简介
转载于:Protégé基本教程【Protégé5.5.0版本】。
前言
Protégé软件是斯坦福大学医学院生物信息研究中心基于Java语言开发的本体编辑和知识获取软件,或者说是本体开发工具,也是基于知识的编辑器,属于开放源代码软件。这个软件主要用于语义网中本体的构建,是语义网中本体构建的核心开发工具,现在的最新版本为5.5.0版本。
Protégé提供了本体概念类,关系,属性和实例的构建,并且屏蔽了具体的本体描述语言,用户只需在概念层次上进行领域本体模型的构建。
现在下载到的Protégé一般是一个压缩包,压缩包解压之后有Protege.exe和run.bat这两个文件,点击任何一个都可以打开Protégé。Protégé一打开的界面主要是Active Ontology这个Tab的界面。

本体的名字可以在Ontology IRI里面修改。

Annotations是注释栏,可以对本体添加一些信息注释或者描述。右边Ontology metrics会显示一些本体中相关元素的统计信息。
在构建本体之前,可以定义本体里面的命名空间和前缀(prefix):

需要注意的是,在Ontology IRI里面的是http://www.pizza.com,而在前缀命名时多了一个“#”,即http://www.pizza.com#。这是因为在建模时默认会在前缀后添加一个“#”。例如新增的一个Class是“PizzaTopping”,那么在本体文件里面增加的是http://www.pizza.com#PizzaTopping http://www.w3.org/1999/02/22-rdf-syntax-ns#type http://www.w3.org/2002/07/owl#Class这样一个三元组,当我们设定前缀为pizza时,这个三元组可以简写为pizza:PizzaTopping rdf:type owl:Class。可以看到当我们新建一个本体文件时,owl、rdf、rdfs、xml、xsd都是默认存在的前缀和命名空间,因为这些命名空间里面提供的关键字都是构成本体的基本要素,大家注意不要删掉。
开始建立一个新的本体
建立本体主要在Entities这个Tab的界面下完成。一个最简单的本体需要完成类和对象属性的定义。

类的建立

类的添加、删除是在Class这个Tab下面完成的。Thing类是表示包含所有个体的集合的类。 因此,所有类都是Thing的子类。关于类,主要有三个操作:

需要注意的是,类的命名不可以重复。另外Protégé目前的版本对中文的兼容性还算比较高,但有些时候还是会出现中文显示为□的情况。在使用的过程中,推荐优先使用英文命名。通过类的操作,我们可以建立“Pizza(比萨)”,“PizzaBase(比萨饼底)”,“PizzaTopping(比萨饼面)”三个类。

