特定任务进行监督微调。而 OpenAI 在 GPT-2 上验证了基于数以百万计网页上的无监督学习后就可以执行多种语言任务,比如问答、及其翻译、阅读理解、文本摘要。
8.2.2、Multitask Learning:多任务学习共享参数更新
卡耐基梅隆大学 Rich Caruana 在 1997 年提出了 Multitask Learning(多任务学习) 这样一个提升模型泛化能力的学习框架,但是经过了二十年发展,NLP 在多任务的训练探索上仍然不成熟。
不过有两个取得了一定突破的技术路线,值得关注。一个是,2018 年 OpenAI 提出的 GPT-1 与 Google 提出的 BERT 都验证了「不需针对特定任务而只需要增加自注意力即可」的架构可行性。但是这样的技术方案,依然需要用到监督学习,泛化性依然受局限。另一个是,在无监督或极少量监督数据的情况下,在特定任务上也都能取得很好表现,例如常识推理(华盛顿大学几位学者于 2017 年在《Story Cloze Task: UW NLP System》研究中验证)、情感分析(OpenAI 团队 2017 年在《Learning to Generate Reviews and Discovering Sentiment》研究中验证)。
OpenAI 团队受到两条研究路线的启发并采用更通用的迁移方法,实现无监督预训练后,在 Zero-Shot 情况下完成多任务,多有任务共享更新同一个 Transformer Decoder 架构之上的模型参数。
8.3、GPT-2 的预训练数据集:高质量、多样性的 WebText
GPT-1 是拿一堆书预训练的,其实很明显多样性是不足的,尤其只用了小说。
GPT-2 则用了 40GB 的 WebText 语料(800 万个网页)。具体地,这些网页都是来自 Reddit 的网页中包含的出站链接(Outbound Links),并且获得了至少 3 个 karma,这两点门槛让 OpenAI 认为得到了一些比较高质量的网页(明显质量比 CommonCrawl 整来那些乱七八糟的要高不少)。而且这样得到的数据集,具有非常好的多样性,因此很多任务的示例会自然地被学习到。OpenAI 在论文中提到:
…… These findings suggest a promising path towards building language processing systems which learn to perform tasks from their naturally occurring demonstrations.
…… 这些发现为构建语言处理系统指明了一条道路,就是从文本语料中自然出现的样本示例来学习并完成任务。
当 OpenAI 在研发 GPT-2 时这样认为,已经预示着两点:1)ICL(In-Context Learning),甚至 Prompt Engineering,势必会在语言模型通用性变得更强后,成为一个人人都能参与的研究热点。2)如果各类任务的模式是「隐式」出现在语料中的,那么大规模训练数据就意味着可以覆盖更多任务类型,进而暴力军备竞赛有了理论上的动力。
从实验表现上,用 WebText 预训练的 GPT-2 优于在 Wikipedia、新闻或书籍上训练的其他语言模型,而无需使用这些训练数据集。
8.4、如果预训练直接喂生数据,最终的效果怎样?
对于预训练数据集的处理,GPT-2 采用了最简单直接、符合我们目标期待的方式:不作任何处理,直接喂生数据(raw text)。
8.4.1、生文本「隐式」包含任务模式,上下文「显式」提示具象任务
GPT-2 直接从原始文本开始学习,而不需要针对任务准备的训练数据,也不需要任何微调,尤其对于问答、阅读理解、summarization、translation 这些任务上,只需要以正确的方式提示经过训练的模型就能得到令人惊讶的结果。当然离 SOTA 还有区别,但作者们表示,从实验表现上看,如果有足够大的未标记数据集和算力,模型在这些任务上也会取得领先表现。

↑ 标注 (+) 的项,表示分数越高越好;标注 (–) 的项,表示分数越低越好。
这里已经基本预示着,投喂生文本数据,让模型「囫囵吞枣」地学会了不少东西,就像一个小孩子到父亲的书房里翻了很多很多书,知识都学杂了。但是如果启发教育问的好,给一些上下文提示语,模型就能给出很不错的响应。这也就引出了 In-Context Learning、Prompt Engineering 等一系列话题。关于这些的探讨,我们将在「In-Context Learning」那一章详细介绍这方面的研究发展和技术尝试。
但是显然在 GPT-2 这个阶段,其表现还没有让 OpenAI 这么笃定这件事。比如整体看,OpenAI 发现需要对 GPT-2 多尝试几次才能获得好的样本,尝试的次数取决于模型对上下文的熟悉程度:1)当提示数据中有非常具体的主题(比如英国脱欧、指环王等)时,GPT-2 能在一半的时间内生成合理的样本。2)对于高度技术性或深奥类型的内容,GPT-2 就表现不太行了。比如对于数据集 Natural Questions 上,OpenAI 给出测试问答的例子:

8.4.2、LLM 军备竞赛的序幕拉开
整体来看,GPT-2 在以下这些数据集上执行的对应任务,虽然很多没到 SOTA,但效果还可以,毕竟是没有针对性的任务数据拿来训练的。还是上面提到的那句,OpenAI 认为「由于(所训练的)这些任务是通用语言建模的子集,因此我们可以预期随着更多算力和训练数据的使用,性能将进一步提高」。这也为 GPT-3 留下了巨大的空间:

在 GPT-2 的开发与公布阶段,OpenAI 就已经跃跃欲试 LLM 下一阶段的可能范式:基于扩展性极好的 Transformer Decoder 架构上(撑得起巨量参数规模)构建模型,并投喂足够多的数据(海量数据已经潜在包括各种任务模式)进行无监督预训练(所有任务都「隐式」地变成从左至右的生成训练) —— 从而拉开了「大模型、大数据、大算力」的军备竞赛大幕。
8.5、OpenAI 初步预见了 LLM 可能带来的影响
其实如果大家对 2019 年的科技新闻还有印象的话,一定记得当时说有一家美国公司搞了个 AI 模型编造假新闻给大家忽悠得一愣一愣的,也就是 GPT-2。另外 GPT-2 在发布时只放出来一个小模型,所以也就是从这时开始 OpenAI 被人调侃为 ClosedAI 的。
当时 OpenAI 认为 LLM 正变得越来越可扩展、可定制、生成连贯,而这可以给各行各业带来很大积极价值,也能拿来作恶。因此 OpenAI 最初发布博客和论文时没有放出完整的模型,只给出了一个用于研究的实验小版本:https://github.com/openai/gpt-2 。具体地,GPT-2 没有放出数据集、训练代码、GPT-2 模型参数。OpenAI 认为那些可能的危害是必须预防的,所以要预期到。
8.5.1、OpenAI 在 2019 年就倡议政府监管
It is not possible to control research in these domains without slowing down the progress of AI as a whole.
如果管控这些领域的研究,就不可能不减缓整个人工智能的进展。
OpenAI 希望大家对此要有预期,不要抵触可能出现的管控。甚至 OpenAI 早在 GPT-2 出现的 2019 年这个时间点就提出倡议:
政府应考虑扩大或启动更系统地监测 AI 技术的社会影响和扩散,并要能够量化 AI 系统能力的迭代发展情况。
这其实就预示着后来关于「对齐(Alignment)」这个议题被更重视的提出,顺带必然要面对的「对齐税(Alignment Tax)」,也因此有为了 Alignment 而出现的 InstructGPT,进而孕育出 ChatGPT。
8.5.2、同年 5 月公布 3.45 亿参数版本,并暗示了后来微软对 OpenAI 不 Open 的影响
同年 5 月,OpenAI 公开发布了 GPT-2 的 3.45 亿参数版本,因为 OpenAI 认为很多机构已经能够训练同等能力的模型,所以风险不大。
另外,对那些致力于促进社会为 LLM 的广泛影响做好准备的合作伙伴与安全社区,OpenAI 开放了 7.62 亿参数和 15 亿参数的版本。这里 OpenAI 提到:
These research partnerships will be a key input to our decision-making on larger models.
这些研究方面的合作关系将是我们在决定发布更大模型时的关键因素。
这个在 2019 年时间节点上的表态,暗示了此后 OpenAI 与 Microsoft 的合作关系,对于 OpenAI 后续模型的公开程度的影响,给各方在打预防针。后来在 2023 年 1 月 23 日 OpenAI 博客上也发布了《OpenAI 与 Microsoft 扩大合作伙伴关系》一文提到 Microsoft 从 2019 年开始对 OpenAI 的投资。
而在 5 月这次发布的内容,还包括GPT-2 output dataset。
8.6、GPT-2 小节
GPT-2 的亮点和洞察:
- 自回归语言模型虽然难但正确,可以隐式地从语料中学到各类任务概念(有研究认为其包含隐式马尔科夫模型,详见本篇第 14 节),继续显著提高性能及泛化能力的方法,就是加大训练数据规模、模型参数规模。
- 无需监督微调阶段:处理下游任务时不需要 fine-tune,预示未来在 LLM 上以 Prompt 方式完成任务可能成为一种新范式。
本小节参考
- https://openai.com/blog/better-language-models/
- https://jalammar.github.io/illustrated-gpt2/
- https://github.com/openai/gpt-2
- https://github.com/openai/gpt-2-output-dataset
- https://zhuanlan.zhihu.com/p/56869079
- https://demo.allennlp.org/next-token-lm
- https://openai.com/blog/openai-and-microsoft-extend-partnership/
- https://link.springer.com/article/10.1023/A:1007379606734
- https://arxiv.org/abs/1806.08730
- https://arxiv.org/abs/1901.11373
- https://maartensap.com/pdfs/schwartz2017story.pdf
- https://arxiv.org/abs/1704.01444
- https://www.mikecaptain.com/2023/01/22/captain-aigc-1-transformer/
- https://zhuanlan.zhihu.com/p/350017443
第 9 节 · T5:提出所有 NLP 任务可统一为文本生成任务(2019 年 10 月)

Google 团队在 2019 年 10 月发布了一个对 NLP 任务大一统的 T5 模型《Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer》。T5 模型是基于 Transformer 整体 Encoder-Decoder 架构的。这篇论文有三个后来被大家常提起的关注点 —— 对下游 NLP 任务的统一、新开源数据集 C4 的引入和多到惊人的实验数据。
9.1、对下游 NLP 任务的统一
最直接的价值,就是提出「所有基于文本的语言问题,都可以转换成文本生成文本(text-to-text)形式」:
In this paper, we explore the landscape of transfer learning techniques for NLP by introducing a unified framework that converts all text-based language problems into a text-to-text format.
具体地,只要在编码前,加上任务提示(比如 summarize、translate English to German)就可以在模型输出得到想要的结果。下面这张图可以说是提到 T5 模型必会引用的图。

该图里举例了语言翻译、分类问题(来自 cola 数据集)、回归问题的语义文本相似评测(STSB)、摘要生成。除了图中提到这四种任务,T5 模型所有下游任务都可以转化(transfer)为 text-to-text 任务,所以这也是 T5 模型名称的由来:Text-To-Text Transfer Transformer。
而且这个方法并不局限于 Transformer Encodoer-Decoder 架构,其他架构的模型也可以。
9.2、新开源数据集 C4(Colossal Clean Crawled Corpus)
作者对从互联网上爬取的公开网页数据集 Common Crawl(来自 commoncrawl.org)的 6.1TB 数据过滤处理为 745GB 的「庞大而干净的爬取语料库」,也就是它名字(Colossal Clean Crawled Corpus)的由来,但其实军事迷或爱玩射击游戏的朋友们都知道,作者主要是为了凑成「C4」炸药这个缩写。
过滤处理的主要手段包括:
- 只保留以句号、感叹号、问号或结束引号结尾的行。
- 干掉了少于 5 个句子的页面,只保留了至少包含 3 个单词的行。
- 干掉了任何包含「List of Dirty, Naughty, Obscene or Otherwise Bad Words」语料库中任意词语的页面。
- 干掉了所有包含 Javascript 这个词儿的行(因为许多爬取的页面都包含类似「请启用 JavaScript」这样的警告)。
- 干掉了所有包含印刷及排版领域常用的哑元文本(又叫乱数假文)lorem ipsum —— 你可能在调试打印机时见过。
- 干掉了所有包含代码的页面。特别低,因为编程语言常用的大括号
{其实不出现在自然语言中,于是所有包含大括号的页面也都被干掉了。 - 为了删除数据集的重复数据,我们丢弃了除在数据集中出现不止一次的任何三句跨度中的一个以外的所有内容。
- 干掉了所有非英文页面(是否为英文页面由 langdetect 来做分类,概率门槛设定为 0.99)。
这里值得说的一点是,后来 GPT 系列模型里的 text-davinci-002、text-davinci-003、ChatGPT 具备推理能力,主要就是靠喂代码喂出来的,尽管代码段与 AI 学习自然语言的逻辑推理能力表面上看似无关。
过滤清洗过的 C4,从表现上来看比没有过滤的数据集,能让模型结果表现更好。对于 C4 数据集,目前你可以通过如下链接访问该数据集:https://www.tensorflow.org/datasets/catalog/c4。
9.3、大量实验覆盖模型、数据、算力的多维度因素
最为学界与业界啧啧称奇、惊叹不已的,是 T5 在实验算力投入上的一掷千金。T5 作者们对不同的架构、多种训练方法、不同文本破坏设置、不同的数据集、不同迁移方法、不同模型规模与训练时长组合等多维度都进行了实验,实验数据就是下面这张震撼的表格:

这些因素里,其中有几点,我们摘出来看下。首先,T5 作者们解释了三种不同的自注意力(Self-Attention)机制:

输入输出全部有关联的注意力,即 Fully-Visible Attention;输出只与当前输入、过去输入有关的注意力机制,叫 Casusal Attention;在 Causal Attention 基础上,让输出文本的前缀部分与所有输入文本有关,是 Causal Attention with Prefix。
基于 Transformer 模型架构,T5 作者们进行了几个不同变种:

第一个是就是 Transformer 的 Encoder-Decoder,Encoder 用 fully-visible attention,Decoder 用 causal attention;第二个相当于 Transformer 的 Decoder 部分,即只用 causal attention;第三个是在 Decoder 基础上前缀部分用 fully-visible attention,其余部分用 causal attention。实验表明第一种 Transformer 架构表现更好。
另外再看下多样预训练方法、不同文本破坏设置的对比:

- 第一步对比「预训练方法(Pre-Training Method)」。从好理解的角度讲,图中第一个的 language modeling 指的是「续写」式的 GPT(或者说 Transformer 中的 Decoder,自左向右让 AI 预测后面是啥)来做预训练,第二个是「完形填空」式的 BERT(或者说 Transformer 的 Encoder,左右双向文本都知道,AI 来预测中间是啥),第三个是「乱序还原」式的 Deshuffling(先打乱顺序,再让 AI 来还原)。从实验表现上,第二种 BERT-Style 完形填空时的胜出了。
- 第二步对比「破坏方法(Corruption Scheme)」。Mask 方法是每个 token 都被挖掉替换成掩码特殊字符;Replace Spans 方法是在 Mask 基础上如果有连续被挖掉的,则连续的几个合为一个整体掩码特殊字符;Drop 则是直接丢弃,不插入掩码特殊字符。实验表明 Replace Spans 表现更好。
- 第三步对比「破坏比率(Corruption Rate)」,就是挖掉百分之多少的 token 来做「完形填空」,实验表明 15% 是最好的。
- 第四步对比「破坏长度(Corrupted Length)」,就是一次挖多长的空比较好,实验表明 3% 是最好的。
因此 T5 模型就是通过 BERT-Style 预训练方法(具体地是用文本破坏方法 Replace-Spans、文本破坏比率 15%、文本破坏长度 3)得到的 Transformer 架构 NLP 模型。
9.4、T5 小节
- 尽管此前已经有人提出 NLP 的统一模型理念,比如 Salesforce Research 团队、DeepMind 团队、OpenAI 团队在发布 GPT-2 时。但 NLP 领域比较确定性地进入通用任务的语言模型阶段,是从 T5 正式发布后。
- ELMo 那一节提到的「NLU 和 NLG 其实并没有明显的界限」,以及 GPT-2 在致力探索的「通用语言模型」,到 T5 断言「所有基于文本的语言问题,都可以转换成文本生成文本」,可以说 NLP 主流研究及前沿应用全面向「语言建模预训练-提示」范式转换,其中语言建模预训练就是将任务全部统一为文本生成。
本小节参考
- https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html
- https://arxiv.org/abs/1910.10683
- https://github.com/LDNOOBW/List-of-Dirty-Naughty-Obscene-and-Otherwise-Bad-Words
- https://www.tensorflow.org/datasets/catalog/c4
- https://commoncrawl.org/the-data/
- https://zhuanlan.zhihu.com/p/88438851
- https://github.com/google-research/t5x
- https://zhuanlan.zhihu.com/p/589869911
- https://towardsdatascience.com/understanding-t5-model-text-to-text-transfer-transformer-model-69ce4c165023
第 10 节 · 缩放定律(Scaling Law):AI 时代的摩尔定律(2020 年 1 月)
2020 年 1 月 OpenAI 在论文《Scaling Laws for Neural Language Models》中提出了 LLM 的「Scaling Law」,这是一个经验性的总结,但此后学界与业界基本对此形成共识。
具体地,OpenAI 指出,随着算力(具体说就是训练迭代次数)、数据规模(训练集的 tokens 数)、参数规模的指数增长,测试集上验证的损失是线性下降的(即可理解为性能线性提升)。

这也就是当下 LLM 的三要素。用船涨自己的理解概括 Scaling Law 就是说:LLM 三要素(算力、数据规模、参数规模)中任一要素的指数增长,都会带来模型性能的线性增长。但别急,这还没完,请往下看完。
但尽管我们堆叠 LLM 三要素中任何一个,都能带来性能提升,但是三者的增长收益是不同的,我们看下面的图。

这张图说明,提升参数规模带来的性能提升最显著(当然不能无脑堆参数,也要优化),提升训练数据规模带来收益次之,最差的是提升算力消耗(对应训练迭代次数)。因此之后再提 LLM 的 Scaling Law,大家一般指的是「参数规模的指数增长,可以带来模型性能的线性增长」。
这就像 AI 界的摩尔定律一样,谁要是想要性能提升多少,根据 Scaling Law 预估下模型参数规模就可以了。于是一场原本就在进行的 AI 领域模型参数规模的军备竞赛,进入了显性竞争阶段,似乎 AGI(通用人工智能)即将到来的大幕正在伴随模型参数规模的提升而徐徐拉开。

上图数据来自《DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter》和《 Turing-NLG: A 17-billion-parameter language model by Microsoft》。当下语言模型的参数大型化趋势已经成为共识(但这反而值得我们警惕),例如 OpenAI 的 · 规模为 1750 亿,Google 的 LaMDA 规模为 1370 亿,PaLM 的规模为 5400 亿,DeepMind 的 Gogher 规模为 2800 亿。
第 11 节 · GPT-3(2020 年 5 月)
在 GPT-2 发布 1 年零 3 个月后的 2020 年 5 月,OpenAI 团队发布 GPT-3,从其论文《Language Models are Few-Shot Learners》可以看到,其最大亮点是数据规模、参数规模都比 GPT-2 大 100 倍。这么简单粗暴的办法,带来的是 GPT-3 表现上的炸裂。而其论文标题也点出了本文的主题:语言模型就是要无监督预训练 + Few-Shot Prompt。
11.1、GPT-3 表明 OpenAI 进一步收紧其技术开放度
首先要明白 OpenAI 在技术开放上的收紧策略,自 GPT-2 发布时就已经给公众打了预防针了,这点船涨在本篇 8.5.2 中已经提到。因此我们能看到 GPT 系列上 OpenAI 变得越来越 Closed:GPT-1、GPT-2 发布时,OpenAI 都在其官网发布了 blog,到了表现远超过 GPT-1、GPT-2 的 GPT-3 时,OpenAI 反而连一篇博客都没写。而其论文更是对关键的训练、模型、数据做了哪些重要工程表现得轻描淡写,花大篇幅着墨于实验及结果上。
GPT-3 没有放出源码、预训练好的模型参数等等,俨然变成了各国网友们调侃的 ClosedAI 了。
对于模型架构,OpenAI 声称 GPT-3 与 GPT-2 是一样的。GPT-3 依然延续了此前 GPT-2 的基本架构和预训练方法:构建基于 Transformer Decoder 的自回归语言模型,然后进行无监督预训练,无针对特定任务的微调。
11.2、GPT-3 参数规模:直接比 GPT-2 放大 100 倍
我们可以看到共 8 个参数规模的模型如下。

在模型参数规模 $n_{\text {params }}$ 的军备竞赛方面,可以看到 GPT-3 Small 是与 GPT-1(1.17 亿参数)、BERT-Base(1.1 亿参数)对应的;GPT3 Medium 是与 BERT-Large(3.4 亿参数)对应的;其余六个的参数规模都直接超过了这些大模型,尤其 GPT-3 1750 亿参数的版本,直接 从 GPT-2 最大的 15.4 亿版本基础上拉升了 100 多倍规模!也比以往任何一个非稀疏模型至少大 10 倍!
模型的 Transformer decoder block 的层数$n_{layers}$,也常叫模型深度。可以看到随着模型参数规模的急速拉升,OpenAI 团队并没有把模型深度急剧增加,与 GPT-2 152M 版本相比,比它大一百多倍的 GPT-3 175B 的层数也只不过是其两倍(96 vs. 48)。
模型的词向量长度,也常叫模型宽度,一般表示为 $d_{model}$,区分于注意力头的宽度 $d_{head}$。与 GPT-2 对比就能看到,类似层数的模型情况 下,GPT-3 要宽很多,可以说整体 GPT-3 的模型要胖一些,而不是在提升规模时更多去加深(加层数)。
GPT-3 的 batch size 都非常大,哪怕 Small 版本也有 0.5M,175B 版本更是达到 3.2M,这对内存要求非常高。如果 batch 处理并行的话,那么内存就是就是 3.2M 除以并行的数量。注意一般 batch 指的是每次训练迭代中模型处理的样本数,而不是具体的数据量,即 3,200,000 个样本,而不是 3.2MB 数据。把 batch size 做大的好处是,降低模型训练时的通讯量。不过对于小模型,batch size 太大的话很容易过拟合。对于参数量大的模型,batch size 自然也要相匹配的变大。
LR(Learning Rate,学习率)在 GPT-3 里是随着 batch size 增加而下降的,这与当时一些研究的结果是相反的。
11.3、GPT-3 的训练数据

上面这个表格,是 GPT-3 用到的训练数据集。关于 GPT-3 的训练数据集解读,很多中文文章里说的是错的,主要是对论文中该表的数据理解错误,下面我们分别来看下各个数据集和整体数据处理做的核心工作。
11.3.1、训练数据集
GPT-3 的数据源来自五部分组成,包括一个大型的来自 CommonCrawl.org 数据集、扩展的 WebText 数据集、两个互联网上的书籍语料库(一般认为书籍的语料质量是非常高的)和英文的维基百科。表中各列的含义如下:
- 第二列 Quantity:每个数据源本身的数据规模,单位是 tokens(根据 OpenAI 官方文档里提到的一个大概的经验是,通常英文文本里 1 token 有 4 个字母或者 0.75 个单词)。
- 训练期间从给定数据集中提取的部分,就是第三列 Weight in training mix(数据混合训练时的权重),因为不同数据集质量不同,基于此考虑 OpenAI 结合数据质量因素做的配比。最后,GPT-3 整体上是设定了 3000 亿 tokens 的训练数据集。
- 第四列表示各数据集在训练时出现的次数,最高的 wikipedia 是 3.4 次。这样其实是为了高质量训练,稍微接受一点点的过拟合。
说到这里,不得不提中文 LLM 的数据集问题。中文整体上是缺乏这些非营利组织语料库、高质量文本内容社区/百科平台内容的。类似 StackOverflow 这种技术问答社区、WikiPedia 高质量百科。
11.3.2、提高数据质量的处理准备工作
在上述数据集基础上,GPT-3 使用如下方式提高了数据集的质量。
首先,用一个高质量数据集作为正例,用 LogisticRegression 过滤了 CommonCrawl 的数据。这个高质量数据集是什么呢?还记得 GPT-2 里采用的 WebText 数据(Reddit 外链,且 Karma 大于 3)吗?OpenAI 认为这是质量比较高的数据,就是将其作为正例来过滤的。过滤前的文本压缩规模是 45TB,过滤后的是 570GB。
其次,在文档级别上用 LSH 算法去除重复的数据。LSH 是 Locality Sensitive Hashing(局部敏感哈希),是信息检索领域的一个常用算法,可以快速判断一个词集合(文章就是一个词集合)和一个很大集合之间的相似度。
第三,再额外加一些高质量的数据,上面表格中 WebText2 就是基于 GPT-2 用的 WebText 扩展而来的,另外还有 English Wikipedia、两个电子书数据集。
11.4、GPT-3 的训练开销