在Class这个Tab界面的右下方是类的描述栏,相当于是对已有的类加一些限制。比如,对于某一个实例来说,它要么是PizzaBase,要么是PizzaTopping,这样就可以设置“Disjoint with”的关系,说明这两个集合是不相交的。
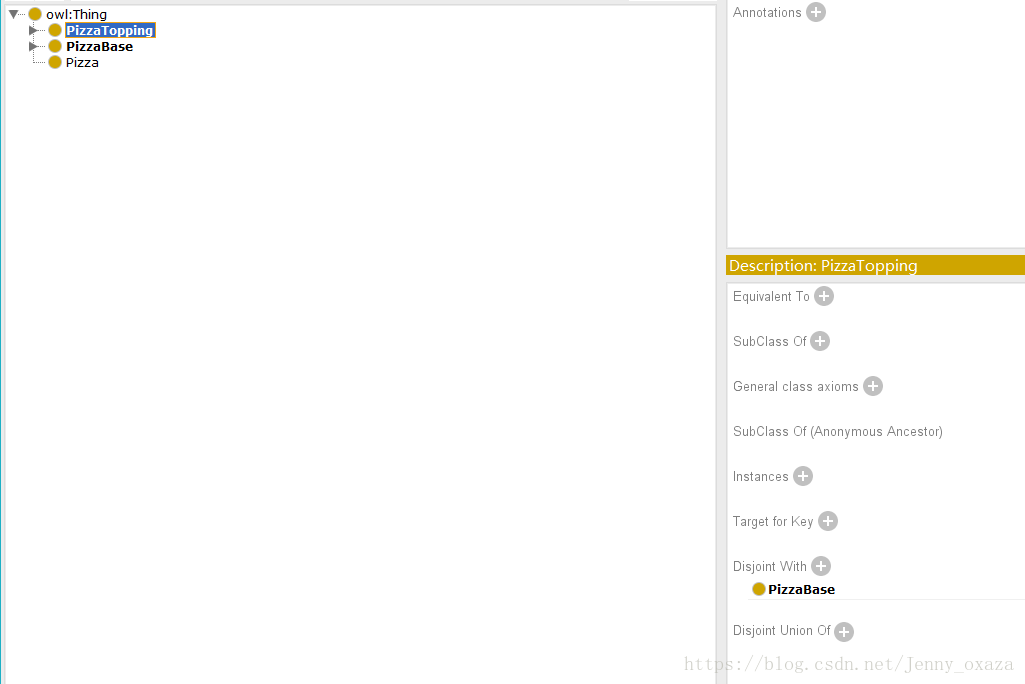
那么如果发现某一个实例既是PizzaBase,又是PizzaTopping,这种情况就是不允许的。这样的操作保证了类的严谨性。
接着,可以通过增加子类的操作完善本体的框架。比如比萨的饼底有薄饼和厚饼,比萨的饼面也有不同的口味。这样类之间的继承就是所谓的分类法。

如果在编辑的过程中,类的层级关系不小心弄错了,不需要删除之后再重新编辑;可以拖动这个类到它应处于的层级,类似于文件夹的操作。如果拖动了某个类,它的子类也会随之移动,但不会改变这个类及其子类的层级关系。如果类的名字写错了,可以右键选择“Change IRI Name”进行更改。
如果需要增加很多个子类,可以右键点击该类,选择“Add Subclasses”。

在空白大框内输入要建立的子类的名字,以回车为分隔,就可以一键完成子类的建立。点击“Continue”,可以看到以这种方法建立的子类默认是均不相交的集合。

点击“Finish”即可完成创建。
如果想要同时创建多级的子类,可以通过“Tab”来进行区分:

大家可以注意到批量建模过程中下面的Prefix和Suffix两个地方,这就是Protégé建模的方便之处。如果我们建的这些类拥有同样的前缀或者后缀,就可以更加方便:

在本体中,类和子类的关系可以这么理解:就拿上面的例子来说,DeepPanBase中所有的实例,都是PizzaBase的实例,这个关系是随着子类(SubClass-of)这个关系的定义而自然存在的;也就是说在实例化的时候,我们只需要说明这个实例是DeepPanBase即可。
对象属性(Object Property)
对象属性的建立
在本体中定义了两种类型的属性——对象属性(Object Property)和数据属性(Data Property)。
Object properties are relationships between two individuals.
Datatype properties describe relationships between individuals and data values.
我们知道,本体或者语义网最基础的元素是(s,p,o)三元组,前面提到的类的定义方式可以看作是s和o的定义方式,这里这个对象属性就是p的定义。
对象属性和数据属性的定义可以这么理解:假如有一对夫妻小红和小绿,那么我们可以先定义两个类——男人、女人;小红是类“女人”的一个实例,小绿是类“男人”的一个实例。之后我们可以定义小红和小绿之间的夫妻关系,这个关系就是对象属性“夫妻”。同时我们又知道小红今年30岁,那么我们可以定义小红的一个数据属性“年龄”,属性值是“30”。

和Class的界面类似,Object property的界面如下图所示。

和Thing一样,topObjectProperty是所有属性的根节点。对属性的操作也是主要由三个button来完成。

和类一样,对象属性的名字是不能重复的。同时在《官方手册》中也建议,在命名时为了方便管理,最好能够一目了然地反应对象属性所描述的关系。
如果是用英文命名,建议是第一个词用小写字母,每个词之间不用空格(因为空格可能会在编程的时候带来麻烦),从第二个词开始首字母大写(便于区分不同的词,能够更快地理解对象属性的含义);此外,《手册》还建议第一个小写单词尽量用is和has,因为这是最常见的对象属性。
如果是用中文命名,我感觉就是避免歧义就好了。
例子:

在定义对象属性的时候,一个比较重要的操作就是定义属性之间的互逆关系。比如“isParentOf”和“isChildOf”就是一对互逆的对象属性。互逆关系的定义是对本体关系的补充,也是推理过程的优化。
在这个例子中,可以先选择“hasTopping”,再点击“Inverse Of”旁边的“+”,创建对象属性“isToppingOf”就完成了一对互逆属性的定义。如果已经创建好了“isToppingOf”这个对象属性,那么可以在点击“+”之后弹出的对话框中选择“isToppingOf”这个对象属性即可。

对象属性特性的定义
在定义对象属性的时候,我们还可以定义对象属性的属性特性,对对象属性作出更多的说明。这些特性可以用家庭成员之间的关系很好地说明。

Functional
Function我们都知道有“函数”的意思,在这里,Functional可以认为是函数中的“单映射”关系。如果一个对象属性的特性是Functional(单值的),那么对于某个实例来说,通过这个对象属性进行关联的实例有且仅有一个。
Functional properties are also known as single valued properties and also features.

Inverse Functional
Inverse Functional特性最重要的还是体现在Functional上,它的涵义是“该对象属性的逆属性是单值属性(single value property)”。也就是说,对于一个给定的个体,最多可以有一个通过该属性与该个体相关的个体。例如将”isBirthMotherOf”这个属性定义为拥有Inverse Functional特性的属性,那么就是说对于“Jean”来说,最多有一个个体能够通过该属性与她相连,因此可以推理得到Margaret和Peggy都是同一个人。

Transitive
Transitive定义了对象属性的传递性。下图是《手册》中的一个例子,假设对象属性“hasAncestor”具有“Transitive”的特性,如果已知“Matthew hasAncestor Peter”和“Peter hasAncestor William”,那么可以由“hasAncestor”的传递性推理得到“Matthew hasAncestor William”这一事实。
Symmetric
Symmetric定义了对象属性的对称性。在家庭成员中,如果Matthew有一个兄弟姊妹(hasSibling)叫Gemma,自然Gemma也有一个兄弟姐妹(hasSibling)叫Matthew。我们可以定义对象属性“hasSibling”是对称的,那么我们只需声明一条事实,另一条事实因为对象属性的“对称性”而自然产生。

Asymmetric
非对称性也比较好理解,比如hasChild这个属性就不能定义为对称的。
Reflexive
Reflexive定义的是对象属性的自反性,也就是自己和自己的关系。比如“know”(认识)这一对象属性,对于每个人来说,自己肯定是认识自己的。
Irreflexive
Irreflexive定义的是对象属性的非自反性,也就是说这个对象属性不能描述实例自身到自身的关系。例如isMotherOf。




对于某一个对象属性来说,可以定义一种或者多种特性,但是注意不要矛盾就行。比如《手册》中就有两个比较重要的提醒:
- 如果你定义了某个对象属性是可传递的,那么它的逆属性也应该是可传递的。
- 如果你定义了某个属性是可传递的,那么这个属性就不能是单值的。
If a property is transitive then its inverse property should also be transitive.
Note that if a property is transitive then it cannot be functional.
对象属性的Domains和Ranges
我们知道语义网可以看作是一张图,一条边联系的两个节点就是一个事实(或者成为一条知识),即(s,p,o)三元组,这条边就是对象属性。同时,这张图应该是一张有向图,那么每一条边都带有箭头指向性——这个箭头的起点称为对象属性的Domain(我通常叫做定义域),重点称为对象属性的Range(我通常叫做值域)。
值域和定义域和可以在Description里面进行选择和定义。