上图展示了 GPT-3 与 BERT、RoBERTa、T5 的训练算力对比。可以看到 GPT-3 的算力开销有多么惊人。注意图标的纵轴是非线性的、指数级间隔。那么消耗这么多的算力,性能表现如何呢?我们看下面这张表。

上表中横轴是算力(对应上上表中的纵轴,注意同样是指数增长),纵轴是训练期间的验证损失(注意也是指数增长)。可以看到每一条曲线都有一个大致的拐点,在拐点之后继续增加算力并不能显著提升性能。所有这个最优拐点连起来,是完全符合 Scaling Law 的(关于 Scaling Law 可以看本文的「第 10 节」)。
OpenAI 官方并没有公开讲过花了多少钱训练 GPT-3,市面上流传的说法「460 万美元」目前考证来看是一家云服务厂商用其最低价格 GPU 云服务估算而写的一篇软广,并不可信。也有一些其他组织或个人做了测算,整体上都是想表达训练一次很贵。至少从 OpenAI 的论文里我们能看出来,这个训练花费已经贵到研究人员即使发现多个 bug 也没舍得重新训练的地步:
论文第 9 页:Unfortunately, a bug in the filtering caused us to ignore some overlaps, and due to the cost of training it was not feasible to retrain the model.
中文翻译:不幸的是,过滤中的一个 BUG 导致我们忽略了一些重叠,而考虑到训练成本,重新训练模型是不可行的。论文第 31 页:Unfortunately, a bug resulted in only partial removal of all detected overlaps from the training data. Due to the cost of training, it wasn’t feasible to retrain the model.
中文翻译:不幸的是,一个 BUG 导致仅删除了训练数据中检测到的所有重叠的一部分。考虑到训练成本,重新训练模型是不可行的。论文第 44 页:Due to a bug revealed by this analysis, filtering described above failed on long documents such as books. Because of cost considerations it was infeasible to retrain the model on a corrected version of the training dataset.
中文翻译:由于此分析揭示的 BUG,上述过滤在长文档(比如书籍)上是失败的。出于成本考虑,在训练数据集的修正版本上重新训练模型是不可行的。
作为对比,我们看下:
- Meta AI 在同样参数规模的《OPT: Open Pre-trained Transformer Language Models》 模型上,用约 1000 个 80G A100 GPU 上训练至少两个月时间,就可想而知这花费有多高昂了。
- 2022 年 7 月,为了训练拥有 1760 亿个参数的开源模型 Bloom,Hugging Face 的研究人员耗时三个月,使用了 384 个英伟达 A100 GPU,数据来自其论文《BLOOM: A 176B-Parameter Open-Access Multilingual Language Model》。
11.5、In-Context Learning
OpenAI 在 GPT-3 发布中显式地提出了 In-Context Learning,即在无监督训练好的 GPT-3,使用时用少量示例就可以得到有较好的输出反馈,这就叫 Few-Shot Prompt。只有 1 个示例的时候就叫 One-Shot Prompt,没有示例的时候就叫 Zero-Shot。对于在使用时出现在输入中的这些示例,模型是不会更新其参数来做 fine-tune 的。那么模型是怎么从这些示例学到东西的呢?我们把这样的学习方法叫 In-Context Learning,即模型从无监督的训练文本上下文里,完成了非显性的学习。

In-Context Learning 与 Fine-Tune 两者区别在于是否更新模型参数。In-Context Learning 这种神奇的能力为什么会 work,船涨将和你在本文的「第 14 节 · 语言模型是如何具备 ICL 能力的?」一起来初步探索下(目前这个领域还没有完全清晰明确的理论证明)。OpenAI 评估模型性能时,对示例不同做了区分:
Few-Shot Learning,对每个子任务提供 10-100 个样本。

One-Shot,Few-Shot 一个特殊情况是只给 1 个样本,我们叫 One-Shot Learning。

Zero-Shot Learning 顾名思义无样本。

对位对比,Fine-Tune 如下图示例,能看到要进行多次梯度更新。

GPT-3 得出了一些与 ICL 有关的一些实验结论。模型性能表现,随着示例样本数增加而增加,如下图所示。

无论是 Few-Shot、One-Shot 还是 Zero-Shot,模型的性能表现都随着参数规模的增加而增加,如下图所示。

关于 Few-Shot Prompt,沿着 Few Shot 的方向,机器学习的过程有点类似于人类的学习:大量无监督输入,针对特定任务只需极少量有监督输入。
更多与 In-Context Learning 有关的探讨,船涨在本篇专门安排了一个章节(第三章),会探讨如何利用好 ICL 的能力、ICL 能力的底层是什么、为什么 LLM 具备 ICL 能力、ICL 具体是如何起作用的。
11.6、GPT-3 API
具体大家可以查看 OpenAI GPT API 文档,但是这里船涨罗列几个值得一提的点。
11.6.1、GPT 一些基本概念
关于 prompt 和 completion:OpenAI 提到一个理念:「设计提示语,就相当于在用一些指令和少量例子给模型编程」。另外 OpenAI 还强调了在目标任务上的区别,就是 OpenAI 的 NLP 模型与其他 NLP 模型很大的一个区别是,它不是设计用来解决单一类型任务的,而是可以解决几乎各种类型的 NLP 任务,包括但不限于文本生成(content generation)、代码生成(code generation)、总结(summarization)、扩写(expansion)、对话(conversation)、创意写作(creative wrting)、风格转换(style transfer)等。
关于 token:我们理解和处理文本,是把文本先打碎成 token。以英文文本为例,token 可以是单词,也可以词根(一些字母组合),比如单词「hamburger」可能会被打碎成「ham」、「bur」、「ger」这几个 tokens。再比如「pear」这个单词,可能就会单独作为一个 token 不再打碎了。还有些 token 可能会以「空格」开头,比如「 hello」、「 bye」。一个大概的经验是,通常英文文本里 1 token 有 4 个字母或者 0.75 个单词。使用时的一个限制是,最好你的提示(prompt)或生成内容,不要超过 2048 个 tokens,大概相当于 1500 个单词。
关于 model:目前 OpenAI 有基于 GPT-3.5 的基础模型 Turbo 和这些基于 GPT-3 的基础模型 Davinci、Curie、Babbage、Ada 开放 API,另外 Codex 系列是 GPT-3 的后代,是用「自然语言 + 代码」训练的。
11.6.2、GPT-3 的几个基础模型
注意:因为 2023.3 OpenAI 发布了 GPT-3.5 支持的 API,所以原有的模型已经有一些变化了,此处列出的并非 GPT 全部 API,详细信息可以看船涨的一份入门解读《AI 应用第一次大爆发来了:一文入门 ChatGPT 官方 API 文档解读》。
先介绍下基础模型系列如下:
- Davinci:目前已经有 GPT-3.5 版本的 Davinci 了,但 Davinci 在 GPT-3 中就已经存在,是最有能力的模型系列,可以执行其他模型(Ada、Curie 和 Babbage)可以执行的任何任务,而且通常只需要很少的 instruction。 对于需要对内容有大量理解的应用程序,例如针对特定受众的 summarization 和创意内容生成,Davinci 将产生最佳结果。 这些增加的功能需要更多的计算资源,因此 Davinci 每次 API 调用更贵,并且不如其他模型那么快。Davinci 的另一个亮点是理解文本的意图。Davinci 擅长解决多种逻辑问题和解释人物的动机。 达芬奇已经能够解决一些涉及因果关系的最具挑战性的人工智能问题。适合:复杂的意图、因果分析、Summarization for Audience。
- Curie:Curie 在 GPT-3 中就已经存在,也非常强大,速度也比较快。 虽然 Davinci 在分析复杂文本方面更强大,但 Curie 能够胜任许多细微的任务,例如情感分类和摘要。 Curie 还非常擅长回答问题和执行问答以及作为通用服务聊天机器人。适合:机器翻译、复杂分类任务、情感分析、Summarization。
- Babbage:同样是 GPT-3 里就存在的。Babbage 可以执行简单的任务,例如简单的分类。在语义搜索方面,它也非常有能力对文档与搜索查询的匹配程度进行排名。适合:适度分类、语义搜索分类。
- Ada:也是 GPT-3 时期就有的。Ada 通常是最快的模型,可以执行解析文本、地址更正和不需要太多细微差别的某些分类任务等任务。 Ada 的性能通常可以通过提供更多上下文来提高。适合:解析文本、简单分类、地址修正、关键词。需要注意的是:由像 Ada 这样更快的模型执行的任何任务都可以由像 Curie 或 Davinci 这样更强大的模型执行。
基于这些基础模型系列,目前 GPT-3 目前可用的模型包括下面这些,与 InstructGPT 背后的模型是一样的,它们的最大请求都是 2048 tokens,训练数据也都是 up to 2019 年 10 月:
text-curie-001:比 davinci 要弱一点,但是速度更快、更便宜。text-babbage-001:一些比较直接的任务(straightforward tasks),比text-curie-001更快、更便宜。text-ada-001:一些非常简单的任务,这些模型里最快、最便宜的。davinci:目前最强的 GPT-3 模型,任何其他模型能做的任务,davinci都可以做。curie:就是text-curie-001。babbage:就是text-babbage-001。ada:就是text-ada-001。
11.7、GPT-3 小节
- GPT-3 比较充分展示了训练范式上不用微调的可信性。
- GPT-3 跟很多深度学习模型一样,都是无法解释的。
- LMM 一定是下一个军备竞赛打卡点。LMM 即 Large Multimodal Models(大型多模态模型),目前的 LLM 只是在读书(读文本),缺少其他体验,比如视频到底是什么鬼,比如真实物理世界的交互;而 LMM 就不同了,可以与人类进行不同模态的交互,可以读懂人类给它的文本、视频、语音等等模态内容,也能根据需要给人类生成文档、图片、视频等等。
- GPT-3 论文试图重新定义 Meta Learning,但发表后并没有引起大家的认同。
GPT-3 的局限性也很明显:
- 训练成本太高。算力能耗太高,不环保。当然一开始大型计算机出来的时候也是很夸张的用电量和占地空间。
- 样本有效性差,目前训练方法还是让 GPT-3 看了太多数据了(相比人类一生能看的文本量,GPT 看的量太大了)。未来提高样本有效性也是一个重要工作。
- 缺少 Alignment,可能导致被用来撒布不实消息、生成垃圾邮件或者钓鱼、造假论文;内容可能带有性别偏见、种族评价、宗教歧视;缺少对政治敏感的兼容,但这也是最复杂的。
- GPT 在 few-shot learning 时到底是现学的,还是找到原来学过的相似的东西找出来。如果是后者,那真的是在拼训练数据大小了。但是对比人类,我们应该要做到前者才对。
- 如果要补全一段,还可以。如果要一直续写小说,GPT 可能不太行。
- 训练学习时,对每个词都是一样对待的,就不像人类其实是有重点的。
- 这里也有问题:1)当你在下游任务真有一大组样本(比如 1 万条)想给模型时,Few-Shot 真的给模型那么多数据么,那每次使用都要带着也太麻烦了,效率也不高。2)哪怕只有 1 条样本想 Prompt,不用它效果就不好,但是每次使用模型都要把这一条带着也不优雅。
本小节参考
- https://arxiv.org/abs/2205.01068
- https://jalammar.github.io/how-gpt3-works-visualizations-animations/
- https://lifearchitect.ai/chatgpt/
- https://platform.openai.com/docs/api-reference/
- https://arxiv.org/abs/2211.05100
- https://arxiv.org/abs/2005.14165
- https://www.microsoft.com/en-us/research/blog/turing-nlg-a-17-billion-parameter-language-model-by-microsoft
- https://bmk.sh/2020/05/29/GPT-3-A-Brief-Summary/
- https://openai.com/blog/gpt-3-apps/
第三章 · 上下文学习(In-Context Learning)
一个预训练模型,在处理下游任务时,不微调模型参数,只需要在输入时加一些示例,就能有 SOTA 的表现,这就是模型的上下文学习(In-Context Learning,ICL)能力。比如下面的 ICL 示例:

相比我们以往对计算机、神经网络的理解,这是很神奇的。因为我们并没有「有意地、显性地」用某个下游任务去预训练 LLM,但是 LLM 却能很好地给出输出。大家使用 ChatGPT 自己都有体会,这里不必举更多例子。那么由此就有两个有意思的议题方向:
- 这说明 prompting 只是让 LLM 已具备的能力被展现出来,那么 LLM 是如何具备 ICL 能力的?ICL 能力又是如何工作的?
- 别管那么多,既然 LLM 有 ICL 能力,那就直接用吧!有什么强有力使用方法可以挖掘出来?这也是很值得探究的方向。
可以说 2 是「知其然」,而 1 是为了「知其所以然」。咱们先看看使用上,研究人员们都开发出来了什么吧。
第 12 节 · ICL 能力的直接应用:Prompt Engineering
大概在 2017~2019 年期间「预训练-微调」是绝对的主流范式,此后随着 GPT-2 出来「预训练-提示」这种范式就开始出现,尤其是 GPT-3 推出开始加速发展,到 2021 年开始相关围绕 Prompt 的研究井喷出现,以至于 2021~2022 期间很多学界人士的研究重点都转向了 Prompt。那么我们来看看围绕 Prompt 的研究发展到了什么程度。
首先一般性地「Pretrain, Prompt」到了 Prompt 环节,可能是给模型输入 $x$ 期望得到输出 $y$ 。但是如果我们对使用者给出的 $x$ 进行二次加 工(比如把这个加工表示为一个函数 $f$ ),是否能在输出上获得更好的结果 $y$ 呢? 即:
如果不止优化输入,我们优化输出。比如我们在模型直接絽出的结果 $y$ 上进一步再加工 (比如把这个加工表示为一个函数 $g$ ),可以使得到 的结果更加优质呢? 如下:
为了好理解,我举个例子。比如模型的使用者想问「自驾去杭州周边两天一夜玩,有什么推荐的地方吗?」,模型返回了「南浔古镇」。而如果通过 Prompt Engineering 优化一下可以这样:

这样 $f(x)$ 就是 Prompt Engineering,而 $g(x)$ 其实是 Answer Engineering。
12.1、PET:提出 PVP 框架
德国慕尼黑大学的研究人员于 2020 年 1 月在论文《Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference》中提出 PET(Pattern Exploiting Traning)训练方法,该方法主要用于小样本上的文本分类和自然语言推理。以小样本的文本情感分类任务为例,我们下面来快速讲一下 PET 方法,可能会有一点抽象,如果不理解也没关系,可以跳过。
现在我们希望用预训练过的模型来通过微调的方式解决下游任务,而下游任务的标记样本有比较少,如何解决呢?
将这少量的标记样本,改造为完形填空(Cloze Questions)的模式。但是因为样本千奇百怪,可能需要不同的「完形填空」模式,所以就分成几类模式(Pattern),每一类模式都对应着自己要的填空内容。分类到填空内容存在一个关系映射(我们叫 Verbalizer),比如「这个披萨很 ___ 」可以填「好吃」或者「难吃」,Verbalizers 就是 $v \text { (positive) }$=好吃,$v \text { (negative) }$=难吃,这样就打造出了多组「Pattern-Verbalizer Pairs,PVP」。你可能会问,那为什么 Pattern 也有多种呢?我举个例子,比如「这家披萨店我再也不想来了」表达的也是 Negative,但是与「这个披萨很难吃」就是不同的模式,其对应的 Verbalizer 也不同,所以就有了多组 PVP。

理解这个的话,PET 就一共有 3 步(对应上图):
- 每一组 $\mathrm{PVP}_i$ 都去单独微调一个预训练模型 $\mathrm{M}_i$ 。
- 再用微调过的 $\mathrm{M}_i$ 去跑下游末标记的数据,得到多组标记结果,再汇总到一起。
- 对汇总的标记结果用分类器进行最终的文本分类。
可以看到这也是基于「Pre-train and Fine-tune」范式而来的方法。
PET 最大价值是定义了一套在预训练模型上更好完成下游任务的方法框架 PVP。这里最关键的工作有两个,一是构建各种 Patterns(也有文献叫 Templates),另一个是构建 Verbalizers,这两个是 2020 年 PET 提出后围绕它的两个研究热点。
而原始的 PET 方法有一个问题,就是要 fine-tune 预训练模型。当模型都大型化之后,fine-tune 的成本太高,何况还要 fine-tune 多个预训练模型。因此,如果面对下游任务时,不更新预训练模型参数,即不 fine-tune,只是给模型 prompt 呢?
另一方面,LLM 本身也具备对任务很好的迁移性,尤其在 2020 年 PET 出来那个节点前后,整体研究范式已经在从「预训练-微调」向「预训练-提示」转换了。LLM 这种强大的下游任务迁移能力,其实就体现在了不需要 prompt 携带太多下游标记样本,就能有较好性能,那也就更没必要去更新参数了。比如本篇第 11 节介绍的 GPT-3 就提到在并不多样本量情况下,多个任务通过 few-shot 随着模型规模增大就能达到 SOTA(以下几个实验样本量都未超过 100):

12.2、从硬提示到软提示
Prompt 最开始都是人工编写的,如果用 来表示希望模型输出的结果,如果给模型的 prompt 是「some words some words」这种形式,一般叫 cloze prompt;如果是「some words __ 」这种形式,一般叫 prefix prompt。这是提示的两种不同形状(Prompt Shape)。
这样编写的质量就非常不稳定,而且什么样的质量好,人的主观判断也并不可信,比如看下面这几个例子:

我们把这种 Prompt 叫「硬提示(Hard Prompt)」,也有叫「离散提示(Discrete Prompt)」。其缺点显而易见,但即使如此,这个阶段人们还是开发出来一些围绕 Hard Prompt 的方法,比如 Prompt Mining(在输入输出之间插中间词来搭建依赖路径)、Prompt Generation(用另一个模型来生成 Prompt,有点套娃)等等,因为不是重点这里不展开。
Prompt 的初衷是为了「让下游任务迎合上游模型」,其实从逻辑上与「让上游模型迎合下游任务」类似,只是后者用「微调」地方式改变上游模型,受此启发,能不能用类似「微调」的方式改变下游呢?也就是,为了找到更好的 Prompt,我们可以把优化 Prompt 自身也当做一个任务目标,让机器连续地优化 Prompt —— 这就是软提示(Soft Prompt),也叫连续提示(Continuous Prompt)。
想用机器学习的方式优化 Prompt,就一定要引入额外参数了。怎么让引入的参数有效地服务于优化 Prompt 的目标,研究人员们提出了如下方法:
- Prefix Tuning:2021 年 1 月 Stanford 学者提出在论文(《Prefix-Tuning: Optimizing Continuous Prompts for Generation》)中提出该方法。
- P-Tuning:2021 年 3 月《GPT Understands, Too》
- PPT:2021 年 9 月《PPT: Pre-trained Prompt Tuning for Few-shot Learning》
这些软提示方法,成文时间有限在此暂不展开。但这里最值得一提的,是 Google 团队的一个研究,在下一小节我们来一起看下。
12.3、Prompt Tuning
2021 年 4 月 Google Research 团队在文章中《The Power of Scale for Parameter-Efficient Prompt Tuning》提出「Prompt Tuning」。连续优化 Prompt 是另一种「微调」,调的对象是 Prompt,所以叫做「Prompt Tuning」。与其相对的,我们一般说的「Fine-tuning」在这个语境下专指「Model Tuning」,即更新的对象是模型,而 Prompt Tuning 不更新模型。两者的对比如下:

另外一个用来对比的方法是,文章提出的按个时间 Prompt 已经火了,尤其 GPT-3 发布后,但是大家主要还是在设计没有 tuning 的 prompt,Google 团队在此将这种方法叫做 Prompt Design。研究发现,随着模型参数增大,Prompt Tuning 与 Fine-tuning 性能相当,并且显著优于 Prompt Design,如下图:

具体地,研究人员用的是一种「前缀提示」方法,但是这些前缀并非来自人工设计,而是由机器学习方法不断微调产生的,同时上游的模型参数始终固定不变。这相当于把 Prompt 当做下游的一个独立训练任务,但是优化好的 Prompt 作为输入交给上游模型。所以这种方法,是会引入额外参数的,所以需要验证参数有效性前提下,在此基础上期待看到模型在 Prompt Tuning 中表现不逊于 Model Tuning。
研究人员从四个方面重点深入,做了消融研究(忘记消融实验含义的读者,可以回顾本篇 7.3 小节):

每个图中的绿色线,是默认配置。结论是 Prompt 长度越长表现越好,Prompt 随机初始化效果显著逊色,训练方法上使用真实本文输出代替 T5 的带哨兵的文本输出效果好(T5 的 Span Corruption 策略导致其输出始终有哨兵存在,具体详见 T5 论文,这里不展开,不理解并不影响继续阅读)、且修正消除哨兵影响的 T5 训练步数越多效果越好。但是,只要模型参数足够大,Prompt 的长度、初始化方式、跟 T5 输出哨兵问题有关的预训练方法及训练迭代次数不同时,影响也都不大。
12.4、Prompt 带来的风险
通过 Prompt Engineering 也有很多作恶的空间,因为可能可以绕过 LLM 原本设定好的政策。也有很多相关的研究、分析或报道,这里暂不详述,船涨提供以下参考阅读:
- Prompt injection attacks against GPT-3
- WHAT’S OLD IS NEW AGAIN: GPT-3 PROMPT INJECTION ATTACK AFFECTS AI
- GPT-3 ‘prompt injection’ attack causes bad bot manners
- Exploring Prompt Injection Attacks
- The clever trick that turns ChatGPT into its evil twin
12.5、小结
围绕 Prompt 的研究已经进入了工程实用阶段,LLM 的潜力就像一座金矿,这个方向的研究人员在不断挖掘其价值。但是对于为什么 Prompt 能够在不更新参数的 LLM 上得到 SOTA 的效果,很快学界认识到仅仅发现一些不错的 Prompt 方法也只能算是在黑盒之上 Engineering,而且很多还是在他人的黑盒模型上做嫁衣(比如很多论文都是基于 GPT-3 实验的),所以逐渐这方面的研究开始从「知其然」走向「知其所以然」的探究、假设、分析和实验。但从业界视角,Prompt Engineering 仍然非常有价值。
第 13 节 · ICL 能力的底层假设:贝叶斯推理
LLM 为什么具备 ICL 能力这方面有一些研究蛮有意思的,下面和船涨来一起看看。但这里有一个基础的假设,就是 LLM 具备一个底层能力:贝叶斯推理(Bayesian Inference)。
我们知道 LLM 在预训练阶段都学习过海量文本,可能从 Wikipedia 的百科到 Twitter 的推文,从 Quora 的问答到 StackOverflow 的贴子,从 Reddit 的版聊到 arXiv 的论文,从莎士比亚的十四行诗到 GitHub 上的代码 …… 所以我们假设:在预训练大量文本时,语言模型已经对多种(覆盖下游任务的)概念进行了建模。
所以问题就变成了:预训练时 LLM 先验性地学到了某些概念,现在使用 LLM 时问了它一些与这些概念存在一定似然度的问题,这时 LLM 就可以后验性地预测输出了。
这是不是让你想起了「贝叶斯推理(Bayesian Inference)」?对于不熟悉的朋友,这里简单介绍下贝叶斯推理。起初,贝叶斯是为了解决「概率预测」问题而提出的「贝叶斯定理/贝叶斯公式」,可以表示为:
$P_{\text {priori }}$ 为先验概率,是对事情的主观判断、过去经验的总结规律等。 $L$ 为「似然度 (Likelihood) 」,而 $P_{\text {posteriori }}$ 是后验概率。贝叶斯定 理影响了概率理论的发展,在所有需要对概率进行预测的情况里你都能看到它的身影,而它也成为了机器学习的一个核心方法。这里对于 LLM 具备 ICL 这种魔法能力的事实,有学者给出了相对令人信服的基于贝叶斯推理的数学解读,我们一起来看看。
第 14 节 · LLM 是如何具备 ICL 能力的?(2021 年 11 月)
2021 年 11 月,斯坦福大学的几位研究人员在论文《An Explanation of In-context Learning as Implicit Bayesian Inference》中试图给出解释。首先作者们提出了一个假设:「语言模型是通过 In-Context Learning prompt,在模型内定位到已经学好的概念(concept),进而解决 In-Context Learning task」。如果是这样,那么语言模型是具备贝叶斯推理能力的。作者们认为是如下这样实现这一点的:
- 预训练阶段:预训练时为了预测下一个 token 是什么,语言模型必须通过前面句子的证据来推理文本潜在的任务概念。这让 LLM 学到了一些先验的概念(concept)。
- ICL 阶段:如果提示(prompt)中出现了与预训练时所遇到概念(concept)似然度较高的示例(demonstration),那么 LLM 就会给出一些后验结果。
从数学上,研究人员提出了一个数学框架假设来理解在预训练过程就实现了的上下文理解能力:LLM 就是很多隐式马尔科夫模型的混合体(Mixture of Hidden Markov Models)。
14.1、预训练分布(Pretain Distribution)的数学解读
预训练的一个文本都可以表示为一个长度 T 的序列:
其中 $\Theta$ 是一组 concepts 的集合, $\theta$ 就是模型中隐含的某一 concept。如果假设 $P\left(o_1, \ldots, o_T \mid \theta\right)$ 是一个隐式马尔科夫模型 (HMM) 定义 的,那么 $\theta$ 就决定了 HMM 所有状态的转移概率矩阵。
具体下来回到本小节内容开头的第一个插图的举例来看,比如两种情况下的概率是均等,那么上面的公式则可以表示为:
14.2、上下文学习(In-Context Learning)的数学解读
LLM 完成训练后,我们就可以给它一个提示,它是由「一组独立的示例 $d_1,[\operatorname{delim}], d_2,[\operatorname{delim}], \ldots,[\operatorname{delim}], d_n+$ 一个输入 $\left.x_{\text {test }}\right\rfloor$(注: [delim] 表示分隔符),并且这组示例和输入都是面向 $\theta$ 这个概念的。那么任务就可以理解为在 LLM 中找到对应 $\theta$ concept 的那个 $\mathrm{HMM}$ 进而给出输出结果,并且随着 $n \rightarrow+\infty$ ,输出结果无限逼近于理想的输出结果 $y_{\text {test }}$。
14.3、LLM 是隐式马尔科夫模型的概念混合体(Mixture of HMM Concepts)
Xie et al. 2021 合成了一个名为 GINC 的数据集,这个数据集包括:
- 预训练数据集:五种概念的 HMM 的统一混合体,1000 个用于预训练的文本文档(总计约一千万 tokens)。
- 上下文学习的测试数据:prompts 是一些带有 0~64 个示例的输入,示例长度 k 等于 3、5、8、10.
在这个数据集上,作者们基于 GPT-2 的 Transformer 和 LSTM 两个模型都做了一个实验(为了排除是模型结构的特殊性带来的),结果如下图。

Xie et al. 2021 合成了一个名为 GINC 的数据集,这个数据集包括:
- 预训练数据集:五种概念的 HMM 的统一混合体,1000 个用于预训练的文本文档(总计约一千万 tokens)。
- 上下文学习的测试数据:prompts 是一些带有 0~64 个示例的输入,示例长度 k 等于 3、5、8、10.
在这个数据集上,作者们基于 GPT-2 的 Transformer 和 LSTM 两个模型都做了一个实验(为了排除是模型结构的特殊性带来的),结果如下图。


可见,对于「包含多个概念的隐式马尔科夫」的两个关键因素「多个概念」和「隐式马尔科夫」两者分别改成「一个概念」和「随机转换」后,模型的上下文学习表现迅速下降。所以这两个因素组成的「HMM 概念混合体」非常关键。
最后我们总结一下基于贝叶斯推理的 ICL:
- 由 concept、prompt 得出 output 的先验概率 $P(\text {output} \mid\text {prompt})$。
- prompt 与 concept 的似然度 $P(\text {concept}\mid\text {prompt})$。
- 给定 prompt 得到 output 的后验概率 $P(\text {output} \mid \text {concept}, \text {prompt})$。
第 15 节 · ICL 是如何工作的?(2022 年 2 月)
2022 年 2 月华盛顿大学、Meta 和 AI2 的几位作者在论文《Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?》中,从实验验证角度深入地探索了 ICL 背后,到底是 prompts 中的什么起到了作用。
首先我们先明确在 ICL 中输入的内容里,每一部分都是啥,并且明确下名称,避免歧义。我们先看下图:

整体输入是由 1 组 demonstrations 和 1 个 test sample 组成的。在这组 demonstrations 中的每一个都是 input-label pair,input 和 label 之间的存在映射(mapping)关系。

以下是一些显性的部分:
- 后面船涨会提到「Circulation revenue has increased by 5% in Finland」这句是 demo 中的 input;
- 对应的「Positive」是 demo 中的 label;
- input 和 label 组成的就是 demo;
- 类似「The acquisition will have an immediate positive impact」这样的就是一个 test example;
- 我们期待语言模型反馈给我们的对应 test example 的就是 output;
- 一组 demo 和一个 test example 组成的就是整个一个 prompt。
以下是一些隐性的部分:
- input 中整体文本输入分布 input distribution;
- label 的所有可能结果的值域空间 label space;
- 所有 input 整体与所有 label 整体之间的映射关系 input-label mapping;
- 整体 input、label 的 format,比如本节开头图里的例子,每个 demo 就是一句 input 一个
\n再一个 label。
通过一系列实验,研究人员得出一系列重要的结论,并普遍在 LLM 的使用中被认为正确,我们往下逐一看看。
15.1、Prompt 中的 Input-Label Mapping 不重要
这个结论是非常反直觉的,但是实验结果就是这样,我们来详细地看一下。
我们尝试看下随机打乱的 mapping 会带来什么影响。如下图,基于 12 种语言模型,对比在 prompts 中没有 demo 示例(下图中蓝色)、有 demo 示例且 golden label(你可以把 golden label 理解为人类监督下符合期望的 label,下图中的橙黄色)、有 demo 示例但 label 随机(下图中的红色)这 3 种情况。实验结果如下:

上图中,上面是分类问题,下面是多选问题。实验结果表明,随机 label 与 golden label 的表现差异并不大,但是远好于没有 demo 的情况。也就是说只要有 demo 就行,demo 中的 input-label mapping 没太大所谓。也就是,随机的 labels 虽然增加了噪声,但是并没有移除贝叶斯推理中的全部信号。
这里要强调的是,随机打乱的 labels 的值域分布空间还是与 golden labels 一样的,与下面要聊到的「label space」是不同的,后者是完全没有值域边界的一个值域空间。
15.2、Prompt 中的 Input Distribution 很重要
对于 input distribution 的验证,我们来对比两组:第一组就是来自训练数据里句子作为 demos 的 input,第二组是不服从分布的 (Out-Of-Distribution,OOD),具体说,是从其他外部语料库随机采样的一组句子 $x_{i, rand_{i=1}^k}$ 替换 demos 里的 $x_{i_{i=1}^k}$ 。这种情况下, label 都用 random, format 都不变,实验结果如下图:

每 4 个一组的柱状图里(具体说明在右侧),中间两个(Random labels 和 OOD + Random labels)的对比区别就是 input distribution 不同。可见除了 Direct MetaICL 模型之外,其他模型下这两组 input distribution 带来的结果表现差异是很显著的。
所以可以通过实验初步得出结论:input distribution 是有显著影响的。
15.3、Prompt 中的 Label Space 很重要
对于本小节开头的那个例子,正确的 Label Space 应该是 {Positive, Negative, Neutral} 这样的 Golden Label Space,而一个 Label Space 不分布在正确值域里的情况,可以是一些完全无关的、随机的,比如上面例子里可以出现 Unanimity、Wave、Guana、Syrup … 类似的 Random Label Space。

每 4 个一组的柱状图里,中间两个(Random Labels 和 Random English Words)的对比区别就是 Label Space 不同。前者是 Golden,后者是 Random,可见在 Direct 模型里有显著差异,但是在 Channel 模型里几乎表现差不多。
所以可以通过实验初步得出结论:label space 是有显著影响的。
15.4、Prompt 中 Format of Demonstration 很重要
我们可以设置很多种不同的 format 来对比,但这里为了更简单、直接说明问题,我们将用 no labels 和 with labels only 两种 formats,如下:

将这两种 formats 来和「input with random label」format 做对比(因为通过前面的实验,我们可以认为 input-label mapping 是不显著影响的,所以用 random label 且 label space 是正确的)。实验结果如下:

每 7 个一组的柱状图里,分别对比了 7 种情况,我们这里看每一组的第 2、4、6 个柱状图。可以看出 no labels 和 with labels only 两种 formats 的表现都显著低于 random labels。
所以可以通过实验初步得出结论:使用 input-label 作为 demo 的 format 对于模型表现有显著提升作用。
15.5、小结一下
在基于 ICL 能力来用好 LLM 时,我们有以下 learning:
- 在 prompt 里带上 demo 是很重要的,而且 demo 在形式上 input 和 label 都需要。
- 对于 demo 中的 input,不要乱来,要给出比较合理的 input。
- 对于 demo 中的 label,只要它属于正确的值域空间 label space 就可以了,是否与 input 有 correct mapping 不重要。
由此指导我们在实践中,给出尽量多的 demonstrations 时,不需要人工标注每个 input 有正确的 label,而是对于每个 input 可以批量化随机地给出符合 label space 的 label 即可,实现在下游任务上人工标注成本的下降。
但是关于本节的各项研究结论,目前还有很多是基于假设之上推演 + 实验的,并非如「理论科学」那么严谨,可以和船涨一起持续关注后续学界与业界对于 ICL 的最新进展。
第 16 节 · 思维链(Chain of Thought,CoT,2022 年 1 月)
16.1、深度学习就是要从 System-1 走向 System-2
在认知科学里,有一个「认知双通道理论」,讲的是人脑有两套系统,即「系统 1」和「系统 2」[14]:
- 系统 1(System-1)常被称为直觉系统,它的运行是无意识且快速的,不怎么费脑力,没有感觉,完全处于自主控制状态。
- 系统 2(System-2)常被称为逻辑分析系统,它将注意力转移到需要费脑力的大脑活动上来,例如复杂的运算。系统 2 的运行通常与行为、选择和专注等主观体验相关联。
该理论由心理学家基思·斯坦诺维奇(Keith Stanovich)和理查德·韦斯特(Richard West)率先提出。后被行为经济学之父、诺贝尔奖获得者丹尼尔·卡尼曼(Daniel Kahneman)引用在其著作《思考,快与慢》中,而被心理学领域之外的人广泛所知,我上述的表述也引自该书。
图灵奖得主 Yoshua Bengio 在 2019 年人工智能顶级会议 NeurIPS 的题为《From System 1 Deep Learning To System 2 Deep Learing》报告中引用该理论,被 AI 圈子很多人误以为这个理论是 Yoshua Bengio 提出的(而 Yoshua 误以为这是 Kahneman 提出的)。但是 Yoshua 很有价值地指出:
- System-1 是目前深度学习正在做的事情 —— Current DL,比如图像识别、人脸识别、机器翻译、情感分类、语音识别、自动驾驶等。
- System-2 是未来深度学习将要做的事情 —— Future DL,比如推理、规划等任务,这些任务基本都是有逻辑的(logical)、可推理的(reasoning)。
LLM 的研究者们也在探究那些 System-2 要解决的任务,于是有了下面船涨了解到的几个技术方向,与大家分享探讨。
16.2、Google 提出思维链提示(CoT Prompting)
尽管在语言建模方面,现有模型表现还可以,NLP 领域的 System-1 任务基本还算比较好的解决,但是对于 System-2 基本上都没有太好的进展。但 GPT 出来后这事儿变得不一样了,尤其是 InstructGPT。我们往下慢慢看。
2022 年初 Google 在论文《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》中提出「思维链(Chain of Though,CoT)」:研究发现通过在 prompts 中增加思维链(即一系列中间推理步骤),就能显著提升 LLM 的推力表现。并将这种提示方式称为「Chain of Thought prompting」。

比如如上示例,标准的提示中给了一对问答样例,再加上一个问题,让 LLM 返回问题的答案。CoT Prompting 则在那对问答样例中加上了一段 CoT,而不是直接给出「The answer is 11.」上图展示了这样两种 prompting 及对应输出的案例。在不同的模型上,这两种 prompting 方式。
16.3、Let’s Think Step by Step
2022 年 5 月三位东京大学学者与两位 Google 的研究人员在论文《Large Language Models are Zero-Shot Reasoners》中提到了后来在 Gen-AI 领域那句著名的提示 —— Let’s think step by step —— 对于涉及到逻辑推理方面的问题,通过增加这句提示后,模型展现出了推理性能的大幅跃升。
对于 OpenAI 的 InstructGPT(具体地,是 text-davinci-002)模型,在输入提示时加上「Let’s think step by step」后,其表现:
- 在 MultiArith 数据集上,准确率从 17.7% 提升到 78.7%
- 在 GSM8K 数据集上,准确率从 10.4% 提升到 40.7%
对于 Google 的 PaLM 模型(具体地,参数规模为 5400 亿),同样的输入提示改造,其表现:
- 在 MultiArith 数据集上,准确率从 25.5% 提升到 66.1%
- 在 GSM8K 数据集上,准确率从 12.5% 提升到 43.0%
事实上,除了「Let’s think step by step」,该论文的作者们还尝试了一系列其他 prompts 的插入,只不过这句的表现最好:

从这里我们可以看到,对于 CoT 的挖掘体现了我们对 LLM 的了解仍然处于非常早期的阶段。如果未来船涨会更新本篇文章的新版本,我认为在 ICL、CoT 部分一定会有很多新进展出现。而随着我们对 LLM 为什么具备 ICL 能力的研究加深,更好地。
本小节参考
- https://arxiv.org/abs/2107.13586
- https://arxiv.org/abs/2001.07676
- https://zhuanlan.zhihu.com/p/399295895
- https://arxiv.org/abs/2104.08691
- https://aclanthology.org/2021.acl-long.353.pdf
- https://zhuanlan.zhihu.com/p/551174711
- Towards Understanding In-context Learning, Sam Liang & Kevin Jin, Princeton University.
- https://zhuanlan.zhihu.com/p/524383554
- https://zhuanlan.zhihu.com/p/551014127
- How does in-context learning work? A framework for understanding the differences from traditional supervised learning
- An Explanation of In-context Learning as Implicit Bayesian Inference
- Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?
- https://zhuanlan.zhihu.com/p/493533589
第四章 · LLM 发展关键节点与主流模型(2022 - 2023)
第 17 节 · InstructGPT:为对齐(Alignment)而生的指令式 GPT(2022 年 3 月)
GPT-3 上线并商业化后,半年后(到 2021 年 3 月)有 300 余款基于它的 API 开发的应用。OpenAI 认为自己在开创下一代应用生态。但是遇到的一个严重问题是,GPT-3 的输出存在不可信、有害等内容。为了解决这个问题,OpenAI 将「对齐研究(Alignment Research)」作为其技术研发重点之一[3]。在该公司 2022 年 1 月底的 blog 中提到,他们已经研究 alignment 好几年了,但 InstructGPT 是他们第一次把它用到产品里。
17.1、对齐(Alignment):关于「我们到底要 AI 未来变成什么样子」这件事儿
所谓「AI 对齐」,就是 AI 要语言模型的输出应该向人类使用者对齐。关于具体地,OpenAI 想用人类指令(Instruct)作为输入,AI 根据指令输入,返回符合人类价值观的输出。对于 Alignment,Anthropic 在其论文《A General Language Assistant as a Laboratory for Alignment》中给出了该公司在 AI 对齐上的理念:有用(helpful)、可信(Honest)、无害(Harmless),比较被广泛接受。目前围绕 Alignment,业内 Anthropic 和 OpenAI 是走在比较前沿的两家公司,尤其前者。
所以可以看出,「AI Alignment」其实是「AI Safety」的一个子领域,国内所有做安全、合规、技术道德相关方向的朋友都要重视起来,关于 AI Alignment 或许我可以单独写一篇文章来和大家交流。
为了实现这一点,需要将人类对于文本内容是否为人类所需的判断,被 AI 学习会,于是最初 OpenAI 想到的是用监督微调(Supervised Fine-Tune)的方法,基于此推出了 davinci-instruct-beta,就是对一些 OpenAI 收集的用户 prompts 输入,由人类给出输出,这些 prompt-generation pairs 拿来 fine-tune 原来的 GPT-3。但是这样其实并没有明示 AI,只是「暗戳戳」地让它学习。
其实我们想要的是,与人类对齐的输出结果,是好的输出;与人类不对齐的输出结果,不是好的输出;所以输出好与不好,这里可以做一个奖励模型来评判。而用这个奖励模型来训练一个语言模型,就是用强化学习的思路了。于是 OpenAI 选择通过「人工反馈的强化学习(Reinforcement Learning with Human Feedback)」来实现这一点,就在 GPT-3 的基础上研发了 InstructGPT。
17.2、如何用 RLHF 方法训练得到更能对齐人类的 InstructGPT?
用 RLHF 方法得到 InstructGPT 的具体流程,OpenAI 官方给出了如下解释[2]:

第一步,是监督微调(Supervised Fine-Tune,SFT)出一个对齐人类的初始模型。OpenAI 把这个模型叫做「监督策略(Supervised Policy)」,因为用 RLHF 来实现 Alignment 的目的就是为了用「对齐策略」把 AI 给「管」起来。
- 首先,从 GPT 开放使用后收集的用户输入提示(prompts)中取用一部分提示,根据 OpenAI 的说法其采用的数据是来自官网 Playground 工具收集的提示(具体来说,用的数据来自 2021 年 OpenAI 部署的 GPT 版本所收集),并去掉了其中涉及到隐私/个人信息的内容[2]。
- 然后,由人类为它们来编写一些输出样例(demonstration)。
- 接着,用这些监督数据(一些 prompt-demonstration pairs)去微调 GPT-3。
第二步,训练一个对齐人类的奖励模型(注意第一步、第二步是两个独立的模型),这是强化学习中不可或缺的。
- 首先,基于用户提示(与 SFT 那一步用的 prompts 是相同来源)从多个模型得到多个输出。
- 然后,人类标注员(labelers)对不同的结果进行排序(注意不是打分)。
- 最后,将不同模型的输出结果和排序结果作为训练数据,训练一个奖励模型(Reward Model,RM)。训练成功后,这个 RM 就有了衡量输出表现的能力。
第三步,用第二步的奖励模型,以强化学习 PPO 方法训练第一步得到的初始模型(监督政策)。
- 将训练集数据输入给初始模型(监督政策),得到相应的输出。
- RM 对初始模型的输出计算奖励。
- 基于奖励值,用 PPO 算法更新监督政策。
这个流程下来,「对齐」体现在哪里了呢?基本上需要人工的地方,就是在「对齐」。
- SFT 的第一步,用的是「符合人类期望行为的样例(demonstrations of the desired model behavior)」。
- 训练 RM 的第二步,排序判断来自人类。
根据 OpenAI 发表的《Training language models to follow instructions with human feedback》,用 RLHF 方法得到的 13 亿参数规模的 InstructGPT 的表现要优于 1750 亿参数的 GPT-3。这是非常令人吃惊的结果,换句话说,1750 亿参数的 GPT-3 的能力并没有被很好的挖掘 —— 它有学习能力,但是人类没有教好。
到这里我们能看到,RLHF 的方法一定非常适合做领域垂直化的训练,只需要雇佣一批垂直领域的「专家」来做标注员(labelers)来训练初始模型和奖励模型就可以。所以现在类似 ChatGPT 这种 LLM 对事实类知识处理得不太好的领域,都有 RLHF 做基础训练方法得到可用产品的机会。
还值得一提的是,测试 InstructGPT 在 Alignment 方面表现的两个数据集可以关注一下:
- 测模型谎言多少的数据集:TruthfulQA: Measuring how models mimic human falsehoods. Lin, S., Hilton, J. and Evans, O., 2021.
- 测模型有害程度的数据集:RealToxicityPrompts: Evaluating neural toxic degeneration in language models. Gehman, S., Gururangan, S., Sap, M., Choi, Y. and Smith, N.A., 2020.
17.3、对齐税(Alignment Tax)
目前从实际表现看,只在客户任务上对齐模型,可能会让模型在其他一些学术任务上的表现更差,我们把这种代价叫做「对齐税(Alignment Tax)」。OpenAI 提到一种最小化对齐税的小 trick:在强化学习第一步微调的时候,混入一点训练 GPT-3 时用到的原始数据,然后微调训练时用正则对数极大似然函数(Normal Log Likelihood Maximization)做 loss 函数。这种方式既能大概保持在客户任务方面的性能,也能缓解学术任务上的表现下降,在某些情况下甚至超过了 GPT-3。
17.4、目前 InstructGPT 的局限性
- 听话与拒绝:训练模型 follow instructions 的一个副产品就是 —— 太听话也不是好事儿 —— 如果指令产生了不好的内容,模型可能更容易被滥用。解决方法是模型要会明确拒绝某些指令。
- 文化兼容性不足:InstructGPT 是用英文指令训练的,因此它偏向于英语使用者的文化价值观。
17.5、InstructGPT 就是 GPT-3.5 吗?
InstructGPT 不等于 GPT-3.5。GPT-3.5 是 OpenAI 用 2021 年第四季度之前的文本、代码训练的。OpenAI 在其官网[10]明确指出,目前 OpenAI 公开的 API 中:
- 你能用到的 InstructGPT 模型有
davinci-instruct-beta、text-davinci-001,text-davinci-002,text-curie-001,text-babbage-001、text-davinci-003。 - 你能用到的 GPT-3.5 模型有
code-davinci-002、text-davinci-002、text-davinci-003。
在 2022 年 1 月底,OpenAI 官方说这个 align 过的 InstructGPT 模型已经在 OpenAI 线上的 GPT API 里跑了一年多了,只是没告诉大家。
第 18 节 · ChatGPT:基于 RLHF 训练的对话式 GPT 模型(2022 年 11 月底)

InstructGPT 是基于人类指令输入,给予对应的输出结果,OpenAI 将它迭代用在了其官网的 Playground 产品里。但发送指令这种方式,其实还不是人类最自然的方式。秉承 Alignment 的理念,为了让交互方式更符合人类的习惯,OpenAI 希望打造基于对话 ———— 人类最熟悉的交流方式 ———— 进行输入输出交互的语言模型,于是有了 ChatGPT。
18.1、ChatGPT 的训练方法
训练方法上,OpenAI 称 ChatGPT 与 InstructGPT 的 RLHF 方法相同,只是数据集设置方面有一点区别。下面是 OpenAI 官方其在 ChatGPT 研发中使用的 RLHF 流程:
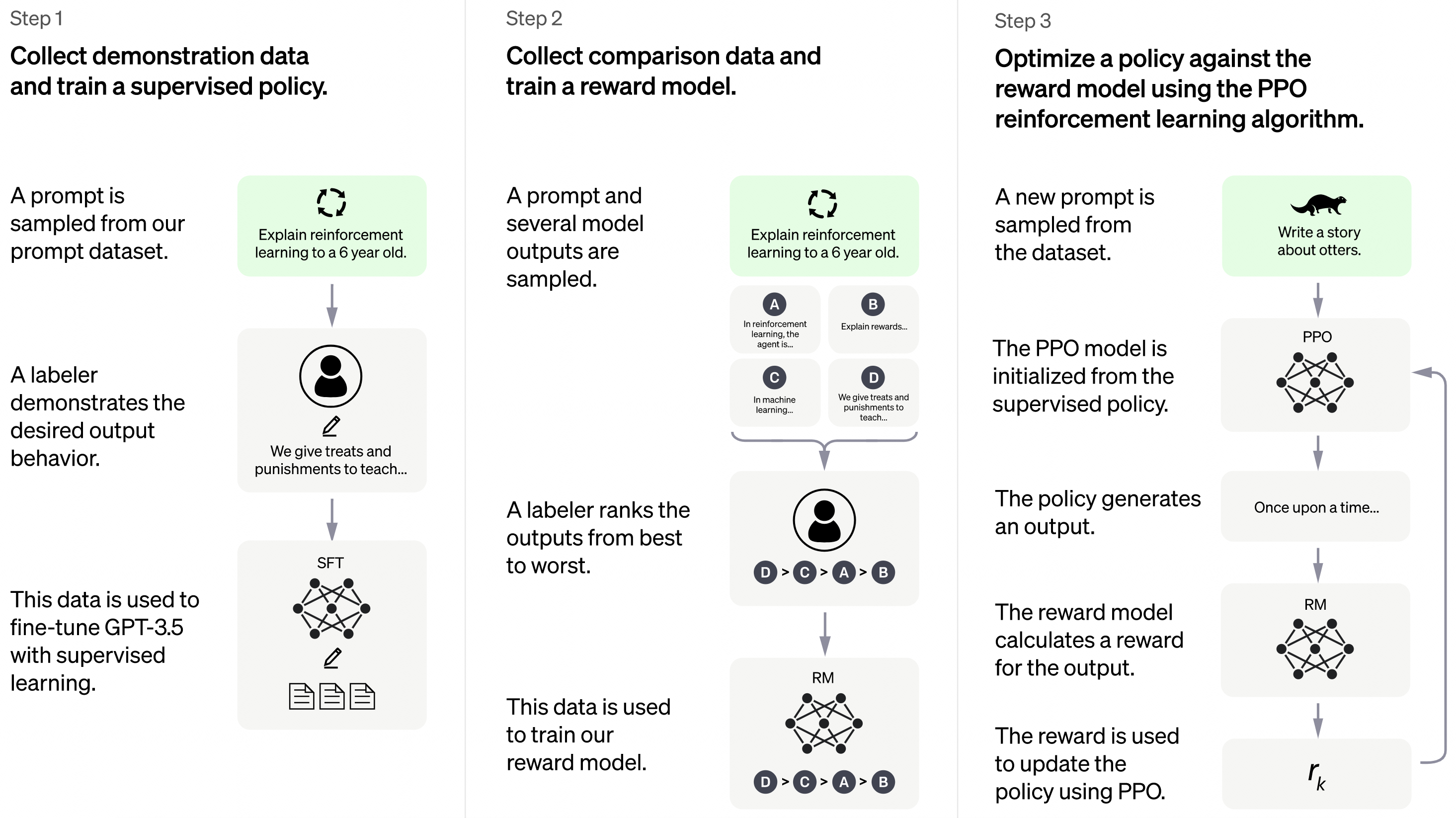
第一步,监督微调(SFT),方法与 InstructGPT 是相同的,但是数据上略有差异。
- 在 InstructGPT 所用的 SFT 数据集基础上,ChatGPT 还收集了一些人类编写的对话(对话的双方内容都由人类训练师提供,训练师既扮演用户,也扮演 AI 助手)。
- 然后,把这些监督数据(prompt-demonstration pairs)与 InstructGPT 训练用的数据集混合起来,并从「指令(Instruct)」全部改成「对话(Chat)」模式。
- 接着,用这些数据来微调(fine-tune)GPT-3.5。(注:所以我们看到 OpenAI 说的是基于 GPT-3.5 研发的 ChatGPT,而不是 ChatGPT 等于 GPT-3.5。)
第二步,奖励模型(RM)的构建过程中,产出训练数据所需的结果排序时,迭代为排序中不可以有排位相等的情况,而是全部要区分开。
第三步,与 InstructGPT 流程相同,就是用第二步的 RM 以 PPO 强化学习方法来训练第一步 SFT 得到的原始模型(监督策略)。
18.2、ChatGPT 与 InstructGPT 的主要技术区别
- 训练数据来源不同:ChatGPT 所用的训练数据,是在 InstructGPT 所用训练数据的基础上,混入了人类训练师编写的对话数据。
- 训练数据格式不同:InstructGPT 的训练数据用的还是「指令-响应」的格式,而训练 ChatGPT 时 OpenAI 将数据转换成「对话」格式。
- 基础模型版本不同:InstructGPT 是基于 GPT-3 微调的,ChatGPT 是基于 GPT-3.5 微调的。
18.2.1、训练数据的格式
SFT 时用的数据,ChatGPT 是基于 InstructGPT 数据集改的。
具体来说,比如 InstructGPT 有如下指令数据集:
1 | Make a sandwich. |
这每一个 Instruct 都会有一个 respond,根据 OpenAI 的解释,在 InstructGPT 中,AI 训练师编写了这些「指令-响应」对(指令和响应都是人工编写的),而 ChatGPT 把这些对儿改为了对话形式,举例如下:
1 | User: Make a sandwich. |
然后将 AI 的部分做文本生成任务的 SFT。
18.3、ChatGPT 开放 Chat API
我在 2023 年 3 月 2 日写了一篇简单的入门 ChatGPT 官方 API 文档解读。
本次 OpenAI 在其 GPT 系列模型 Davinci、Curie、Babbage、Ada 之外,推出了 Turbo 模型,是比 Davinci 性能还要强的。Turbo 与支持 ChatGPT 的模型系列相同,它针对对话式聊天输入和输出进行了优化,但与 Davinci 模型系列相比,它在完成方面同样出色。在 ChatGPT 中可以很好地完成的任何用例都应该在 API 中与 Turbo 模型系列一起很好地执行。Turbo 模型家族也是第一个像 ChatGPT 一样接收定期模型更新的模型。Turbo 适合于对话、文本生成。
OpenAI 发布的 ChatGPT 模型系列 GPT-3.5-turbo 与 ChatGPT 产品中使用的模型相同。但是它的价格为每 1k tokens 0.002 美元,比 OpenAI 现有的 GPT-3 模型便宜 10 倍。即使对于许多非聊天用例,它也是 OpenAI 的最佳模型 —— 如果你之前就用了 text-davinci-003,那么迁移到 gpt-3.5-turbo 时只需要对他们的提示进行少量调整。
OpenAI 在本次开放中额外增加或更新了如下模型:
gpt-3.5-turbo:功能最强大的 GPT-3.5 模型并针对聊天进行了优化,成本仅为text-davinci-003的 1/10。将使用我们最新的模型迭代进行更新。gpt-3.5-turbo-0301:2023 年 3 月 1 日的gpt-3.5-turbo快照。与gpt-3.5-turbo不同,此模型不会收到更新,并且仅在 2023 年 6 月 1 日结束的三个月内提供支持。text-davinci-003:此前 GPT-3 期间就有的 Davinci 模型,这次直接升级到了 GPT-3.5,与 GPT-3 阶段一样,仍然是最大请求 4000 tokens,同样训练数据 up to 2021 年 6 月,能做几乎所有 NLP 任务。text-davinci-002:与text-davinci-003类似情况,这次直接升级到了 GPT-3.5,专门为了代码生成任务优化的模型。与 GPT-3 阶段一样,仍然是最大请求 4000 tokens;训练数据也没有变,依然是 up to 2021 年 6 月。
而以下模型不再由 GPT-3 提供支持:
text-davinci-003:此前在 GPT-3 接口中存在,本次更新后由 GPT-3.5 支持提供了,见上一段。
目前已经有基于不少 Chat API 的应用在网上开始出现,比如下面这个:
- 支持 epub 的双语阅读器(开源):https://github.com/yihong0618/bilingual_book_maker
第 19 节 · 其他一些近期值得关注的模型
19.1、LLaMA:Meta 对 ChatGPT 的回应
2023 年 2 月 25 日 Meta AI 在其官网公开发布了 LLaMA(Large Language Model Meta AI)大型语言模型,包括 70 亿、130 亿、330 亿、650 亿 4 种参数规模,旨在推动 LLM 领域的小型化、平民化研究。在其论文《LLaMA: Open and Efficient Foundation Language Models》中声称用不到 GPT-3 的 1/10 参数规模就超越其表现。下面是参数规模对比:

与 GPT-3 模型对比可以看出,LLaMA 的四个版本中:
- LLaMA-7B 对应的是 GPT-3 6.7B 版本,都是 32 层、32 个多头注意力、4096 宽度,LR 3.0E-4 要高于 GPT 的 1.2E-4,batch 4M 更大。
- LLaMA-13B 对应的是 GPT-3 13B 版本,都是 40 层、40 个多头注意力,模型宽度 5120、5140 差不多,LR 3.0E-4 也高于 GPT 的 1.0E-4,batch 4M 更大。
- LLaMA-33B、LLaMA-65B 与 GPT-3 就没有对应了,都是仅次于 GPT-3 最大的 175B 版本。Meta AI 也是为了证明,更小的模型也能达到甚至超越 GPT-3 暴力大模型,这也是推动模型小型化的一个动力。
跟 GPT 系列一样,LLaMA 也是采用 Transformer Decoder 的自回归语言模型架构,但是做了一些小改进(可以说并没有太多创新),此前船涨已发布过一篇快速解读 LLaMA 的文章《Meta 推出开源 LLaMA,用 1/10 参数规模打败 GPT-3,群「模」乱舞的 2023 拉开序幕》,这里说下其模型架构的小改进有什么:
- 从 GPT-3 得到启发的 Pre-normalization:为了增强训练的稳定性,将只在输出层的 normalization 改成了 Transformer 里面每一层的输入都进行 normalize,具体用的是 Zhang and Sennrich (2019) 提到的 RMSNorm。
- 从 PaLM 得到启发的 SwiGLU 激活函数:用 Shazeer(2020) 提到的 SwiGLU 激活函数替换了大家熟悉的 ReLU 激活函数。
- 从 GPT-Neo 得到启发的 RoPE:在 Transformer 位置编码部分,没有用绝对位置编码(Absoute Positional Embeddings),而是用的 Su et al.(2021) 提到的 RoPE(Rotary Positional Embeddings)。
可以说模型的改进并没有亮点。再看下 LLaMA 用到了如下这些训练数据集,并给出了相应的占比:
- CCNet:67%.
- C4:15%,NLP 领域的人也基本知道了,全称是 Colossal Common Crawl Corpus,最早大家了解到它基本是通过 Google T5 模型的那篇论文《Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer》。作为对比,GPT-3 中的 60% 数据来自 Common Crawl,不过 GPT-3 对其 Common Crawl 的数据以及此前 OpenAI 在 GPT-2 用的 WebText 作为训练数据参照对 Common Crawl 数据进行了正类、负类的分类清理,不过还不是 C4。
- GitHub:4.5%,开源代码仓库平台,目前已经是 Microsoft 自己的了。
- Wikipedia:4.5%,之前 GPT-3 就用了 English Wikipedia。
- Books:4.5%,作为对比 GPT-3 的数据源中 16% 来自书籍。
- ArXiv:2.5%,是学界最熟悉的开放电子学术论文存档库,由康奈尔大学于 1991 年成立。
- Stack Exchange:2%,类似于 Stack Overflow 的、针对程序员群体的在线技术问答社区。
起初的邀请制被后来有人发布到 GitHub 和 HuggingFace 给破坏了,不过此前 LLaMA 已经说了开源,所以这也只是大家帮助 Meta 推进下速度吧。但是目前 LLaMA 缺少 RLHF 的加持,同时从目前各开发者使用反馈来讲举例 GPT-3 有差距。无论如何还是感谢 Meta 为 AI 开源做出贡献,期待后面在开源社区的努力下模型变得更加鲁棒和 SOTA。
19.2、其他一些近期值得关注的、创新性 LLM
- Claude:由 OpenAI 的离职员工组成的 Anthropic 人工智能公司开发,暂未公开。与 OpenAI 提出的 RLHF 针锋相对地,在 2022 年 12 月于论文《Constitutional AI: Harmlessness from AI Feedback》提出基于 AI 反馈的强化学习(Reinforcement Learning with Artificial Intelligence Feedback,RLAIF),同时提出 Constitutional AI 概念,并基于此开发了 Claude,一个与 ChatGPT 类似但采用了 RLAIF 的 LLM 对话产品。
- ChatRWKV:一个中国团队开发的、完全基于 RNN 架构的、开源对话系统,目标是最终可以在个人设备上运行。
第五章 · 未来技术趋势的关注重点及一些推荐参考
第 20 节 · 未来技术趋势的关注重点
- 对齐(Alignment)与 Moderation
- 模型小型化
- 技术资产私有 与 架构分层:知识是如何存储、如何修改
- Prompt Engineering
- 未来衡量 LLM 也需要提出新的 benchmark,既有的这些测试打榜并不满足需求。
- GPT 在 few-shot learning 时到底是现学的,还是找到原来学过的相似的东西找出来。如果是后者,那真的是在拼训练数据大小了。但是对比人类,我们应该要做到前者才对。
第 21 节 · 一些推荐
21.1、关键论文
- 2017.06 《Attention Is All You Need》来自 Google,提出 Transformer。
- 2018.02 《Deep contextualized word representations》 来自 AI2,提出 ELMo。
- 2018.06 Improving Language Understanding by Generative Pre-Training来自 OpenAI,提出 GPT-1
- 2018.10 《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》来自 Google,提出 BERT。
- 2019.02 《Language Models are Unsupervised Multitask Learners》来自 OpenAI,提出 GPT-2
- 2019.10 《Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer》来自 Google,提出 T5 模型。
- 2020.01 《Scaling Laws for Neural Language Models》来自 OpenAI,提出 Scaling Laws。
- 2020.01 《Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference》来自慕尼黑大学,提出 PET。
- 2020.05 《Language Models are Few-Shot Learners》来自 OpenAI,提出 GPT-3。
- 2021.04 《The Power of Scale for Parameter-Efficient Prompt Tuning》来自 Google,提出 Prompt Tuning。
- 2022.01 《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》 来自 Google,提出 CoT。
- 2022.03 《Training language models to follow instructions with human feedback》来自 OpenAI,提出 InstructGPT。
- 2022.05 《Large Language Models are Zero-Shot Reasoners》来自东京大学和 Google,提出著名提示语「Let’s think step by step」。
- 2022.12 《Constitutional AI: Harmlessness from AI Feedback》来自 Anthropic,提出 Constitutional AI。
- 2023.02 《LLaMA: Open and Efficient Foundation Language Models》来自 Meta,提出 LLaMA。
21.2、值得关注的重要机构
- OpenAI:2018 年推出 GPT-1,2019 年推出 GPT-2,2020 年推出 GPT-3,2021 年推出 Codex(用户侧产品是 GitHub CoPilot),2022 年初推出 InstructGPT,2022 年底推出 ChatGPT 用户产品,2023 年 3 月开放 ChatGPT API。
- Microsoft:目前已成为 OpenAI 背后的大金主,对其各模型都有开放访问权限并向 Microsoft 既有产品线整合。尽管如此,Microsoft 和 NVidia 一起联合推出过 Megatron-Turing。
- Google 和 DeepMind:2017 年提出 Transformer,2018 年推出 BERT,2019 年提出 T5,2021 年推出 FLAN、LaMADA,2022 年推出 Chinchilla、PaLM、Sparrow。
- Facebook(aka Meta):2019 年推出 RoBERTa,2020 年推出 BART,2022 年推出 OPT、BlenderBot3、Galactica。
- Allen Institute for AI(AI2):其提出了著名的 ELMo 模型;
- 阿里:2021 年推出 1000 亿参数的 M6;
- 华为:2021 年推出 2000 亿参数的 Pangu-alpha;
- 百度:2021 年推出 2600 亿参数的 Ernie 3.0 Titan;
- Salesforce:推出 CodeT5、CodeRL;
- BigScience Research Workshop;2022 年推出开源的 BLOOM。
- EleutherAI:推出 GPT-neox 20B;
- Character.AI;
- Anthropic:OpenAI 早期员工离职创办,其 Claude AI 暂未开放访问。
21.3、推荐关注的博客或 Twitter
- OpenAI 公司官网的 blog
- Hugging Face 公司官网的 blog
- Jay Alammar 的 blog,写了一系列非常棒的 Illustrated Models 文章
- Leo Gao,博主是 OpenAI 的 Alignment Researcher
- @sama,Sam Altman,OpenAI 公司联合创始人 & CEO
- @gdb,Greg Brockman,OpenAI 公司联合创始人 & 总裁
- @ylecun,Yann LeCun,Meta 首席 AI 科学家
- @karpathy,Karpathy,特斯拉前人工智能总监,李飞飞在 Stanford 的助教
- @danqi_chen,康奈尔大学计算机科学助理教授
- @sewon__min,华盛顿大学计算机科学与工程 Ph.D. 学生
- @Zhou_Yu_AI,哥伦比亚大学计算机科学助理教授
- @nabla_theta,Leo Gao,OpenAI 公司 Alignment Researcher
- @sangmichaelxie,斯坦福大学 Ph.D. 学生
- @AlecRad,Alec Radford,OpenAI 研究员,GPT-1 / GPT-2 / GPT-3 的作者之一
- 刘鹏飞
- 张俊林
为什么现在的大语言模型(LLM)都是Decoder-only的架构?
LLM 是“Large Language Model”的简写,目前一般指百亿参数以上的语言模型,主要面向文本生成任务。跟小尺度模型(10 亿或以内量级)的“百花齐放”不同,目前 LLM 的一个现状是 Decoder-only 架构的研究居多,像 OpenAI 一直坚持 Decoder-only 的 GPT 系列就不说了,即便是 Google 这样的并非全部押注在 Decoder-only 的公司,也确实投入了不少的精力去研究 Decoder-only 的模型,如 PaLM 就是其中之一。那么,为什么 Decoder-only 架构会成为 LLM 的主流选择呢?
知乎上也有同款问题《为什么现在的 LLM 都是 Decoder only 的架构?》[1],上面的回答大多数聚焦于 Decoder-only 在训练效率和工程实现上的优势,那么它有没有理论上的优势呢?本文试图从这个角度进行简单的分析。
统一视角
需要指出的是,笔者目前训练过的模型,最大也就是 10 亿级别的,所以从 LLM 的一般概念来看是没资格回答这个问题的,下面的内容只是笔者根据一些研究经验,从偏理论的角度强行回答一波。
我们知道,一般的 NLP 任务都是根据给定的输入来预测输出,完全无条件的随机生成是很少的,换句话说,任何 NLP 任务都可以分解为“输入”跟“输出”两部分,我们可以把处理“输入”的模型叫做 Encoder,生成“输出”的模型叫做 Decoder,那么所有任务都可以从“Encoder-Decoder”的视角来理解,而不同模型之间的差距在于 Encoder、Decoder 的注意力模式以及是否共享参数:

这里的 GPT 就是 Decoder-only 的代表作;UniLM 则是跟 GPT 相似的 Decoder 架构,但它是混合的注意力模式;T5 则是 Encoder-Decoder 架构的代表作,主要是 Google 比较感兴趣。
Google 在 T5 [2] 和 UL2 [3] 两篇论文中做了较为充分的对比实验,结果均体现出了 Encoder-Decoder 架构相比于 Decoder-only 的优势,但由于从 LLM 的角度看这两篇论文的模型尺度都还不算大,以及多数的 LLM 确实都是在做 Decoder-only 的,所以这个优势能否延续到更大尺度的 LLM 以及这个优势本身的缘由,依然都还没有答案。
对比实验
从上表可以看出,其实 GPT 跟 UniLM 相比才算是严格控制变量的,如果 GPT 直接跟 T5 相比,那实际上产生了两个变量:输入部分的注意力改为双向以及参数翻了一倍。而之所以会将它们三个一起对比,是因为它们的推理成本大致是相同的。
相比 GPT,既然 T5 有两个变量,那么我们就无法确定刚才说的 Encoder-Decoder 架构的优势,究竟是输入部分改为双向注意力导致的,还是参数翻倍导致的。为此,笔者在 10 亿参数规模的模型上做了 GPT 和 UniLM 的对比实验,结果显示对于同样输入输出进行从零训练(Loss 都是只对输出部分算,唯一的区别就是输入部分的注意力模式不同),UniLM 相比 GPT 并无任何优势,甚至某些任务更差。
假设这个结论具有代表性,那么我们就可以初步得到结论:
输入部分的注意力改为双向不会带来收益,Encoder-Decoder 架构的优势很可能只是源于参数翻倍。
换句话说,在同等参数量、同等推理成本下,Decoder-only 架构很可能是最优选择。当然,要充分验证这个猜测,还需要补做一些实验,比如 Encoder 和 Decoder 依然不共享参数,但 Encoder 也改为单向注意力,或者改为下一节介绍的正反向混合注意力,然后再对比常规的 Encoder-Decoder 架构。但笔者的算力有限,这些实验就留给有兴趣的读者了。
低秩问题
为什么“输入部分的注意力改为双向不会带来收益”呢?明明输入部分不需要考虑自回归生成,直觉上应该完整的注意力矩阵更好呀?笔者猜测,这很可能是因为双向注意力的低秩问题带来的效果下降。
众所周知,Attention 矩阵一般是由一个低秩分解的矩阵加 softmax 而来,具体来说是一个 $n \times d$ 的矩阵与 $d \times n$ 的矩阵相乘后再加 softmax $(n \gg d)$ , 这种形式的 Attention 的矩阵 因为低秩问题而带来表达能力的下降,具体分析可以参考 《Attention is Not All You Need: Pure Attention Loses Rank Doubly Exponentially with Depth》[4].
而 Decoder-only 架构的 Attention 矩阵是一个下三角阵,注意三角阵的行列式等于它对角线元素之积,由于 softmax 的存在,对角线必然都是正数,所以它的行列式必然是正数,即 Decoder-only 架构的 Attention 矩阵一定是满秩的!满秩意味着理论上有更强的表达能力,也就是说,Decoder-only 架构的 Attention 矩阵在理论上具有更强的表达能力,改为双向注意力反而会变得不足。
还有个间接支持这一观点的现象,那就是线性 Attention 在语言模型任务上(单向注意力)与标准 Attention 的差距,小于它在 MLM 任务上(双向注意力)与标准 Attention 的差距,也就是说,线性 Attention 在双向注意力任务上的效果相对更差。
这是因为线性 Attention 在做语言模型任务时,它的 Attention 矩阵跟标准 Attention 一样都 是满秩的下三角阵;在做 MLM 任务时,线性 Attention 矩阵的秩比标准 Attention 矩阵更低 (线性 Attention 是 $n \times d$ 的矩阵与 $d \times n$ 的矩阵相乘,秩一定不超过 $d$ ,标准 Attention 是 $n \times d$ 的矩阵与 $d \times n$ 的矩阵相乘后加 softmax,softmax 会有一定的升秩作用)。
反过来,这个结论能不能用来改进像 BERT 这样的双向注意力模型呢?思路并不难想,比如在 Multi-Head Attention 中,一半 Head 的 Attention 矩阵截断为下三角阵(正向注意力),另一半 Head 的 Attention 矩阵截断为上三角阵(反向注意力);又或者说奇数层的 Attention 矩阵截断为下三角阵(正向注意力),偶数层的 Attention 矩阵截断为上三角阵(反向注意力)。
这两种设计都可以既保持模型整体交互的双向性(而不是像 GPT 一样,前一个 token 无法跟后一个 token 交互),又融合单向注意力的满秩优点。笔者也简单做了对比实验,发现正反向混合的注意力在 MLM 任务上是比像 BERT 这样的全双向注意力模型效果稍微要好点的:

坏消息是这实验的只是一个 base 版本(1 亿参数)的模型,更大模型的效果尚未清楚。
小结
所以,笔者作出的回答是:LLM 之所以主要都用 Decoder-only 架构,除了训练效率和工程实现上的优势外,在理论上是因为 Encoder 的双向注意力会存在低秩问题,这可能会削弱模型表达能力,就生成任务而言,引入双向注意力并无实质好处。而 Encoder-Decoder 架构之所以能够在某些场景下表现更好,大概只是因为它多了一倍参数。所以,在同等参数量、同等推理成本下,Decoder-only 架构就是最优选择了。
本篇其他参考
各章节内有单独的参考文献列表,未在其中标注出的,罗列如下:
- 人工智能 LLM 革命前夜:一文读懂横扫自然语言处理的 Transformer 模型
- AI 应用第一次大爆发来了:一文入门 ChatGPT 官方 API 文档解读
- Meta 推出开源 LLaMA,用 1/10 参数规模打败 GPT-3,群”模”乱舞的 2023 拉开序幕
- 麦克船长的 OpenAI 模型 API 官方文档入门解读
- 你可能已经听说 GPT-3,但是你也不能不知道 BERT —— 跟我一起用 BERT 跑个小用例
- ChatGPT: Optimizing Language Models for Dialogue
- Aligning Language Models to Follow Instructions
- Aligning AI systems with human intent
- Training language models to follow instructions with human feedback
- 《Artificial Intelligence: A Modern Approach, 4th edition》
- ChatGPT is not all you need. A State of the Art Review of large Generative AI models
- How does in-context learning work? A framework for understanding the differences from traditional supervised learning,
- https://mp.weixin.qq.com/s/h9c3w1af2uBYLlVbw7j82A
- Proximal Policy Optimization
- Model index for researchers
- Lambert, et al., “Illustrating Reinforcement Learning from Human Feedback (RLHF)”, Hugging Face Blog, 2022.
- Language Models are Few-Shot Learners
- 《思考,快与慢》丹尼尔 · 卡尼曼
- https://www.lesswrong.com/posts/midXmMb2Xg37F2Kgn/new-scaling-laws-for-large-language-models
- https://arxiv.org/abs/1910.01108
- https://www.microsoft.com/en-us/research/blog/turing-nlg-a-17-billion-parameter-language-model-by-microsoft/
- https://bmk.sh/2020/05/29/GPT-3-A-Brief-Summary/
- https://zhuanlan.zhihu.com/p/593962400
- https://xv44586.github.io/2023/01/09/zero-to-chatgpt/
- https://www.lesswrong.com/posts/midXmMb2Xg37F2Kgn/new-scaling-laws-for-large-language-models
- https://arxiv.org/abs/2203.15556
- https://spinningup.openai.com/en/latest/algorithms/ppo.html
- https://mp.weixin.qq.com/s/h9c3w1af2uBYLlVbw7j82A
- https://zhuanlan.zhihu.com/p/527423190
- https://arxiv.org/abs/1706.03762
- https://arxiv.org/abs/2112.0086
- https://zhuanlan.zhihu.com/p/493533589
- COS 597G (Fall 2022): Understanding Large Language Models
- https://zhuanlan.zhihu.com/p/395115779
- http://pretrain.nlpedia.ai
- https://lifearchitect.ai/whats-in-my-ai/
- https://zhuanlan.zhihu.com/p/611403556