在Pizza的这个例子里面,我们可以定义好这些属性的值域和定义域。如图所示:

在Protégé中,是允许对象属性拥有多个值域的。对于互逆的对象属性来说,对象属性的值域是其逆属性的定义域,对象属性的定义域是其逆属性的值域。
利用对象属性约束类(类的约束)
对象属性实质上就是定义了类之间的关系,在定义了这些对象属性之后,可以利用这些属性来描述类;或者说,给定义好的类添加一些约束。
A restriction describes a class of individuals based on the relationships that members of the class participate in. In other words a restriction is a kind of class, in the same way that a named class is a kind of class.
在Protégé中,约束的定义可以在类的Description栏中找到:

点击“+”,可以在Class expression editor里面手动输入,也可以在Object restriction creator里面选择。一些比较复杂的关系可以选择手动输入;一些比较简单的直接关系选择会比较快一点。

这里要说明一下,在教程里面对类添加约束是在“SuperClasses”里面的,但是在Protégé最新的版本中,这些约束的定义是放在“SubClass Of”里面了。这是因为,这些约束实际上也是定义了一个隐含类,这个隐含类中的成员是满足这些约束关系的成员;而该类的成员均是这个隐含类的成员;也就是说,这个类是由约束形成的隐含类的子类。
在本体中,有三类约束:量词描述(Quantifier Restrictions),数量描述(Cardinality Restrictions),包含描述(hasValue Restrictions)。
量词约束(Quantifier Restrictions)
量词约束又可以被分为存在性量词约束(Existential Restrictions)和全称量词约束(Universal Restrictions)。
存在性量词约束
存在性量词约束用关键字“some”来描述。在数学逻辑表达式中,存在性量词约束可以用符号“∃”表示。例如“hasTopping some MozzarellaTopping”表示“这个类存在Topping为MozzarellaTopping的成员”。其关系如下图所示:
以MargheritaPizza为例,MargheritaPizza(玛格丽特比萨)是以自发粉、小西红柿为主要材料的一款菜品,调料是初榨橄榄油、荷兰撒拉米等。我们可以来梳理一下MargheritaPizza与其它类之间的关系。
MargheritaPizza的Topping可以是TomatoTopping或者MozzarellaTooping。
MargheritaPizza有很多种饼底。
这样,可以对MargheritaPizza添加下图所示的一些约束:
在类的创建界面,可以看到有一个小按钮可以选择“Asserted”或者“inferred”。Asserted是人手工创建的结构,inferred”是推理机推理得到的结构。
在使用推理机的时候,如果有矛盾的类将会以红色来表示,这样可以方便我们检查我们定义的类及其约束关系是否正确。Protégé提供了很多推理机的插件,选择相应的推理机,点击“Start Reasoner”就可以开始推理。
到这里,我们发现,我们目前定义的,都是类的必要条件;也就是说对于某一个实例来说,它属于这个类,那么它一定具有这些条件,但是反过来如果它具有这些条件,我们不能说它一定属于这个类。
因此,我们需要把一些必要条件进一步写成充分必要条件。例如对于芝士比萨(CheeseyPizza)来说,如果一个比萨是芝士比萨,那么它的饼面一定有芝士。按照上面讲过的步骤,我们可以添加下面这样的约束:
反过来,如果一个比萨饼面上有芝士,那么它就是芝士披萨。于是我们就要把“hasTopping some CheeseToppig”这个必要条件改为充分必要条件。这时,我们在“hasTopping some CheeseToppig”前加上一个“and”即可,但是要注意的是应该在“Equivalent to”底下添加。
同样的,我们使用推理机,可以发现在“inferred”界面,CheeseyPizza的子类自动扩充了。
对比一下手工建立的结构和自动推理得到的结构:
全称量词约束
前面讲的这些描述都是是存在性量词约束(some),下面我们主要看一下全称量词约束。全称量词约束用关键字“only”来描述。在数学逻辑表达式中,全称量词约束可以用符号“∀”表示。例如“hasTopping only MozzarellaTopping”表示“这个类任一成员的Topping是MozzarellaTopping”。
假设我们定义一个Pizza的子类VegetarianPizza(素食Pizza),可以添加如下描述:
当我们同样调用推理机的时候,却发现VegetarianPizza中并没有生成子类,按照其他Pizza的描述,VegetarianPizza中应当包含MargheritaPizza和SohoPizza。
这是因为,在本体中使用的是开放世界假设(Open World Assumption, OWA)。
- Close world Assumption(CWA),封闭世界假设,将当前未知的事物都设为假的假设。在BIM模型中的含义是:当某个元素在BIM模型中没有进行详细描述时,BIM模型默认其不存在。现在大多BIM软件采用CWA假设。
- 开放世界假设(Open World Assumption, OWA), 它和CWA相反, 对推不出来的命题就很诚实地当作不知道这个命题的正确与否, 这样的后果就是知识库中能推导出来的结论大大减少。语义网应该基于OWA假设。
因此,我们要对这些类添加闭包描述。
对MargheritaPizza:
对SohoPizza:
这时候我们再调用推理机,就可以发现VegetarianPizza的子类自动扩充了:
我们知道,Pizza的种类有很多,除了我们定义的CheeseyPizza,VegetarianPizza和NamedPizza之外,还会有各种种类的Pizza,我们当然没有办法把它们全部定义完。因此,我们需要定义一个类——ValuePartitions,里面包含的是可以被枚举的类,例如Pizza的辣度SpicinessValuePartition,包括Mild,Medium和Hot三种程度。
然后我们知道,在点菜的时候Pizza的辣度只能是这三种,而且这三种辣度集是互不相交的——也就是说Pizza要么是不辣的(Mild),要么是中辣的(Medium),要么是重辣的(Hot)。这里我们就要引入“Covering Axioms”。我们给SpicinessValuePartition这个类添加一个“Covering Axioms”,如下图所示:
这时候,这个描述就表示:SpicinessValuePartition=Mild∪Medium∪Hot
可以用下面这张图来看出加上“Covering Axioms”前后这个类的不同含义:同样的,我们可以用前面讲到的量词描述来给不同的Pizza Topping添加Pizza辣度的描述。
对JalapenoPepperTopping:
对RedPepperTopping:
这时候,我们就可以找出这些Pizza里面的SpicyPizza:
这里这个条件的意思是:这个实例是一个Pizza,并且它有某一种PizzaTopping,并且这个PizzaTopping的口味是Hot。调用推理机,可以得到SpicyPizza的子类有AmericanHotPizza:





















数量约束(Cardinality Restrictions)
数量约束主要包含min,max和exactly三个关键字,比较好理解。比如我们创建一个类InterestingPizza(至尊Pizza):

也就是说,这里这个InterestingPizza至少要有3种不同的饼面(hasTopping min 3)。通过调用推理机,我们可以得到InterestingPizza主要包含的子类有:

我们可以定义更加复杂的关系——比如FourCheesePizza:

这里表示,FourCheesePizza一定有4种饼面,并且这些饼面都是Cheese Topping。调用推理机,我们发现,虽然FourCheesePizza没有子类,但是FourCheesePizza成为了InterestingPizza和CheeseyPizza的子类。因为InterestingPizza是至少有3种不同口味的饼面的Pizza,而FourCheesePizza有4种不同的Cheese口味,自然是InterestingPizza的子类;CheeseyPizza是饼面的Cheese Topping的Pizza,因此FourCheesePizza也是CheeseyPizza的子类。

包含约束(hasValue Restrictions)
包含约束用关键字“value”来描述。在数学逻辑表达式中,存在性量词约束可以用符号“∋”表示。例如“hasCountryOfOrigin value Italy”(这里的Italy是一个实例)表示“这个类与这个实例Italy之间的关系是hasCountryOfOrigin”。
比如我们先建立一个实例“Italy”,它的类型是一个国家;建立一个对象属性hasCountryOfOrigin:

之后。我们对MozzarellaTopping添加一条约束:

我们再建立一个类,想要找出意大利风味的PizzaTopping:

调用推理机,可以得到如下的结果:

到这里,基本上把类的约束讲完了,也可以参考一下官方给出的文档:Class Expression Syntax
从逻辑的角度出发组织这些约束
在Class的描述窗口里面,这些约束通常会被组织在equivalent to或者subclass of下面,那么,我们怎么去思考这些约束的组织呢?

从逻辑的角度出发会是更好地选择。如果这个约束是充要条件,那么可以组织在equivalent to里面;如果这个约束是必要条件,那么可以组织在subclass of下面。
例如我们在定义MargheritaPizza的约束时(3.1节,如下图所示),拥有一个Pizza底(hasBase some PizzaBase)是MargheritaPizza的必要条件,所以组织在subclass of 下面。必要条件可以理解为,“如果某个实例是这个类的成员,那么它就必须满足这些条件”。
而我们在定义FourCheesePizza的约束(3.2节,如下图所示)时,因为拥有4个芝士Topping是FourCheesePizza充要条件,所以组织在Equivalent to下面。充要条件可以理解为,“如果某个实例满足这些条件,那么它一定是这个类的成员”。
只有必要条件的类称为基本类(Primitive Class),含有充要条件的类称为定义类(Defined Class)。在Protégé中,定义类比基本类多三道白杠:

基本类和定义类之间的转换可以由类的操作完成,右键某一个Class,选择convert to premitive class或者convert to defined class即可:

下面两张图片可以看出基本类和定义类所对应的约束条件之间的区别:

也就是说,如果我们认为这些所有的必要条件的交集可以准确地定义/描述这个类,我们可以将这些必要条件通过and组合成充要条件。
枚举类(Enumerated Classes)
这里,我们发现,国家Country实际上是一个枚举类,那么枚举类在Protégé中应该怎么表述呢?
我们首先定义好这些国家的实例:

接着,在Country这个类添加一条描述:

调用推理机,可以得到推理结果:

对于实例很多的类,使用这种方法来定义类和实例之间的关系,无疑是一种好方法。
数据属性(Data Property)
Object properties are relationships between two individuals.
Datatype properties describe relationships between individuals and data values.
如果说对象属性描述的是类之间的关系,那么数据属性描述的就是类本身的属性,感觉上更符合“属性”这个词的中文含义。数据属性的定义主要在Data property这个Tab下面,和对象属性定义的界面类似,这里不再赘述。
还是举这个Pizza的例子,我们知道不同的食物都是有不同的卡路里的,我们可以定义一个数据属性——hasCalorificContentValue,用来表示不同Pizza的热量。
这里需要注意的是,数据属性必须是从一个实例指向某一个数值。我们可以定义数据属性的定义域(不同的类),以及值域(属性值的数据类型),但是不能对“类”添加数据属性,只能对“实例”添加数据属性。
实例的添加及数据属性的定义
实例的添加需要在Individuals这个Tab里面实现:

输入实例名,需要注意的是实例名不能重复:

添加实例的类型,假设是一个MargheritaPizza:

接下来添加实例的数据属性:


最后可以看到实例Pizza-1的相关描述如下:

同理,我们可以建立一个AmericanPizza的实例,其卡路里是723:

利用数据属性描述类
我们知道,食物都有卡路里值,这里我们需要加入一个描述:每一种Pizza都有hasCalorificContentValue这个数据属性。我们可以对Pizza这个类增加一些Data restriction。


在这个基础上,我们可以定义一个高卡路里Pizza类——HighCarloriePizza,指卡路里值高于400的类,并对其增加一些描述:

调用推理机,可以得到HighCarloriePizza中加入了Pizza-2这个实例(因为Pizza-2的卡路里值为723):

同样的,可以定义一个低卡路里Pizza类:

调用推理机可以发现,因为Pizza-1的卡路里值只有263,所以它属于LowCarloriePizza:

注释属性(Annotation property)
顾名思义,注释属性就是对实体的一些注释,可以标识标签、创建时间、创作者等对不需要参与推理的信息。常用的一些注释属性都已经内置在Protégé的Annotation properties这个tab下面:

owl:versionInfo——注释本体的当前版本信息owl:priorVersion——注释本体的先前版本信息owl:backwardsCompatibleWith——注释当前版本的本体相兼容的之前的版本信息owl:incompatibleWith——注释当前版本的本体不兼容的之前的版本信息rdfs:label——可以用于表示实体的标签。例如,我们设置类Pizza的rdfs:label属性为“比萨”,那么在Protégé里面,显示的就是这个label的信息。
rdfs:comment——一些注释或者评论rdfs:seeAlso——通常为一些链接,表示该实体和其他资源(可以是一些参考文献或者参考资料等)之间的关系。rdfs:isDefinedBy——表示该定义该实体的人员/组织
阶段小结
第二章基本算是手册的主体,第二章的内容理解之后开始建立本体应该不是问题了。这里面对于推理机的应用主要还是用于本体的检验和分类,一定程度上是减少了手工建立本体的过程。
另外,在开始建立本体时,本体的框架、类之间关系的梳理极其重要,也是能够顺利进行推理的先决条件。
另外,Protégé中对于类的描述其实就是对于数学集合符号和逻辑符号的不同运用,了解这些符号及描述的对应关系之后能更好地理解Protégé中的相关描述。
推理
开放世界假设下的推理
前面提到,语义网是基于开放世界假设进行推理的。在开放世界假设下,未知的知识是不确定的,这将大大减少推理得到的结论。
比如,这里定义了一个类——NonVegetarianPizza,它的描述如下:

我们再定义一种Pizza——UnclosedPizza,它的描述如下:

而当我们调用推理机时,发现UnclosedPizza既不属于NonVegetarianPizza,也不属于VegetarianPizza,因为我们对UnclosedPizza的描述只是说UnclosedPizza有一种饼面是MozzarellaTopping,并没有说它只有CheeseTopping:

而如果我们将UnclosedPizza的描述修改一下:

我们可以发现,UnclosedPizza被归为了VegetarianPizza的子类:

因此,在语义网的推理中,我们需要注意推理条件的设置。
推理后的类的展示
推理后的类之间的继承关系应该是在OWLViz里面,切换Inferred hierarchy之后可以看到:

推理后的本体保存
在文件菜单下面将推理后的结果另保存为本体即可,注意需要打开推理机开始推理之后才可以~

将Excel表格中的数据导入Protégé
Protégé是支持从Excel表格中导入实例的,好像这个需求很多人都会用到,我自己没有怎么用过。具体教程可以看这个:protegeproject/cellfie-plugin。因为是Github地址,所以可能会不太稳定,我这里就简单地搬运一下好了。
导入Excel表格实例的插件在tools这个tab下面,如果你没有这个选项,可以检查一下是否更新了插件。

导入进来之后,可以看到如下的窗口。区域1展示的是导入的excel的内容,可以包含多个sheet。区域2是导入规则,导入规则是需要自己去制定的。制定完规则后,点击区域3的“Generate Axioms”就行。如果没有制定导入规则,“Generate Axioms”这个按钮就无法点击。

关于规则的语法可以看这里:MappingMasterDSL(这是项目的Github网址,里面有很多案例,建议看这个)、OWL 2 Web Ontology Language Manchester Syntax (Second Edition)(这个是W3C的网址,一般可以正常打开)。
比如说,我要创建Excel表里面的实例,可以用下面这个语句:Individual: @A*。A*表示把A这一列的都加进来,start row和end row可以指定加入的范围。对于具体的实例,也可以增加一些描述。具体的还是去看项目官网的一些案例吧~

得到的结果如下:


