简介
对图数据库所涉及到的一些概念记录一下,综合转载于:
- 数据库与数据仓库的本质区别是什么?
- 详解数据仓库和数据库的区别
- 结构化数据、半结构化数据和非结构化数据
- 关系型数据库和非关系型数据库
- 简述关系型数据库和非关系型数据库
- 关系型数据库与非关系型数据库
- 浅谈图数据库
- 一文聊“图”,从图数据库到知识图谱
- TinkerPop与JanusGraph概述
- 图数据库 —- > Tinkerpop (一)
- 属性图和RDF图简要介绍与比较
- 知识图谱里的知识表示:RDF
- 一文了解各大图数据库查询语言(Gremlin vs Cypher vs nGQL)| 操作入门篇
- Neo4j Cypher查询语言详解
- Neo4j - Cypher vs Gremlin query language
- Gremlin Docs
- Gremlin中文文档
- 深入学习图数据库语言Gremlin 系列文章链接汇总
数据库 vs 数据仓库
特点
数据库 Database(Oracle,Mysql和PostgreSQL)主要用于事务处理,数据仓库 Datawarehouse(Amazon Redshift,Hive)主要用于数据分析。
用途上的不同决定了这两种架构的特点不同。
数据库(Database)的特点是:
- 相对复杂的表格结构,存储结构相对紧致,少冗余数据。
- 读和写都有优化。
- 相对简单的read/write query,单次作用于相对的少量数据。
数据仓库(Datawarehouse)的特点是:
- 相对简单的(Denormalized)表格结构,存储结构相对松散,多冗余数据。
- 一般只是读优化。
- 相对复杂的read query,单次作用于相对大量的数据(历史数据)。
数据库与数据仓库的区别实际讲的是OLTP与OLAP的区别。
- 操作型处理,叫联机事务处理OLTP(On-Line Transaction Processing),也可以称面向交易的处理系统,它是针对具体业务在数据库联机的日常操作,通常对少数记录进行查询、修改。用户较为关心操作的响应时间、数据的安全性、完整性和并发的支持用户数等问题。传统的数据库系统作为数据管理的主要手段,主要用于操作型处理。
- 分析型处理,叫联机分析处理OLAP(On-Line Analytical Processing)一般针对某些主题历史数据进行分析,支持管理决策。
| 操作型处理 | 分析型处理 |
|---|---|
| 细节的 | 综合或者提炼的 |
| 实体-关系(E-R)模型 | 星型模型或雪花模型 |
| 存储瞬间数据 | 存储历史数据,不包含最近的数据 |
| 可更新的 | 只读、只追加 |
| 一次操作一个单元 | 一次操作一个集合 |
| 性能要求高,响应时间短 | 性能要求宽松 |
| 面向事务 | 面向分析 |
| 一次操作数据量小 | 支持决策需求 |
| 数据量小 | 数据量大 |
| 客户订单、库存水平和银行账户查询 | 客户收益分析、市场细分 |
电商例子
举个最常见的例子,拿电商行业来说好了。
基本每家电商公司都会经历,从只需要业务数据库到要数据仓库的阶段。
电商早期启动非常容易,入行门槛低。找个外包团队,做了一个可以下单的网页前端 + 几台服务器 + 一个MySQL,就能开门迎客了。这好比手工作坊时期。
第二阶段,流量来了,客户和订单都多起来了,普通查询已经有压力了,这个时候就需要升级架构变成多台服务器和多个业务数据库(量大+分库分表),这个阶段的业务数字和指标还可以勉强从业务数据库里查询。初步进入工业化。
第三个阶段,一般需要 3-5 年左右的时间,随着业务指数级的增长,数据量的会陡增,公司角色也开始多了起来,开始有了 CEO、CMO、CIO,大家需要面临的问题越来越复杂,越来越深入。高管们关心的问题,从最初非常粗放的:“昨天的收入是多少”、“上个月的 PV、UV 是多少”,逐渐演化到非常精细化和具体的用户的集群分析,特定用户在某种使用场景中,例如“20~30岁女性用户在过去五年的第一季度化妆品类商品的购买行为与公司进行的促销活动方案之间的关系”。
这类非常具体,且能够对公司决策起到关键性作用的问题,基本很难从业务数据库从调取出来。原因在于:
- 业务数据库中的数据结构是为了完成交易而设计的,不是为了而查询和分析的便利设计的。
- 业务数据库大多是读写优化的,即又要读(查看商品信息),也要写(产生订单,完成支付)。因此对于大量数据的读(查询指标,一般是复杂的只读类型查询)是支持不足的。
而怎么解决这个问题,此时我们就需要建立一个数据仓库了,公司也算开始进入信息化阶段了。数据仓库的作用在于:
- 数据结构为了分析和查询的便利;
- 只读优化的数据库,即不需要它写入速度多么快,只要做大量数据的复杂查询的速度足够快就行了。
那么在这里前一种业务数据库(读写都优化)的是业务性数据库,后一种是分析性数据库,即数据仓库。这样把数据从业务性的数据库中提取、加工、导入分析性的数据库就是传统的ETL(Extract-Transform-Load)工作,即数据仓库技术。
图书系统例子
用图书表格系统举例子。如果是数据库储存的话,表单的设计如下:

这里有六张表,分别记录了作者,图书,图书种类,发行商以及他们之间的关系。
如果我们把以上数据用数据仓库来存储,表单设计需要对原始表单进行Denormalization。
Denormalization is a strategy used on a previously-normalized database to increase performance. In computing, denormalization is the process of trying to improve the read performance of a database, at the expense of losing some write performance, by adding redundant copies of data or by grouping data. - Denormalization - Wikipedia
现在我们把这个数据库的五张表以Books.Title作为主键,用如下图的脚本Denormalize之后存到数据库仓库中。
1 | -- Denormalization Script -- |
那么数据仓库中就只剩下一张表,如下图所示。

存储空间对比
很明显,因为在denormalization的过程中,如果数据库主表和次表不是一对一的关系,那么最终数据仓库主表或者次表一定会出现重复的数据。所以从存储空间角度讲,相比于数据库紧密的存储结构,数据仓库则存在大量冗余重复的数据。


读写优化对比
基本读(Read)操作对比
下图所示的两种查询,一个是找一本书(PrimaryKey)的信息,另一个是找一位作者(Non-Key)所有的作品信息。由于数据库需要利用表之间的关联才能找到所有需要的数据,在效率上会相对低下。相比之下数据仓库把这些关联关系转化成重复数据记录到同一张表上了,查询效率相对就会较高。数据仓库相当于牺牲了空间换取了查询效率。

在数据库里面写这段query的时候,需要了解表单的结构与他们之间的关系——这对于做数据报告或者数据分析非常不友好,尤其是在表单结构很复杂的时候(比如表单使用了逻辑树的储存结构)。这时候数据仓库简单明了的Denormalized表单结构就对于生成数据报告就非常有优势了。
除此之外,由于数据报告和数据分析常常涉及到大规模的查询,这些查询很可能会占用很高的CPU资源,从而可能影响到数据库的常规读写操作——因为数据库常常是Single-Instance的;这一点上数据仓库的Multi-instances的结构就不会有太多这个问题。
大数据读(Read)操作对比
当数据量非常大的时候,特定条件下的数据仓库的读优化所带来的优势就开始碾压数据库了。大部分的数据库都是Single-instance的,而数据仓库则是Multi-instances的distributed system。数据仓库在分配储存的节点的时候是根据PrimaryKey/PartitionKey来分配的,查询的时候不仅根据查询键的值来搜索对应节点位置,同时进行大量的并行查询。这使得在对大数据进行查询的时候有极大的优势。

但是,并不是所有的读操作,数据仓库一直都有优势。比如在如下两种情况时,数据仓库的读表现并不如数据库:
- 在对小量数据进行读取操作的时候,由于数据仓库要进行找Node的location之类的预运算,整体效率上反倒不如数据库;
- 如果读取操作的目标不是主键(PrimaryKey)或者分配键(PartitionKey),那么数据仓库的查询也需要进行全局扫描,效率上就不好说是否胜过数据库了。
这两点也是为什么现在即使有像Amazon Redshift这般强大的Datawarehouse应用,SQL Database仍然无法被取代的一部分主要原因。
写(Write)操作对比
大多数情况下,数据仓库不太会进行精确的写操作。因为冗余行数太多,有时候只是改一个很小的字段,也会修改大量的行数。而对于数据库来说,由于其紧凑的表格结构,写操作就可以非常精细有效了。比如,需要修改《Java Complete》这本书的版权,从1999改到2002,数据库里面只需要该一行,而数据仓库里面需要改5行。

数据仓库的写操作都是整段(表)刷新或者整段数据插入, 这也和它的用途——做数据分析有关系。由于数据仓库的整表刷新和分布式储存的特质,我们可以通过把PartitionKey设置成数据创建/更新的时间,然后记录一段时间内的历史数据。这对于数据分析以及利用数据进行决策都有重要意义。
结构化数据、半结构化数据和非结构化数据
结构化数据
结构化的数据是指可以使用关系型数据库表示和存储,表现为二维形式的数据。一般特点是:数据以行为单位,一行数据表示一个实体的信息,每一行数据的属性是相同的。举一个例子:
1 | id name age gender |
所以,结构化的数据的存储和排列是很有规律的,这对查询和修改等操作很有帮助。但是,它的扩展性不好。比如,需要增加一个字段。
半结构化数据
半结构化数据是结构化数据的一种形式,它并不符合关系型数据库或其他数据表的形式关联起来的数据模型结构,但包含相关标记,用来分隔语义元素以及对记录和字段进行分层。因此,它也被称为自描述的结构。
半结构化数据,属于同一类实体可以有不同的属性,即使他们被组合在一起,这些属性的顺序并不重要。
常见的半结构数据有XML和JSON,对于两个XML文件,第一个可能有
1 | <person> |
1 | <person> |
从上面的例子中,属性的顺序是不重要的,不同的半结构化数据的属性的个数是不一定一样的。有些人说半结构化数据是以树或者图的数据结构存储的数据,怎么理解呢?上面的例子中,
非结构化数据
顾名思义,就是没有固定结构的数据。各种文档、图片、视频/音频等都属于非结构化数据。对于这类数据,我们一般直接整体进行存储,而且一般存储为二进制的数据格式。
关系型数据库 vs 非关系型数据库
关系型数据库
关系型数据库,是指采用了关系模型来组织数据的数据库。
关系模型是在1970年由IBM的研究员E.F.Codd博士首先提出的,在之后的几十年中,关系模型的概念得到了充分的发展并逐渐成为主流数据库结构的主流模型。
简单来说,关系模型指的就是二维表格模型,而一个关系型数据库就是由二维表及其之间的联系所组成的一个数据组织。
关系模型中常用的概念:
- 关系:可以理解为一张二维表,每个关系都具有一个关系名,就是通常说的表名
- 元组:可以理解为二维表中的一行,在数据库中经常被称为记录
- 属性:可以理解为二维表中的一列,在数据库中经常被称为字段
- 域:属性的取值范围,也就是数据库中某一列的取值限制
- 关键字:一组可以唯一标识元组的属性,数据库中常称为主键,由一个或多个列组成
- 关系模式:指对关系的描述。其格式为:关系名(属性1,属性2,……,属性N),在数据库中成为表结构
优点
- 容易理解:二维表结构是非常贴近逻辑世界的一个概念,关系模型相对网状、层次等其他模型来说更容易理解
- 使用方便:通用的SQL语言使得操作关系型数据库非常方便
- 易于维护:丰富的完整性(实体完整性、参照完整性和用户定义的完整性)大大减低了数据冗余和数据不一致的概率
瓶颈
高并发读写需求
网站的用户并发性非常高,往往达到每秒上万次读写请求,对于传统关系型数据库来说,硬盘I/O是一个很大的瓶颈。
海量数据的高效率读写
网站每天产生的数据量是巨大的,对于关系型数据库来说,在一张包含海量数据的表中查询,效率是非常低的。
高扩展性和可用性
在基于web的结构当中,数据库是最难进行横向扩展的,当一个应用系统的用户量和访问量与日俱增的时候,数据库却没有办法像web server和app server那样简单的通过添加更多的硬件和服务节点来扩展性能和负载能力。对于很多需要提供24小时不间断服务的网站来说,对数据库系统进行升级和扩展 是非常痛苦的事情,往往需要停机维护和数据迁移。
性能欠佳
在关系型数据库中,导致性能欠佳的最主要原因是多表的关联查询,以及复杂的数据分析类型的复杂SQL报表查询。为了保证数据库的ACID特性,我们 必须尽量按照其要求的范式进行设计,关系型数据库中的表都是存储一个格式化的数据结构。每个元组字段的组成都是一样,即使不是每个元组都需要所有的字段, 但数据库会为每个元组分配所有的字段,这样的结构可以便于标语表之间进行链接等操作,但从另一个角度来说它也是关系型数据库性能瓶颈的一个因素。
注:数据库事务必须具备ACID特性,ACID是Atomic原子性,Consistency一致性,Isolation隔离性,Durability持久性。
- Atomicity(原子性):一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被恢复(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
- Consistency(一致性):在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设规则,这包含资料的精确度、串联性以及后续数据库可以自发性地完成预定的工作。
- Isolation(隔离性):数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括读未提交(Read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(Serializable)。
- Durability(持久性):事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
多余特性
对网站来说:
事务一致性
关系型数据库在对事物一致性的维护中有很大的开销,而现在很多web2.0系统对事物的读写一致性都不高。
读写实时性
对关系数据库来说,插入一条数据之后立刻查询,是肯定可以读出这条数据的,但是对于很多web应用来说,并不要求这么高的实时性,比如发一条消息之后,过几秒乃至十几秒之后才看到这条动态是完全可以接受的。
复杂SQL,特别是多表关联查询
任何大数据量的web系统,都非常忌讳多个大表的关联查询,以及复杂的数据分析类型的复杂SQL报表查询,特别是SNS类型的网站。现实往往更多的只是单表的主键查询,以及单表的简单条件分页查询,SQL的功能被极大地弱化了。
主流关系型数据库
Oracle,Microsoft SQL Server,MySQL,PostgreSQL,DB2,Microsoft Access, SQLite,Teradata,MariaDB(MySQL的一个分支),SAP
非关系型数据库NoSQL
NoSQL一词首先是Carlo Strozzi在1998年提出来的,指的是他开发的一个没有SQL功能,轻量级的,开源的关系型数据库。这个定义跟我们现在对NoSQL的定义有很大的 区别,它确确实实字如其名,指的就是“没有SQL”的数据库。但是NoSQL的发展慢慢偏离了初衷,我们要的不是“no sql”,而是“no relational”,也就是我们现在常说的非关系型数据库了。
2009年初,Johan Oskarsson举办了一场关于开源分布式数据库的讨论,Eric Evans在这次讨论中再次提出了NoSQL一词,用于指代那些非关系型的,分布式的,且一般不保证遵循ACID原则的数据存储系统。Eric Evans使用NoSQL这个词,并不是因为字面上的“没有SQL”的意思,他只是觉得很多经典的关系型数据库名字都叫“**SQL”,所以为了表示跟这些关系型数据库在定位上的截然不同,就是用了“NoSQL”一词。
非关系型数据库提出另一种理念,例如,以键值对存储,且结构不固定,每一个元组可以有不一样的字段,每个元组可以根据需要增加一些自己的键值对,这样就不会局限于固定的结构,可以减少一些时间和空间的开销。使用这种方式,用户可以根据需要去添加自己需要的字段,这样,为了获取用户的不同信息,不需要 像关系型数据库中,要对多表进行关联查询。仅需要根据id取出相应的value就可以完成查询。但非关系型数据库由于很少的约束,他也不能够提供像SQL 所提供的where这种对于字段属性值情况的查询。并且难以体现设计的完整性。他只适合存储一些较为简单的数据,对于需要进行较复杂查询的数据,SQL数 据库显的更为合适。
优点
- 性能NoSQL是基于键值对的,可以想象成表中的主键和值的对应关系,而且不需要经过SQL层的解析,所以性能非常高。
- 可扩展性:同样也是因为基于键值对,数据之间没有耦合性,所以非常容易水平扩展。
- 成本:NoSQL数据库简单易部署,基本都是开源软件,不需要像使用oracle那样花费大量成本购买使用,相比关系型数据库价格便宜。
- 查询速度:NoSQL数据库将数据存储于缓存之中,关系型数据库将数据存储在硬盘中,自然查询速度远不及nosql数据库。
- 存储数据的格式:NoSQL的存储格式是key-value形式、文档形式、图片形式等等,所以可以存储基础类型以及对象或者是集合等各种格式,而数据库则只支持基础类型。
缺点
- 维护的工具和资料有限,因为nosql是属于新的技术,不能和关系型数据库十几年的技术同日而语。
- 不提供对sql的支持,如果不支持sql这样的工业标准,将产生一定用户的学习和使用成本。
- 只适合存储一些较为简单的数据,对于需要进行较复杂查询的数据,关系型数据库显的更为合适。
- 不适合持久存储海量数据。
CAP理论
NoSQL的基本需求就是支持分布式存储,严格一致性与可用性需要互相取舍。
CAP理论:一个分布式系统不可能同时满足C(一致性)、A(可用性)、P(分区容错性)三个基本需求,并且最多只能满足其中的两项。对于一个分布式系统来说,分区容错是基本需求,否则不能称之为分布式系统,因此需要在C和A之间寻求平衡。
- C(Consistency)一致性
一致性是指更新操作成功并返回客户端完成后,所有节点在同一时间的数据完全一致。与ACID的C完全不同。 - A(Availability)可用性
可用性是指服务一直可用,而且是正常响应时间。 - P(Partition tolerance)分区容错性
分区容错性是指分布式系统在遇到某节点或网络分区故障的时候,仍然能够对外提供满足一致性和可用性的服务。
关系型数据库 vs 非关系型数据库
关系型数据库的最大特点就是事务的一致性:传统的关系型数据库读写操作都是事务的,具有ACID的特点,这个特性使得关系型数据库可以用于几乎所有对一致性有要求的系统中,如典型的银行系统。
但是,在网页应用中,尤其是SNS应用中,一致性却不是显得那么重要,用户A看到的内容和用户B看到同一用户C内容更新不一致是可以容忍的,或者 说,两个人看到同一好友的数据更新的时间差那么几秒是可以容忍的,因此,关系型数据库的最大特点在这里已经无用武之地,起码不是那么重要了。
相反地,关系型数据库为了维护一致性所付出的巨大代价就是其读写性能比较差,而像微博、facebook这类SNS的应用,对并发读写能力要求极 高,关系型数据库已经无法应付(在读方面,传统上为了克服关系型数据库缺陷,提高性能,都是增加一级memcache来静态化网页,而在SNS中,变化太快,memchache已经无能为力了),因此,必须用新的一种数据结构存储来代替关系数据库。
关系数据库的另一个特点就是其具有固定的表结构,因此,其扩展性极差,而在SNS中,系统的升级,功能的增加,往往意味着数据结构巨大变动,这一点关系型数据库也难以应付,需要新的结构化数据存储。
于是,非关系型数据库应运而生,由于不可能用一种数据结构化存储应付所有的新的需求,因此,非关系型数据库严格上不是一种数据库,应该是一种数据结构化存储方法的集合。
必须强调的是,数据的持久存储,尤其是海量数据的持久存储,还是需要一种关系数据库这员老将。
- 成本:Nosql数据库简单易部署,基本都是开源软件,不需要像使用Oracle那样花费大量成本购买使用,相比关系型数据库价格便宜。
- 查询速度:Nosql数据库将数据存储于缓存之中,而且不需要经过SQL层的解析,关系型数据库将数据存储在硬盘中,自然查询速度远不及Nosql数据库。
- 存储数据的格式:Nosql的存储格式是key,value形式、文档形式、图片形式等等,所以可以存储基础类型以及对象或者是集合等各种格式,而数据库则只支持基础类型。
- 扩展性:关系型数据库有类似join这样的多表查询机制的限制导致扩展很艰难。Nosql基于键值对,数据之间没有耦合性,所以非常容易水平扩展。
- 持久存储:Nosql不使用于持久存储,海量数据的持久存储,还是需要关系型数据库。
- 数据一致性:非关系型数据库一般强调的是数据最终一致性,不像关系型数据库一样强调数据的强一致性,从非关系型数据库中读到的有可能还是处于一个中间态的数据。Nosql不提供对事务的处理。
非关系型数据库分类
由于非关系型数据库本身天然的多样性,以及出现的时间较短,因此,不想关系型数据库,有几种数据库能够一统江山,非关系型数据库非常多,并且大部分都是开源的。
这些数据库中,其实实现大部分都比较简单,除了一些共性外,很大一部分都是针对某些特定的应用需求出现的,因此,对于该类应用,具有极高的性能。依据结构化方法以及应用场合的不同,主要分为以下几类:
面向高性能并发读写的key-value数据库
key-value数据库的主要特点即使具有极高的并发读写性能。Key-value数据库是一种以键值对存储数据的一种数据库,类似Java中的map。可以将整个数据库理解为一个大的map,每个键都会对应一个唯一的值。
主流代表为Redis, Amazon DynamoDB, Memcached,Microsoft Azure Cosmos DB和Hazelcast。
虽然它的速度非常快,但基本上只能通过键的完全一致查询获取数据,根据数据的保存方式可以分为临时性、永久性和两者兼具三种。
临时性
所谓临时性就是数据有可能丢失,memcached把所有数据都保存在内存中,这样保存和读取的速度非常快,但是当memcached停止时,数据就不存在了。由于数据保存在内存中,所以无法操作超出内存容量的数据,旧数据会丢失。总结来说:
- 在内存中保存数据
- 可以进行非常快速的保存和读取处理
- 数据有可能丢失
永久性
所谓永久性就是数据不会丢失,这里的键值存储是把数据保存在硬盘上,与临时性比起来,由于必然要发生对硬盘的IO操作,所以性能上还是有差距的,但数据不会丢失是它最大的优势。总结来说:
- 在硬盘上保存数据
- 可以进行非常快速的保存和读取处理(但无法与memcached相比)
- 数据不会丢失
两者兼备
Redis属于这种类型。Redis有些特殊,临时性和永久性兼具。Redis首先把数据保存在内存中,在满足特定条件(默认是 15分钟一次以上,5分钟内10个以上,1分钟内10000个以上的键发生变更)的时候将数据写入到硬盘中,这样既确保了内存中数据的处理速度,又可以通过写入硬盘来保证数据的永久性,这种类型的数据库特别适合处理数组类型的数据。总结来说:
- 同时在内存和硬盘上保存数据
- 可以进行非常快速的保存和读取处理
- 保存在硬盘上的数据不会消失(可以恢复)
- 适合于处理数组类型的数据
面向海量数据访问的面向文档数据库
这类数据库的特点是,可以在海量的数据中快速的查询数据。文档存储通常使用内部表示法,可以直接在应用程序中处理,主要是JSON。JSON文档也可以作为纯文本存储在键值存储或关系数据库系统中。
不定义表结构
即使不定义表结构,也可以像定义了表结构一样使用,还省去了变更表结构的麻烦。
可以使用复杂的查询条件
跟键值存储不同的是,面向文档的数据库可以通过复杂的查询条件来获取数据,虽然不具备事务处理和Join这些关系型数据库所具有的处理能力,但初次以外的其他处理基本上都能实现。
主流代表为MongoDB,Amazon DynamoDB,Couchbase,Microsoft Azure Cosmos DB和CouchDB。
面向搜索数据内容的搜索引擎
搜索引擎是专门用于搜索数据内容的NoSQL数据库管理系统。主要是用于对海量数据进行近实时的处理和分析处理,可用于机器学习和数据挖掘。主流代表为Elasticsearch,Splunk,Solr,MarkLogic和Sphinx。
面向可扩展性的分布式数据库(面向列的数据库)
这类数据库想解决的问题就是传统数据库存在可扩展性上的缺陷,主要特点是具有很强的可拓展性。这类数据库想解决的问题就是传统数据库存在可扩展性上的缺陷,这类数据库可以适应数据量的增加以及数据结构的变化,将数据存储在记录中,能够容纳大量动态列。由于列名和记录键不是固定的,并且由于记录可能有数十亿列,因此可扩展性存储可以看作是二维键值存储。主流代表为Cassandra,HBase,Microsoft Azure Cosmos DB,Datastax Enterprise和Accumulo。
普通通的关系型数据库都是以行为单位来存储数据的,擅长以行为单位的读入处理,比如特定条件数据的获取。因此,关系型数据库也被称为面向行的数据库。相反,面向列的数据库是以列为单位来存储数据的,擅长以列为单位读入数据。
面向列的数据库具有高扩展性,即使数据增加也不会降低相应的处理速度(特别是写入速度),所以它主要应用于需要处理大量数据的情况。另外,把它作为批处理程序的存储器来对大量数据进行更新也是非常有用的。但由于面向列的数据库跟现行数据库存储的思维方式有很大不同,故应用起来十分困难。
面向关系分析的图数据库
不晓得为啥一堆翻译成“图形数据库”的。
图数据库(Graph database)并非指存储图片的数据库,而是以图这种数据结构存储和查询数据。图数据库是一种在线数据库管理系统,具有处理图数据模型的创建,读取,更新和删除(CRUD)操作。与其他数据库不同,关系在图数据库中占首要地位。这意味着应用程序不必使用外键或带外处理(如MapReduce)来推断数据连接。
与关系数据库或其他NoSQL数据库相比,图数据库的数据模型也更加简单,更具表现力。图形数据库是为与事务(OLTP)系统一起使用而构建的,并且在设计时考虑了事务完整性和操作可用性。
图数据库
从社交网络谈起
下面这张图是一个社交网络场景,每个用户可以发微博、分享微博或评论他人的微博。这些都是最基本的增删改查,也是大多数研发人员对数据库做的常见操作。而在研发人员的日常工作中除了要把用户的基本信息录入数据库外,还需找到与该用户相关联的信息,方便去对单个的用户进行下一步的分析,比如说:我们发现张三的账户里有很多关于 AI 和音乐的内容,那么我们可以据此推测出他可能是一名程序员,从而推送他可能感兴趣的内容。

这些数据分析每时每刻都会发生,但有时候,一个简单的数据工作流在实现的时候可能会变得相当复杂,此外数据库性能也会随着数据量的增加而锐减,比如说获取某管理者下属三级汇报关系的员工,这种统计查询在现在的数据分析中是一种常见的操作,而这种操作往往会因为数据库选型导致性能产生巨大差异。
传统数据库的解决思路
传统数据库的概念模型及查询的代码
传统解决上述问题最简单的方法就是建立一个关系模型,我们可以把每个员工的信息录入表中,存在诸如 MySQL 之类的关系数据库,下图是最基本的关系模型:

但是基于上述的关系模型,要实现我们的需求,就不可避免地涉及到很多关系数据库 JOIN 操作,同时实现出来的查询语句也会变得相当长(有时达到上百行):
1 | (SELECT T.directReportees AS directReportees, sum(T.count) AS count |
这种 glue 代码对维护人员和开发者来说就是一场灾难,没有人想写或者去调试这种代码,此外,这类代码往往伴随着严重的性能问题,这个在之后会详细讨论。
传统关系数据库的性能问题
性能问题的本质在于数据分析面临的数据量,假如只查询几十个节点或者更少的内容,这种操作是完全不需要考虑数据库性能优化的,但当节点数据从几百个变成几百万个甚至几千万个后,数据库性能就成为了整个产品设计的过程中最需考虑的因素之一。
随着节点的增多,用户跟用户间的关系,用户和产品间的关系,或者产品和产品间的关系都会呈指数增长。
以下是一些公开的数据,可以反映数据、数据和数据间关系的一些实际情况:
- 推特:用户量为 5 亿,用户之间存在关注、点赞关系
- 亚马逊:用户量 1.2 亿,用户和产品间存在购买关系
- AT&T(美国三大运营商之一): 1 亿个号码,电话号码间可建立通话关系
如下表所示,开源的图数据集往往有着上千万个节点和上亿的边的数据:
| Data set name | nodes | edges |
|---|---|---|
| YahooWeb | 1.4 Billion | 6 Billion |
| Symantec Machine-File Graph | 1 Billion | 37 Billion |
| 104 Million | 3.7 Billion | |
| Phone call network | 30 Million | 260 Million |
在数据量这么大的场景中,使用传统 SQL 会产生很大的性能问题,原因主要有两个:
- 大量 JOIN 操作带来的开销:之前的查询语句使用了大量的 JOIN 操作来找到需要的结果。而大量的 JOIN 操作在数据量很大时会有巨大的性能损失,因为数据本身是被存放在指定的地方,查询本身只需要用到部分数据,但是 JOIN 操作本身会遍历整个数据库,这样就会导致查询效率低到让人无法接受。
- 反向查询带来的开销:查询单个经理的下属不需要多少开销,但是如果我们要去反向查询一个员工的老板,使用表结构,开销就会变得非常大。表结构设计得不合理,会对后续的分析、推荐系统产生性能上的影响。比如,当关系从 老板 -> 员工 变成 用户 -> 产品,如果不支持反向查询,推荐系统的实时性就会大打折扣,进而带来经济损失。
下表列出的是一个非官方的性能测试(社交网络测试集,一百万用户,每个大概有 50 个好友),体现了在关系数据库里,随着好友查询深度的增加而产生的性能变化:
| levels | RDBMS execution time(s) |
|---|---|
| 2 | 0.016 |
| 3 | 30.267 |
| 4 | 1543.595 |
传统数据库的常规优化策略
策略一:索引
索引:SQL 引擎通过索引来找到对应的数据。
常见的索引包括 B- 树索引和哈希索引,建立表的索引是比较常规的优化 SQL 性能的操作。B- 树索引简单地来说就是给每个人一个可排序的独立 ID,B- 树本身是一个平衡多叉搜索树,这个树会将每个元素按照索引 ID 进行排序,从而支持范围查找,范围查找的复杂度是 O(logN) ,其中 N 是索引的文件数目。
但是索引并不能解决所有的问题,如果文件更新频繁或者有很多重复的元素,就会导致很大的空间损耗,此外索引的 IO 消耗也值得考虑,索引 IO 尤其是在机械硬盘上的 IO 读写性能上来说非常不理想,常规的 B- 树索引消耗四次 IO 随机读,当 JOIN 操作变得越来越多时,硬盘查找更可能发生上百次。
策略二:缓存
缓存:缓存主要是为了解决有具有空间或者时间局域性数据的频繁读取带来的性能优化问题。一个比较常见的使用缓存的架构是 lookaside cache architecture。下图是之前 Facebook 用 Memcached + MySQL 的实例(现已被 Facebook 自研的图数据库 TAO 替代):
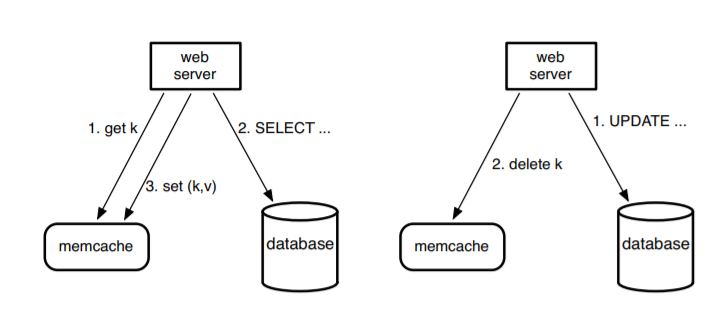
在架构中,设计者假设用户创造的内容比用户读取的内容要少得多,Memcached 可以简单地理解成一个分布式的支持增删改查的哈希表,支持上亿量级的用户请求。基本的使用流程是当客户端需读数据时,先查看一下缓存,然后再去查询 SQL 数据库。而当用户需要写入数据时,客户端先删除缓存中的 key,让数据过期,再去更新数据库。但是这种架构有几个问题:
- 首先,键值缓存对于图结构数据并不是一个好的操作语句,每次查询一条边,需要从缓存里把节点对应的边全部拿出来;此外,当更新一条边,原来的所有依赖边要被删除,继而需要重新加载所有对应边的数据,这些都是并发的性能瓶颈,毕竟实际场景中一个点往往伴随着几千条边,这种操作带来的时间、内存消耗问题不可忽视。
- 其次,数据更新到数据读取有一个过程,在上面架构中这个过程需要主从数据库跨域通信。原始模型使用了一个外部标识来记录过期的键值对,并且异步地把这些读取的请求从只读的从节点传递到主节点,这个需要跨域通信,延迟相比直接从本地读大了很多。(类似从之前需要走几百米的距离而现在需要走从北京到深圳的距离)
使用图结构建模
上述关系型数据库建模失败的主要原因在于数据间缺乏内在的关联性,针对这类问题,更好的建模方式是使用图结构。
假如数据本身就是表格的结构,关系数据库就可以解决问题,但如果你要展示的是数据与数据间的关系,关系数据库反而不能解决问题了,这主要是在查询的过程中不可避免的大量 JOIN 操作导致的,而每次 JOIN 操作却只用到部分数据,既然反复 JOIN 操作本身会导致大量的性能损失,如何建模才能更好的解决问题呢?答案在点和点之间的关系上。
点、关联关系和图数据模型
在我们之前的讨论中,传统数据库虽然运用 JOIN 操作把不同的表链接了起来,从而隐式地表达了数据之间的关系,但是当我们要通过 A 管理 B,B 管理 A 的方式查询结果时,表结构并不能直接告诉我们结果。
如果我们想在做查询前就知道对应的查询结果,我们必须先定义节点和关系。
节点和关系先定义是图数据库和别的数据库的核心区别。打个比方,我们可以把经理、员工表示成不同的节点,并用一条边来代表他们之前存在的管理关系,或者把用户和商品看作节点,用购买关系建模等等。而当我们需要新的节点和关系时,只需进行几次更新就好,而不用去改变表的结构或者去迁移数据。
根据节点和关联关系,之前的数据可以根据下图所示建模:
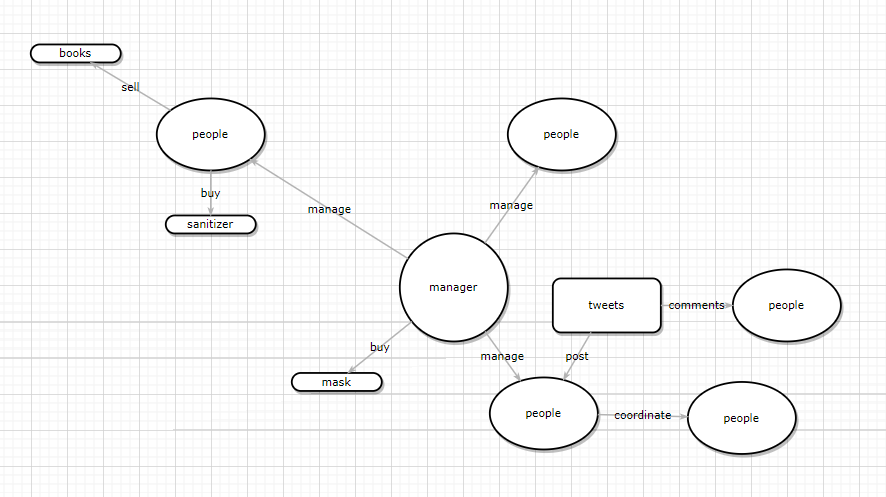
通过图数据库 Nebula Graph 原生 nGQL 图查询语言进行建模,参考如下操作:
1 | -- Insert People |
而之前超长的 query 语句也可以通过 Cypher / nGQL 缩减成短短的 3、4 行代码。
下面为 nGQL 语句
1 | GO FROM 1 OVER manage YIELD manage.level_s as start_level, manage._dst AS personid |
下面为 Cypher 版本
1 | MATCH (boss)-[:MANAGES*0..3]->(sub), |
从近百行代码变成 3、4 行代码可以明显地看出图数据库在数据表达能力上的优势。
底层存储 & 处理引擎
因此,专门用于图的存储和查询技术是非常必要的。图技术根据应用方式的不同可以分为两个方向,第一个方向是图数据库,它用于图数据的存储和联机事务查询,具备实时性,面向OLTP,支持CRUD和事务。第二个方向是图计算引擎,它用于图数据的离线查询分析,更适合海量数据的挖掘,面向OLAP。
图数据库有很多成熟的产品,根据底层存储和处理引擎是否原生,图数据库可以分为四类。为了便于后面理解图数据库处理图的优势,我们解释一下这两个分类维度的含义。
底层存储
- 原生图存储:数据存储模式为存储和管理图而设计,为图进行过优化。
- 非原生图存储:将图数据序列化,采用关系型数据库、面向对象数据库、或是其他通用数据存储。
处理引擎
- 原生图处理:使用免索引邻接,关联节点在物理层面指向彼此,这种方式不同于传统关系型数据库的树形全局索引,为查询图的关联节点带来了巨大的性能优势。
- 非原生图处理:不采用免索引邻接保存关系。
根据这两个维度,图数据库产品可以分为四类:

知识图谱 & 图数据库
图数据库虽然强大且易用,但是它并不是完美的适用于所有场景。图数据库可以存储海量数据,但并不适合直接用来进行海量数据的分析计算,而更适合用来进行某个实体及其关联关系的查询。因此,仅靠图数据库显然无法解决图计算领域的所有问题,在知识图谱的构建和应用方面还有很多需要利用其他图计算技术来解决的问题。
下图是一个典型的图计算技术架构,包括图数据建模、存储系统和图数据计算三个部分。

- 图数据建模 :对于关系型数据库的数据,关系和实体已知,建模成图数据相对简单。但是对于文本这样的非结构化数据,将其建模成为图数据需要应用自然语言处理、机器学习技术,来解决知识抽取、知识融合和知识推理等问题。斯坦福大学Infolab实验室开源的DeepDive提供了知识抽取的框架,是构建知识图谱的利器。
- 存储系统 :图数据有多种存储方式,图数据库当然是最适应图的关系存储的,但在不同的应用场景下,也可以考虑将图数据以RDF三元组、关系型数据库、ES或其他NoSQL方式进行存储。
- 图数据应用 :在构建好的图数据基础之上,通过图计算引擎对海量图数据进行离线的计算分析,针对不同的应用场景,也可以在内存处理或工作存储中对图数据进行查询分析。
图数据库非常适用于图数据的存储和实时查询,是知识图谱的基石,但它并非知识图谱的全部。在应用时,我们需要针对具体的场景去进行选型,结合不同的图计算技术进行分析计算。
图计算框架Tinkerpop
是图计算
就如程序=数据结构+算法一样,图计算=Structure+Process。
- Structure,即图结构,图数据库或图计算框架常用的图形结构通常是基于属性图模型:
- 一个图由Vertex(顶点、节点、实体)和Edge(边,线,关系)组成。顶点通过边连接,边有方向,也就是说一条边有一个起始节点和一个结束节点。
- 其中顶点和边上都可以包含属性(键值对形式,键一般是字符串,值可以是任意类型的数据)。
- 顶点和边都有标签label进行标记,用于分类,顶点可以有多个label,边通常只有一个label。
- Process,即处理过程,图处理过程是分析图结构的手段,图过程的典型形式称为遍历(Traversal)。
什么是TinkerPop
TinkerPop是一个面向实时事务处理(OLAP)以及批量、分析型(OLTP)的开源的图计算框架。TinkerPop是一个可以应用于不同图形数据库的抽象层,避免应用程序与特定数据库高度依赖。
TinkerPop提供通用的API和工具,使开发人员可以基于不同图数据库轻松创建图形应用程序,使图形数据库与图计算解耦,方便切换不同图形数据库,简化其工作。
TinkerPop是一个总称,它包含若干子项目,以及与核心TinkerPop Gremlin引擎集成的模块。在版本TinkerPop2及之前,TinkerPop分为若干子项目,而从TinkerPop3起,都合并到了Gremlin:
- Blueprints → Gremlin Structure API
- Pipes → GraphTraversal
- Frames → Traversal
- Furnace → GraphComputer and VertexProgram
- Rexster → GremlinServer
体系结构

TinkerPop的核心Gremlin是什么?- Gremlin is Gremlin is Gremlin
- 这句话是官方文档中,解释Gremlin最常出现的一句话,老外总是能把技术文档搞的好似哲学问题。
理解Gremlin以及这句话的含义,可以将Gremlin大致类比为JDK,通过下面类比应该很容易理解Gremlin is Gremlin is Gremlin这句话,用户不管是通过哪种程序语言编写的Gremlin程序,不管是编写的OLTP程序还是OLAP程序,都是没有分别的,都可以通过编译为Gremlin字节码,在GTM(Gremlin Traversal Machine,Gremlin遍历机)上执行:
- JDK = Java语言 + JVM + Java API类库
- Gremlin = Gremlin语言 + GTM + TinkerPop结构API/过程API
TinkerPop不是一个完整的图数据系统,其提供了操作图数据的图形结构接口,图操作过程接口,以及编写图形操作程序的Gremlin语言,和执行图形遍历过程的GTM,但是其并不提供图数据持久化存储功能。
属性图 vs RDF
图数据结构在今天能够得到如此广泛关注,灵活性是一个强大的驱动因素:异构数据、集成新数据源和分析都需要灵活性,而图结构则很好地满足了这一点。现如今,最主要的图数据结构模型有以下两种:属性图和RDF图,下面就将分别介绍这两种图结构并进行比较。
属性图(Property Graphs)
虽然属性图的实现中有一些核心的共性,但是没有真正标准的属性图数据模型,因此属性图的每个实现都有些不同。在下面,我们将重点讨论任何属性图数据库都常见的特征。
- 节点(Nodes):是图中的实体,用表示其类型的0到多个文本标签进行标记,相当于实体。
- 边(Edges):是节点之间的定向链接,也称为关系。其中对应的“from node”称为源节点,“to node”称为目标节点。边是定向的且每条边都有一个类型,它们可以在任何方向上导航和查询。相当于实体之间的关系。
- 属性(Properties):是一个键值对,顶点和边都具有属性。
图1显示了一个属性图的部分,其中包含有关演员、导演和他们参与的电影或电视节目的数据。其中节点用椭圆表示。例如,ID为123的节点(从其属性中看出)表示Tom Hanks。节点标签以深蓝色显示。节点123的标签是人物、演员和导演。关系用灰色箭头表示,从一个节点指向另一个节点,每个关系都有一个红色显示的类型。属性显示在带有金色的圆角矩形中,并使用红色箭头连接到它们所属的节点和关系。

资源描述框架图(RDF Graphs)
RDF图使用标准的图数据模型,其技术栈的标准是由万维网联盟(W3C)管理的,这个组织也同时管理HTML、XML和许多其他网络标准。因此每个支持RDF的数据库都应该以同样的方式支持该模型。除此之外,RDF有一个标准的查询语言称为SPARQL。它既是一种功能齐全的查询语言,又是一种HTTP协议,可以通过HTTP将查询请求发送到端点。RDF图数据模型主要是由以下两个部分组成的:
- 节点(Nodes):对应图中的顶点,可以是具有唯一标识符的资源,也可以是字符串、整数等有值的内容。
- 边(Edges):是节点之间的定向链接,也称为谓词或属性。边的入节点称为主语,出节点称为宾语,由一条边连接的两个节点形成一个主语-谓词-宾语的陈述,也称为三元组。边是定向的,它们可以在任何方向上导航和查询。
RDF的英文全称为Resource Description Framework,因为在RDF图中,一切都称为源。边和节点只是给定语句中资源所扮演的角色。基本上在RDF中,扮演边角色的资源和扮演节点角色的资源没有区别,因此一条语句中的边也可以是另一条语句中的节点。RDF数据模型相较于属性图更加丰富,也在语义上保持一致性。图2展示了如何将上面的图1由属性图表示为RDF:

图2中的图看起来比图1中的属性图大,因为图中的所有文字都被描述为节点。而在可视化RDF图数据时,通常不会这样做,以便使图看起来更干净和更简单。所有节点都用带有浅黄色背景的圆角矩形表示。也就是说,从数据结构的角度来看,它们是图的一部分,就像任何其他节点一样,唯一的区别是它们不能作为源节点,只能是目标节点或宾语。RDF图中的文字值可以有数据类型,数据类型取自XML模式(如xsd:string、xsd:integer等),文本值也可以有语言标记来支持数据国际化。例如,对于纽约市的rdfs:label,我们可以有多个值,例如:“New York City”xsd:string @en 或 “NuevaYork”xsd:string @sp。标识符也是RDF图的一个非常重要的概念。每个非文字节点都被分配一个标识符——通常是一个URI(Uniform Resource Identifier,统一资源标识符)或IRI(Internationalized Resource Identifiers,国际化资源标识符)。本地非URI标识符因为不能互操作而很少使用。而全局唯一标识符为图数据模型带来了许多好处,同时基于RDFbased的解决方案可以根据选定的URI构造规则自动生成URI。另外,在添加数据(例如加载序列化的文件)时,用户也可以提供他们想要使用的URI。标识节点的URI使用限定名(通常称为Qname表示法)显示在图中,如图2中的 rdf 就表示着:http://w3.org/1999/02/22-rdf-syntax-ns#,而对应的也可以使用命名空间中的内置资源定义的语义,如rdf:type. 而使用URI最大的好处之一便是可以如果不同的节点具有同样的URI,就会自动地合并,这也就使得RDF图更加简洁清晰。
具体说一下IRI,URI,URL和URN这几个术语的区别:
- URI:统一资源标识符,字符集被限制为US-ASCII(英文字符),通过指定唯一名称来标识资源;
- IRI:国际化资源标识符(Internationalized Resource Identifier),定义与URI相同,只是将字符集扩展到通用字符集(包含了非英文字符),所以它是URI的超集,同样唯一标识了一个资源;
- URN:统一资源名称(Uniform Resource Name),由命名空间标识符(NID)和命名空间特定字符串(NSS)组成;
- URL:统一资源定位符,即我们通常提到的网址,通常指的是不包含URN的URI子集。
以及它们的集合包含关系:
- IRI ⊃ URI
- URI ⊃ URL
- URI ⊃ URN
- URL ∩ URN = ∅
序列化方式
RDF是以一种建模的方式来描述数据语义,不受具体语法表示的限制,序列化的方式有多种。数据序列化就是将对象或者转化成特定的格式,使其可在网络中传输,或者存储在文件中。
序列化RDF数据的方法主要有这几种:RDF/XML,N-Triples,Turtle,RDFa,JSON-LD。其中Turtle 是使用最广泛的RDF序列化方式,其格式紧凑,易于阅读。Turtle使用 @prefix 对RDF的URI前缀进行缩写,rdf:表示URI前缀 http://www.w3.org/1999/02/22-rdf-syntax-ns#,因此**rdf:type**就是http://www.w3.org/1999/02/22-rdf-syntax-ns#type的简写。
二者的比较与转化
1. 在表达的术语和能力上的不同
主要从标签(Labels)、类型(Types)和属性(Properties)三个关键概念上进行比较。
标签(Labels)
- 在RDF图中,标签是在RDFS命名空间即rdfs:label中定义出的标准谓词,用于指向任何资源的显示名称的值。尽管也可以使用另一个谓词来实现此目的,但是rdfs:label被广泛接受为属性的惟一标识符。
- 在属性图中,标签用于标识节点的类型。它被称为标签而不是类型,因为它只是一个字符串或一个文本标记,在文本之外没有任何意义,且在图中不能捕捉到关于它的任何信息。
类型(Types)
- 在RDF图中,节点的类型或属性的类型是资源,即通常在图中存在另一个节点带有与其关联的附加信息,以定义其预期的用途和语义。节点使用rdf:type来链接到它的类型。
- 在属性图中,属性中的边具有标识类型的标签。它被称为“类型”或“关系类型”。常被用于查询关系匹配,当图可视化显示时,它也作为边的显示名称。

上述图3是图2中RDF图的一部分,其中节点或边周围的绿色边框表示描述数据模型的图元素。在RDF中和在属性图中一样,节点可以属于多个集合。如图中的汤姆·汉克斯既是导演也是演员。但如果一个类是另一个类的子类,则不需要在RDF中指定“父类型”。这些信息是在类级别为属于类的所有资源提供的,因为类信息也是RDF图的一部分。如我们不会在Tom Hanks增加一个类型是人,因为导演和演员本身都是人的“子类型”。在RDF图中,我们还可以捕获关于存储在图中的数据模型的任何信息。而这些信息的存储、访问和处理方式与其他数据完全相同。如图3我们给谓语ex:actedIn增加了一个标签,事实上,我们也可以定义当关系ex:actedIn用于在相反方向(从电影到演员)时,关系的显示名称显示为actors。在RDF图中,在一个语句中用作谓词的资源可以在另一个语句中用作主语或宾语。这也体现出RDF图额外的灵活性,它允许我们存储关于谓词及其用法的信息。这一点也是属性图无法比拟的。
属性(Properties)
在RDF图中,边也可称为属性(谓词),和属性指向的对象可以称为属性值,而所有属性值(文字或URI)都存储为节点。如图2中,ex:125到“The Post”有一条边,边为rdfs:label,在这个例子中,rdfs:label就是一个属性,而“The Post”是一个属性值。
在属性图中,属性只能有文字值。它们的存储和处理的方式与图中的节点不同。用数据建模的术语来说,就是属性图中的属性永远只能是属性。属性结构是键-值对的结构。这意味着属性键只能有一个值,如果它有多个值,则需要将单个值转换为一个由逗号分隔的值组成的数组(如图4所示)。而这也为查询带来了弊端,如查询所有人口数超过58000的城市,而图4中数组第一项表示2018年的人口,第二项表示2010年的人口,在属性图中是无法进行很好地区分。这也是属性图和知识图谱的一个很大的区别:如何从属性值中提取出额外的信息。

2. 在边上附加信息的差异
在属性图中,不同的两条边可以有相同的类型,但不同的特征。如图1中的两个不同id的ACTED_IN边,分别表示Tom Hanks和Sarah Paulson参演了电影The Post。在属性图数据模型中,边唯一地标识源点-边-目标节点组合。
在RDF中,相同类型的边都是相同的,边会被重复使用。这意味着,如果需要增加一些关于Tom Hanks和电影The Post的关系Post(例如,他在电影中扮演的角色),你不能简单地在ex:actedIn里增添一个属性,因为这样的话会在所有的参演这一谓词中增添相同的属性。为了支持在两个特定节点之间的边上附加信息的需要,RDF提供了一种方法来创建一个新的节点来唯一标识源点-边-目标节点三元组。我们就可以使用常规方法对新节点创建语句——它可以是任何语句的主语或宾语。如图5所示,我们在其中创建了一个新节点ex:126来表示语句,Tom Hanks在The Post中的表演,而扮演角色之类关于这个演出的信息都存储在ex:126引出的边中。

相较于属性图,RDF增加边的方式更加方便且强大,因为能够支持以下两点:
- 在边中添加与其他边的关系,如图5中增添扮演的角色Ben Bradlee,而这在属性图中,如果不改变原先的图是无法做到的。
- 向任何属性添加更多信息,而不仅仅是关系。这对于属性图也是不可能的。

而在属性图中,想要实现上面两个功能。对于第1点,常用的做法是像图6那样增添一个新的节点130,这需要重新构造图并更改所有查询和逻辑,因为演员和电影之间的路径现在不同。对于2,属性图的解决方案是改变图的结构,把一个属性变成一个边,一个值变成一个节点。而这需要重新构造一个图,并更改其处理的所有查询和逻辑,因为属性图的存储和访问与图遍历完全不同,并且是独立的。这使得属性图的可演化性和灵活性不如RDF图。正如上述分析的结果,与RDF图相比,属性图的灵活性更弱,扩展或者根据要求进行更改也更加困难。
3. 图分析算法与图的划分
图分析算法是属性图的关键应用,是指节点中心性、节点相似性、最短路径、聚类等算法。属性图以提供这些算法而闻名,且有许多应用都依赖于这些算法。话虽如此,属性图数据模型中没有任何特殊之处使这些算法成为可能,它们同样可以很好地应用于RDF图,事实上许多基于RDF的解决方案也提供类似的算法。关系数据库使用表和视图对数据进行划分。属性图和RDF图均允许用户限定特定类型的节点集。例如,一个查询可以被限制为只与参与者或只与导演一起工作。这提供了一个非常基本的、有限的分区。RDF数据也可以被划分称为命名图,命名图为我们提供了一种方法来说明三元组语句构成子图。然后我们可以给它一个唯一的标识名称,并将我们认为重要的其他信息与之关联,这种思想也与关系数据库中的视图相类似。
4. 属性图的局限性
在属性图的应用中,以下的需求是常见的但是却难以满足:
- 支持对图中模式的捕获
- 支持验证和数据完整性
- 支持捕捉丰富的规则
- 支持继承和推理
- 支持全局唯一标识符
- 支持可替换的标识符
- 图之间的连通性
- 图形可进化性的更好解决方案
这些是属性图设计中没有解决的基本限制,原则上,在属性图中添加其中一些这样的功能是可能的——但实现起来并不容易或便捷。
5. RDF图与属性图到知识图谱之间的转化
- 固有的语义使RDF图到知识图谱的转化很容易:正如前几节的内容,基于RDF的图捕获的信息不仅仅是数据,还有数据的含义或语义,这其中包括丰富的约束和高度表达的规则。所有的信息都存储在一个图中,可供查询和任何其他算法,以帮助我们推理和发现基于现有知识的新知识。也满足分离但可连接这一知识图谱的关键特性。
- 很容易从属性图转化成一个RDF标准序列化。事实上,Neo4J提供了这样一个库。你可以很容易地得到数据,但你不能得到数据的语义,这是因为数据模型只存在于最初的设计草图中。此外,正如我们所讨论的,图数据的结构可能会受到属性图数据模型的特定限制和由于属性图数据库的体系结构而需要的优化的影响。因此最简单的方法是按原样导出属性图数据,然后用RDF创建表示数据结构的数据模型。
查询语言
nGQL
nGQL 是一种类 SQL 的声明型的文本查询语言,nGQL 同样是关键词大小写不敏感的查询语言,目前支持模式匹配、聚合运算、图计算,可无嵌入组合语句。它支持图数据库:Nebula Graph。
Cypher
Cypher 是一个描述性的图形查询语言,允许不必编写图形结构的遍历代码对图形存储有表现力和效率的查询,和 SQL 很相似,Cypher 语言的关键字不区分大小写,但是属性值,标签,关系类型和变量是区分大小写的。
Cypher还在继续发展和成熟,这也就意味着有可能会出现语法的变化。同时也意味着作为组件没有经历严格的性能测试。Cypher设计的目的是一个人类查询语言,适合于开发者和在数据库上做点对点模式(ad-hoc)查询的专业操作人员(我认为这个很重要)。它的构念是基于英语单词和灵巧的图解。Cyper通过一系列不同的方法和建立于确定的实践为表达查询而激发的。许多关键字如like和order by是受SQL的启发。模式匹配的表达式来自于SPARQL。正则表达式匹配实现实用Scala programming language语言。
它支持图数据库: Neo4j、RedisGraph、AgensGraph。
Gremlin
Gremlin 是 Apache ThinkerPop 框架下的图遍历语言。Gremlin 可以是声明性的也可以是命令性的。虽然 Gremlin 是基于 Groovy 的,但具有许多语言变体,允许开发人员以 Java、JavaScript、Python、Scala、Clojure 和 Groovy 等许多现代编程语言原生编写 Gremlin 查询。它支持图数据库:Janus Graph、InfiniteGraph、Cosmos DB、DataStax Enterprise(5.0+) 、Amazon Neptune。
对于一般查询,Cypher 就足够了,而且速度可能更快。Gremlin 相对于 Cypher 的优势在于当进入高级遍历时。在 Gremlin 中,您可以更好地定义精确的遍历模式(或自己的算法),而在 Cypher 中,引擎会尝试自行寻找最佳遍历解决方案。
图基本概念
- 图Graph:指关系图。比如:同学及朋友关系图、银行转账图等。
- 顶点Vertex:一般指实体。比如:人、账户等。
- 边Edge:一般指关系。比如:朋友关系、转账动作等。
- 属性Property:顶点或边可以包含属性,比如:人的姓名、人的年龄、转账的时间。
下面使用一个例子来进一步理解上面的概念。如下图片展示了一个“软件、人”之间的关系图。

其中:
- 包括4个顶点:3个“人”顶点、一个“软件HugeGraph”顶点。
- 包括5条边:3条“创建created”边、2条“认识knows”边。
- 包括若干属性:如“HugeGraph”顶点包括“名称name”、“标签tag”、“语言lang”等属性,一个属性由
- 性名和属性值组成,如“lang:java”。
此外:
- 顶点与边有类别之分,如“HugeGraph”顶点的label是“software”、3个“人”顶点的label是“person”,在Gremlin里面称之为“label”。
- 顶点与边均由id来唯一标识,Gremlin里顶点与边必须包括id,一般图数据库的顶点id或边id均由系统自动生成。
图基本操作
对图基本概念有了初步了解之后,我们接下来学习如何使用Gremlin去操作它。首先准备好一些数据,这里以搭建环境文章中的TinkerPop关系图为例。下面将要学习的Gremlin Steps包括:V()、E()、id()、label()、properties()、valueMap()、values()。
V():查询顶点,一般作为图查询的第1步,后面可以续接的语句种类繁多(后续会一一讲解)。示例:
1
2
3
4// 查询图中所有的顶点
// 注意:g 代表的是整个图
// 一切查询都是以图开始
g.V()1
2// 根据id查询顶点
g.V('4:Gremlin', '3:TinkerPop')请尝试执行语句
g.V('4:Gremlin').in('supports')—— 查询支持Gremlin语言的所有图数据库。E():查询边,一般作为图查询的第1步,后面可以续接的语句种类繁多。示例:
1
2// 查询图中所有的边
g.E()1
2// 根据id查询边
g.E('S3:TinkerPop>4>>S4:Gremlin')id():获取顶点、边的id。示例:
1
2// 查询所有顶点的id
g.V().id()类似的,通过
g.E().id()查询所有边的id。注意:Gremlin Step是作用在上一步产生的结果集上,如果上一步的结果是多个元素,那么这里id()将返回多个元素的id。label():获取顶点、边的label。示例:
1
2// 查询所有顶点的label
g.V().label()类似的,通过
g.E().label()查询所有边的label。properties():获取顶点、边的属性。示例:
1
2// 查询所有顶点的属性
g.V().properties()1
2
3// 查询所有顶点的“lang”属性
// 如果无“lang”属性的顶点将跳过
g.V().properties('lang')类似地,通过
g.E().properties()查询所有边的属性。此外
properties()还可以和key()、value()搭配使用,以获取属性的名称或值。示例
key():1
2// 查询所有顶点的属性名称
g.V().properties().key()1
2// 查询所有顶点的属性值
g.V().properties().value()valueMap():获取顶点、边的属性,valueMap()与properties()不同的地方是:它们返回的结构不一样,后者将所有的属性扁平化到一个大列表里面,一个元素代表一个属性;前者保持一个顶点或一条边的属性作为一组,每一组由若干属性的键值对组成。示例:
1
2// 查询所有顶点的属性
g.V().valueMap()类似的,通过
g.E().valueMap()查询所有边的属性。values():获取顶点、边的属性值。示例:
1
2
3
4// 查询所有顶点的属性值
// 效果等同于:
// g.V().properties().value()
g.V().values()1
2
3
4// 查询所有顶点的“lang”属性
// 效果等同于:
// g.V().properties('lang').value()
g.V().values('lang')类似地,通过
g.E().values()查询所有边的属性值。









边遍历概念
边遍历是指通过顶点来访问与其有关联边的邻接顶点(或者仅访问邻接边),边遍历是图数据库与图计算的核心。我们先以TinkerPop官网的例子来解释一下边遍历的相关Steps:

顶点为基准的Steps(如上图中的顶点“4”):
out(label): 根据指定的EdgeLabel来访问顶点的OUT方向邻接点(可以是零个EdgeLabel,代表所有类型边;也可以一个或多个EdgeLabel,代表任意给定EdgeLabel的边,下同)in(label): 根据指定的EdgeLabel来访问顶点的IN方向邻接点both(label): 根据指定的EdgeLabel来访问顶点的双向邻接点outE(label): 根据指定的EdgeLabel来访问顶点的OUT方向邻接边inE(label): 根据指定的EdgeLabel来访问顶点的IN方向邻接边bothE(label): 根据指定的EdgeLabel来访问顶点的双向邻接边
边为基准的Steps(如上图中的边“knows”):
outV(): 访问边的出顶点(注意:这里是以边为基准,上述Step均以顶点为基准),出顶点是指边的起始顶点inV(): 访问边的入顶点,入顶点是指边的目标顶点,也就是箭头指向的顶点bothV(): 访问边的双向顶点otherV(): 访问边的伙伴顶点,即相对于基准顶点而言的另一端的顶点
实例讲解
下面通过实例来深入理解每一个操作。
out():访问顶点的OUT方向邻接点示例1:
1
2
3
4// 先查询图中所有的顶点
// 然后访问顶点的OUT方向邻接点
// 注意:out()的基准必须是顶点
g.V().out()示例2:
1
2
3
4// 访问某个顶点的OUT方向邻接点
// 注意'3:TinkerPop'是顶点的id
// 该id是插入顶点时自动生成的
g.V('3:TinkerPop').out()目前讲解过的Gremlin Steps中,顶点的id可通过
g.V()来获取,也可通过即将讲解的has()来获取(根据属性查询顶点)。示例3:
1
2
3// 访问某个顶点的OUT方向邻接点
// 且限制仅“define”类型的边相连的顶点
g.V('3:TinkerPop').out('define')1
2
3动手比一比:
g.V('3:TinkerPop').out()
g.V('3:TinkerPop').out('define', 'contains')in():访问顶点的IN方向邻接点示例1:
1
2// 访问某个顶点的IN方向邻接点
g.V('3:TinkerPop').in()示例2:
1
2
3// 访问某个顶点的IN方向邻接点
// 且限制了关联边的类型
g.V('3:TinkerPop').in('implements')both():访问顶点的双向邻接点示例1:
1
2// 访问某个顶点的双向邻接点
g.V('3:TinkerPop').both()示例2:
1
2
3// 访问某个顶点的双向邻接点
// 且限制了关联边的类型
g.V('3:TinkerPop').both('implements', 'define')outE(): 访问顶点的OUT方向邻接边示例1:
1
2// 访问某个顶点的OUT方向邻接边
g.V('3:TinkerPop').outE()示例2:
1
2
3// 访问某个顶点的OUT方向邻接边
// 且限制了关联边的类型
g.V('3:TinkerPop').outE('define')inE(): 访问顶点的IN方向邻接边示例1:
1
2// 访问某个顶点的IN方向邻接边
g.V('3:TinkerPop').inE()示例2:
1
2
3// 访问某个顶点的IN方向邻接边
// 且限制了关联边的类型
g.V('3:TinkerPop').inE('implements')bothE(): 访问顶点的双向邻接边示例1:
1
2// 访问某个顶点的双向邻接边
g.V('3:TinkerPop').bothE()示例2:
1
2
3// 访问某个顶点的双向邻接边
// 且限制了关联边的类型
g.V('3:TinkerPop').bothE('define', 'implements')outV(): 访问边的出顶点示例1:
1
2
3// 访问某个顶点的IN邻接边
// 然后获取边的出顶点
g.V('3:TinkerPop').inE().outV()一般情况下,
inE().outV()等价于in()动手试一试:
g.V('3:TinkerPop').outE().outV()inV(): 访问边的入顶点示例1:
1
2
3// 访问某个顶点的OUT邻接边
// 然后获取边的入顶点
g.V('3:TinkerPop').outE().inV()一般情况下,
outE().inV()等价于out()动手试一试:
g.V('3:TinkerPop').inE().inV()bothV(): 访问边的双向顶点示例1:
1
2
3// 访问某个顶点的OUT邻接边
// 然后获取边的双向顶点
g.V('3:TinkerPop').outE().bothV()注意:
bothV()会把源顶点也一起返回,因此只要源顶点有多少条出边,结果集中就会出现多少次源顶点otherV(): 访问边的伙伴顶点示例1:
1
2
3// 访问某个顶点的OUT邻接边
// 然后获取边的伙伴顶点
g.V('3:TinkerPop').outE().otherV()一般情况下,
outE().otherV()等价于out(),inE().otherV()等价于in()。示例2:
1
2
3// 访问某个顶点的双向邻接边
// 然后获取边的伙伴顶点
g.V('3:TinkerPop').bothE().otherV()一般情况下,
bothE().otherV()等价于both()。


















综合运用
多度查询
1
2
3
4
5
6
7// 4度out()查询
// 通过id找到“javeme”作者顶点
// 通过out()访问其创建的软件
// 继续通过out()访问软件实现的框架
// 继续通过out()访问框架包含的软件
// 继续通过out()访问软件支持的语言
g.V('javeme').out('created').out('implements').out('contains').out('supports')查询支持Gremlin语言的软件的作者
1
2
3
4// 通过id找到“Gremlin”语言顶点
// 通过in()访问支持Gremlin的软件
// 继续通过in()访问软件的作者
g.V('4:Gremlin').in('supports').in('created')查询某个作者的共同作者
1
2
3
4// 通过id找到“javeme”作者顶点
// 通过out()访问其创建的软件
// 通过in()访问软件的所有作者
g.V('javeme').out('created').in('created')



Has Step说明
在众多Gremlin的语句中,有一大类是filter类型,顾名思义,就是对输入的对象进行条件判断,只有满足过滤条件的对象才可以通过filter进入下一步。
has语句是filter类型语句的代表,能够以顶点和边的属性作为过滤条件,决定哪些对象可以通过。has语句包括很多变种:
hasLabel(labels…): object的label与labels列表中任何一个匹配就可以通过hasId(ids…): object的id满足ids列表中的任何一个就可以通过has(key, value): 包含属性“key=value”的object通过,作用于顶点或者边has(label, key, value): 包含属性“key=value”且label值匹配的object通过,作用于顶点或者边has(key, predicate): 包含键为key且对应的value满足predicate的object通过,作用于顶点或者边hasKey(keys…): object的属性键包含所有的keys列表成员才能通过,作用于顶点属性hasValue(values…): object的属性值包含所有的values列表成员才能通过,作用于顶点属性has(key): 包含键为key的属性的object通过,作用于顶点或者边hasNot(key): 不包含键为key的属性的object通过,作用于顶点或者边
TinkerPop规范中,也可以对Vertex Property进行has()操作,前提是图支持meta-property。HugeGraph不支持meta-property,因此本文不会有Vertex Property相关的has()示例。
实例讲解
在HugeGraph中,按property的值查询之前,应该对property建立索引,否则将无法查到结果并引发异常。(有两个例外,Vertex的PrimaryKeys和Edge的SortKeys,具体参见HugeGraph官网)
1 | // 对‘person’的‘addr’属性建立secondary索引,可以对Text类型property按值进行查询 |
hasLabel(label...),通过label来过滤顶点或边,满足label列表中一个即可通过1
2// 查询label为"person"的顶点
g.V().hasLabel('person')1
2// 查询label为"person"或者"software"的顶点
g.V().hasLabel('person', 'software')hasId(ids…),通过id来过滤顶点或者边,满足id列表中的一个即可通过1
2// 查询id为"zhoney"的顶点
g.V().hasId('zhoney')1
2// 查询id为“zhoney”或者“3:HugeGraph”的顶点
g.V().hasId('zhoney', '3:HugeGraph')has(key, value),通过属性的名字和值来过滤顶点或边1
2// 查询“addr”属性值为“Beijing”的顶点
g.V().has('addr', 'Beijing')has(label, key, value),通过label和属性的名字和值过滤顶点和边1
2// 查询label为“person”且“addr”属性值为“Beijing”的顶点
g.V().has('person', 'addr', 'Beijing')has(key, predicate),通过对指定属性用条件过滤顶点和边1
2// 查询“addr”属性值为“Beijing”的顶点
g.V().has('age', gt(20))hasKey(keys…): properties包含所有的key才能通过1
2// 查询包含属性“lang”的顶点
g.V().properties().hasKey('lang')
特殊用法:直接将
hasKey()作用于顶点,仅后端是Cassandra时支持1
2// 查询包含属性“age”的顶点
g.V().hasKey('age')HugeGraph目前不支持
hasKey()传递多个key。hasValue(values…): properties包含所有的value才能通过1
2// 查询包含属性值“Beijing”的顶点
g.V().properties().hasValue('Beijing')
特殊用法:直接将
hasValue()作用于顶点,仅后端是Cassandra时支持1
2// 查询包含属性值“Beijing”的顶点
g.V().hasValue('Beijing')has(key): 有这个属性的通过1
2// 查询包含属性“age”的顶点
g.V().has('age')hasNot(key): 没有这个属性的通过1
2// 查询没有属性“age”的顶点
g.V().hasNot('age')由于
has()语句对Vertex和Edge的用法一样,本文仅给出了Vertex的示例。Edge的大家可以自行尝试。











图查询返回结果数限制

Gremlin能统计查询结果集中元素的个数,且允许从结果集中做范围截取。假设某个查询操作(如:g.V())的结果集包含8个元素,我们可以从这8个元素中截取指定部分。主要包括:
count(): 统计查询结果集中元素的个数;range(m, n): 指定下界和上界的截取,左闭右开。比如range(2, 5)能获取第2个到第4个元素(0作为首个元素,上界为-1时表示剩余全部);limit(n): 下界固定为0,指定上界的截取,等效于range(0, n),语义是“获取前n个元素”。比如limit(3)能获取前3个元素;tail(n): 上界固定为-1,指定下界的截取,等效于range(count - n, -1),语义是“获取后n个元素”。比如tail(2)能获取最后的2个元素;skip(n): 上界固定为-1,指定下界的截取,等效于range(n, -1),语义是“跳过前n个元素,获取剩余的元素”。比如skip(6)能跳过前6个元素,获取最后2个元素。
实例讲解
下面通过实例来深入理解每一个操作。
count():查询当前traverser中的元素的个数,元素可以是顶点、边、属性、路径等。示例1:查询图中所有顶点的个数
1
g.V().count()
TinkerPop关系图的圆点就是顶点,总共12个。示例2:查询图中类型为“人person”的顶点数
1
g.V().hasLabel('person').count()
TinkerPop关系图的绿点就是类型为“人person”的顶点,共7个。示例3:查询图中所有的 “人创建created” 的边数
1
g.V().hasLabel('person').outE('created').count()
TinkerPop关系图的所有从绿点(person)出发并且连线上为“created”的边,共8个。示例4:查询图中所有顶点的属性数
1
g.V().properties().count()
TinkerPop关系图的所有顶点的属性共47个,其中“人person”共有28个,“软件software”共有19个,大家可以自己数一数。range():限定查询返回的元素的范围,上下界表示元素的偏移量,左闭右开。下界以“0”作为第一个元素,上界为“-1”时表示取到最后的元素。示例1:不加限制地查询所有类型为“人person”的顶点
1
g.V().hasLabel('person').range(0, -1)
示例2:查询类型为“人person”的顶点中的第2个到第5个
1
g.V().hasLabel('person').range(2, 5)
示例3:查询类型为“人person”的顶点中的第5个到最后一个
1
g.V().hasLabel('person').range(5, -1)
limit():查询前n个元素,相当于range(0, n)示例1:查询前两个顶点
1
g.V().limit(2)
示例2:查询前三条边
1
g.E().limit(3)
tail():与limit()相反,它查询的是后n个元素,相当于range(count - n, -1)示例1:查询后两个顶点
1
g.V().tail(2)
示例2:查询后三条边
1
g.E().tail(3)
skip():跳过前n个元素,获取剩余的全部元素skip()在HugeGraph中(tinkerpop 3.2.5)中尚不支持,下面给出代码以及预期的结果。1
2// 跳过前5个,skip(5)等价于range(5, -1)
g.V().hasLabel('person').skip(5)
Path说明
在使用Gremlin对图进行分析时,关注点有时并不仅仅在最终到达的顶点、边或者属性上,通过什么样的路径到达最终的顶点、边和属性同样重要。此时可以借助path()来获取经过的路径信息。
path()返回当前遍历过的所有路径。有时需要对路径进行过滤,只选择没有环路的路径或者选择包含环路的路径,Gremlin针对这种需求提供了两种过滤路径的step:simplePath()和cyclicPath()。
实例讲解
path(),获取当前遍历过的所有路径示例1:
1
2// “HugeGraph”顶点到与其有直接关联的顶点的路径(仅包含顶点)
g.V().hasLabel('software').has('name','HugeGraph').both().path()示例2:
如果想要同时获得经过的边的信息,可以用bothE().otherV()替换both()1
2// “HugeGraph”顶点到与其有直接关联的顶点的路径(包含顶点和边)
g.V().hasLabel('software').has('name','HugeGraph').bothE().otherV().path()示例3:
输出路径的时候,通过by(property)语句可以指定对象的某个属性代替对象,且连续的多个by()是循环应用到路径中的对象,例如路径中有3个对象[A, B, C],by(X).by(Y)语句指定两个属性[X Y],代表用“用A的X属性代表A,用B的Y属性代表B,用C的X属性代表C”,具体可参考如下例子:by()语句的用法详解可以参见TinkerPop By Step1
2
3// “HugeGraph”顶点到与其有直接关联的顶点的路径(包含顶点和边)
// 用“name”属性代表person和software顶点,用“weight”属性代表边
g.V().hasLabel('software').has('name','HugeGraph').bothE().otherV().path().by('name').by('weight')示例4:
路径分为两种:有环路径和无环路径。- 有环路径是指路径中至少有一个对象出现的次数大于等于两次。
- 无环路径是指路径中所有的对象只出现一次。
path()返回所有路径,包含有环路径和无环路径,例如:1
2// “HugeGraph”顶点到与其有两层关系的顶点的所有路径(只包含顶点)
g.V().hasLabel('software').has('name','HugeGraph').both().both().path()图中红框内的是含有环路的路径,其他的是不含有环路的路径
simplePath(),过滤掉路径中含有环路的对象,只保留路径中不含有环路的对象1
2// “HugeGraph”顶点到与其有两层关系的顶点的不含环路的路径(只包含顶点)
g.V().hasLabel('software').has('name','HugeGraph').both().both().simplePath().path()cyclicPath(),过滤掉路径中不含有环路的对象,只保留路径中含有环路的对象1
2// “HugeGraph”顶点到与其有两层关系的顶点的包含环路的路径(只包含顶点)
g.V().hasLabel('software').has('name','HugeGraph').both().both().cyclicPath().path()






循环操作说明
循环操作是指多次执行某一部分语句,用于语句需要重复运行的场景,比如“查找朋友的朋友的朋友”,可以直接使用循环操作来完成即“查找3层朋友”,下面对具体的循环相关的Step进行说明:
repeat(): 指定要重复执行的语句,如repeat(out('friend'))times(): 指定要重复执行的次数,如执行3次repeat(out('friend')).times(3)until(): 指定循环终止的条件,如一直找到某个名字的朋友为止repeat(out('friend')).until(has('name','xiaofang'))emit(): 指定循环语句的执行过程中收集数据的条件,每一步的结果只要符合条件则被收集,不指定条件时收集所有结果loops(): 当前循环的次数,可用于控制最大循环次数等,如最多执行3次repeat(out('friend')).until(loops().is(3))
实例讲解
下面通过实例来深入理解每一个操作。
repeat()+times():按照指定的次数重复执行语句示例1:
1
2
3// 访问某个顶点的OUT邻接点(1次)
// 注意'okram'是顶点的id
g.V('okram').repeat(out()).times(1)示例2:
1
2
3
4// 访问某个顶点的2度双向邻接点
// 访问第1个顶点的所有邻接点(第1层)
// 再访问第1层结果顶点的邻接点(第2层)
g.V('okram').repeat(both()).times(2)示例3:
1
2
3
4
5// 访问某个顶点的3度OUT邻接点
// 访问第1个顶点的所有邻接点(第1层)
// 再访问第1层结果顶点的邻接点(第2层)
// 再访问第2层结果顶点的邻接点(第3层)
g.V('okram').repeat(out()).times(3)比一比:
1
2g.V('okram').out().out().out()
g.V('okram').repeat(out()).times(3)repeat()+until():根据条件来重复执行语句示例1:
1
2
3
4
5
6// 查询顶点'okram'到顶点'Gremlin'之间的路径
// 循环的终止条件是遇到名称是'Gremlin'的顶点
g.V('okram')
.repeat(out())
.until(has('name', 'Gremlin'))
.path()- 注意1:这里用到了
path()来获取经过的路径,path的讲解请参考上一期。 - 注意2:
until()与times()是互斥的,两个语句无法同时存在于同一个循环中。 - 注意3:
until()放在repeat()之前或之后的顺序是会影响逻辑的,放前面表示先判断再执行,放后面表示先执行后判断。请对比如下两个语句的执行结果:g.V('okram').repeat(out()).until(hasLabel('person')).path()g.V('okram').until(hasLabel('person')).repeat(out()).path()
- 注意1:这里用到了
repeat()+emit():收集执行过程中的数据示例1:
1
2
3
4
5// 查询顶点'okram'的所有OUT可达点的路径
g.V('okram')
.repeat(out())
.emit()
.path()示例2:
1
2
3
4
5
6// 查询顶点'okram'的所有OUT可达点的路径
// 且必须满足是'person'类型的点
g.V('okram')
.repeat(out())
.emit(hasLabel('person'))
.path()注意:
emit()放在repeat()之前或之后的顺序是会影响结果的,放前面表示先收集再执行,放后面表示先执行后收集。请对比如下两个语句的执行结果:g.V('okram').repeat(out()).emit(hasLabel('person')).path()g.V('okram').emit(hasLabel('person')).repeat(out()).path()
示例3:1
2
3
4
5
6
7// 查询顶点'okram'到顶点'Gremlin'之间的路径
// 此外还收集过程中的'person'类型的顶点
g.V('okram')
.repeat(out())
.until(has('name', 'Gremlin'))
.emit(hasLabel('person'))
.path()注意:
emit()与until()搭配使用时,是“或”的关系而不是“与”的关系,满足两者间任意一个即可。示例4:
1
2
3
4
5
6// 查询顶点'okram'的2度OUT可达点的路径
// 此外还收集'person'类型的顶点
g.V('okram')
.repeat(out()).times(2)
.emit(hasLabel('person'))
.path()注意:
emit()与times()搭配使用时,是“或”的关系而不是“与”的关系,满足两者间任意一个即可。repeat()+loops():根据最大次数限制来重复执行语句示例1:
1
2
3
4
5// 查询顶点'okram'的3度OUT可达点路径
g.V('okram')
.repeat(out())
.until(loops().is(3))
.path()示例2:
1
2
3
4
5
6
7
8// 查询顶点'okram'到顶点'Gremlin'之间的路径
// 且之间只相差2跳的距离
// 其中的and()是指两个条件都满足
g.V('okram')
.repeat(out())
.until(has('name', 'Gremlin')
.and().loops().is(2))
.path()










综合运用
查找子树
1
2
3
4
5
6
7// 查找从一个节点出发,到
// 叶子节点结束的所有路径
// 这些路径的集合为一颗子树(子图)
g.V('okram')
.repeat(out())
.until(outE().count().is(0))
.path()查找两点之间的最短路径
1
2
3
4
5
6
7
8
9// 已知两个顶点'okram'和'javeme',
// 通过任意关系来找到这两点之间的路径
// 且限制了最大深度为3
// 若存在那么第一条结果即是最短路径
g.V('okram')
.repeat(bothE().otherV().simplePath())
.until(hasId('javeme').and().loops().is(lte(3)))
.hasId('javeme')
.path()注意:
bothE().otherV()一般等价于both(),但是在这里有一些差别,后者仅仅返回路径中的顶点信息,前者会把路径中的边信息也返回。试一试:将语句中的
lte(3)改为lte(4)看看结果有什么变化


条件和过滤操作说明
在对图进行遍历分析时,经常需要对满足一定条件的对象进行过滤。where()就是用来过滤遍历过程中当前阶段的对象。另一方面,predicate就是过滤时使用的判断条件,包括关系运算和区间判断等,只有满足判断条件的对象才能通过进入下一轮或者作为结果。
where()常与select()或者match()配合使用,也可以单独使用。
以下是predicate的说明:
| Predicate | Description |
|---|---|
| eq(object) | 传入的对象等于目标object? |
| neq(object) | 传入的对象不等于目标object? |
| lt(number) | 传入的数字小于目标number? |
| lte(number) | 传入的数字小于或等于目标number? |
| gt(number) | 传入的数字大于目标number? |
| gte(number) | 传入的数字大于或等于目标number? |
| inside(low,high) | 传入的数字大于low且小于high? |
| outside(low,high) | 传入的数字小于low或者大于high? |
| between(low,high) | 传入的数字大于等于low且小于high? |
| within(objects…) | 传入的对象等于目标对象列表objects中的任意一个? |
| without(objects…) | 传入的对象不等于目标对象列表objects中的任何一个? |
逻辑运算and()、or()或者not()作用于predicate会产生一个新的predicate。
在众多的Gremlin steps中,有一大类是filter step,通过判断是否满足predicate来决定对象能否通过filter step。filter()语句是filter step的基础,较为抽象,而更加具体的where()语句就是一个典型的filter step。
实例讲解
predicate可以通过test()来获得boolean值可以用
test()测试value是否满足predicate,以下是一些例子:示例1:
1
2// (3 == 2)
eq(2).test(3)示例2:
1
2// ('d' == 'a' || 'd' == 'b' || 'd' == 'c')
within('a','b','c').test('d')示例3:
1
2// (3 > 1 && 3 < 4)
inside(1,4).test(3)and/or/not作用于predicate之后成为新的predicate示例1:
1
2// not()作用于neq(),等价于eq()
not(neq(2))示例2:
1
2// and()连接的predicate,是一个新的predicate
within(1,2,3).and(not(eq(2))).test(3)示例3:
1
2// or()连接的predicate,是一个新的predicate
inside(1,4).or(eq(5)).test(3)where()单独使用where()有三种使用方式:where(P)where(String, P)where(Traversal)
示例1:
1
2
3
4
5// 查看“zhoney”的合作伙伴
// where(P)方式
g.V('zhoney').as('a')
.out('created').in('created')
.where(neq('a'))示例2:
1
2
3
4
5// 查看“zhoney”的合作伙伴
// where(String, P)方式
g.V('zhoney').as('a')
.out('created').in('created').as('b')
.where('a',neq('b'))示例3:
1
2
3
4
5// “spmallette”开发过不止一个软件的合作伙伴
// where(Traversal)方式
g.V('spmallette').out('created').in('created')
.where(out('created').count().is(gt(1)))
.values('name')where()可以与by()语句配合使用,表示用by(property)指定的属性进行predicate判断,例如下面的例子。示例4:
1
2
3
4
5// 查询”被别人认识“
// 且认识自己的人的年龄大于自己的年龄的人
g.V().as('a')
.out('knows').as('b')
.where('a', gt('b')).by('age')where()与as()+select()配合使用as()可以为某一阶段的对象添加标签,select()则可以通过标签获取对象。因此as()+select()可以在某个step处得到历史信息。1
2
3
4
5
6// 查看“zhoney”的合作伙伴,并将“zhoney”及其合作伙伴的名字以map输出
// select().where()方式
g.V('zhoney').as('a')
.out('created').in('created').as('b')
.select('a','b').by('name')
.where('a',neq('b'))where()与match()配合使用match()可以保证满足某种模式的对象通过。1
2
3
4
5
6// 查看“zhoney”的合作伙伴,并将“zhoney”及其合作伙伴的名字以map输出
// match().where()方式
g.V('zhoney').match(__.as('a').out('created').as('b'),
__.as('b').in('created').as('c')).
where('a', neq('c'))
.select('a','c').by('name')filter()filter()有三种用法:- lambda方式,
filter{it.get()…} - Traversal方式,
filter(Traversal) - 特定filter step方式
示例1:
1
2
3// 查找图中的“person”顶点
// lambda方式
g.V().filter {it.get().label() == 'person'}示例2:
1
2
3// 查找图中的“person”顶点
// Traversal方式
g.V().filter(label().is('person'))示例3:
1
2
3// 查找图中的“person”顶点
// 特定filter step方式
g.V().hasLabel('person')- lambda方式,















逻辑运算说明
Gremlin支持在遍历器上加上逻辑运算进行过滤,只有满足该逻辑条件的元素才会进入下一个遍历器中。
下面讲解实现上述功能的具体Step:
is():可以接受一个对象(能判断相等)或一个判断语句(如:P.gt()、P.lt()、P.inside()等),当接受的是对象时,原遍历器中的元素必须与对象相等才会保留;当接受的是判断语句时,原遍历器中的元素满足判断才会保留,其实接受一个对象相当于P.eq();and():可以接受任意数量的遍历器(traversal),原遍历器中的元素,只有在每个新遍历器中都能生成至少一个输出的情况下才会保留,相当于过滤器组合的与条件;or():可以接受任意数量的遍历器(traversal),原遍历器中的元素,只要在全部新遍历器中能生成至少一个输出的情况下就会保留,相当于过滤器组合的或条件;not():仅能接受一个遍历器(traversal),原遍历器中的元素,在新遍历器中能生成输出时会被移除,不能生成输出时则会保留,相当于过滤器的非条件。
这四种逻辑运算Step除了像一般的Step写法以外,and()和or()还可以放在where()中以中缀符的形式出现。
实例讲解
下面通过实例来深入理解每一个操作。
is()示例1:
1
2// 筛选出顶点属性“age”等于28的属性值,与`is(P.eq(28))`等效
g.V().values('age').is(28)当没有任何一个顶点的属性“age”为28时,输出为空。
示例2:
1
2// 筛选出顶点属性“age”大于等于28的属性值
g.V().values('age').is(gte(28))示例3:
1
2// 筛选出顶点属性“age”属于区间(27,29)的属性值
g.V().values('age').is(inside(27, 29))P.inside(a, b)是左开右开区间(a,b)示例4:
1
2
3// 筛选出由两个或两个以上的人参与创建(“created”)的顶点
// 注意:这里筛选的是顶点
g.V().where(__.in('created').count().is(gt(2))).values('name')where()Step可以接受一些过滤条件。示例5:
1
2// 筛选出有创建者(“created”)的年龄(“age”)在20~29之间的顶点
g.V().where(__.in('created').values('age').is(between(20, 29))).values('name')between是左闭右闭区间[a,b]and(),逻辑与示例1:
1
2// 所有包含出边“supports”的顶点的名字“name”
g.V().and(outE('supports')).values('name')示例2:
1
2// 所有包含出边“supports”和“implements”的顶点的名字“name”
g.V().and(outE('supports'), outE('implements')).values('name')示例3:
1
2// 包含边“created”并且属性“age”为28的顶点的名字“name”
g.V().and(outE('created'), values('age').is(28)).values('name')示例4:“示例3”的中缀符写法
1
2
3
4
5// 包含边“created”并且属性“age”为28的顶点的名字“name”
g.V().where(outE('created')
.and()
.values('age').is(28))
.values('name')or(),逻辑或示例1:
1
2// 所有包含出边“supports”的顶点的名字“name”
g.V().or(outE('supports')).values('name')只有一个条件时,
and()与or()的效果一样的。示例2:
1
2// 所有包含出边“supports”或“implements”的顶点的名字“name”
g.V().or(outE('supports'), outE('implements')).values('name')注意对比与
g.V().and(outE('supports'), outE('implements')).values('name')的差别。示例3:
1
2// 包含边“created”或属性“age”为28的顶点的名字“name”
g.V().or(outE('created'), values('age').is(28)).values('name')注意对比与
g.V().and(outE('created'), values('age').is(28)).values('name')的差别。示例4:“示例3”的中缀符写法
1
2
3
4
5// 包含边“created”或属性“age”为28的顶点的名字“name”
g.V().where(outE('created')
.or()
.values('age').is(28))
.values('name')not(),逻辑非示例1:
1
2// 筛选出所有不是“person”的顶点的“label”
g.V().not(hasLabel('person')).label()示例2:
1
2// 筛选出所有包含不少于两条(大于等于两条)“created”边的“person”的名字“name”
g.V().hasLabel('person').not(out('created').count().is(lt(2))).values('name')
综合运用
目标:获取所有最多只有一条“created”边并且年龄不等于28的“person”顶点
写法1:
1 | // 与(含有小于等于一条“created”边,年龄不等于28) |
写法2:
1 | // 非(或(含有多于一条“created”边,年龄等于28)) |
统计运算说明
Gremlin可以在Number类型的流(遍历器)上做简单的统计运算,包括计算总和、最大值、最小值、均值。
下面讲解实现上述功能的具体Step:
sum():将流上的所有的数字求和;max():对流上的所有的数字求最大值;min():对流上的所有的数字求最小值;mean():将流上的所有的数字求均值;
这四种Step只能作用在Number类型的流上,在java里就是继承自java.lang.Number类。
实例讲解
下面通过实例来深入理解每一个操作。
sum()示例1:
1
2// 计算所有“person”的“age”的总和
g.V().hasLabel('person').values('age').sum()示例2:
1
2// 计算所有“person”的“created”出边数的总和
g.V().hasLabel('person').map(outE('created').count()).sum()试着输入
g.V().hasLabel('person').map(outE('created').count())看看每个“person”的“created”出边数。max()示例1:
1
2// 计算所有“person”的“age”中的最大值
g.V().hasLabel('person').values('age').max()示例2:
1
2// 计算所有“person”的“created”出边数的最大值
g.V().hasLabel('person').map(outE('created').count()).max()min()示例1:
1
2// 计算所有“person”的“age”中的最小值
g.V().hasLabel('person').values('age').min()示例2:
1
2// 计算所有“person”的“created”出边数的最小值
g.V().hasLabel('person').map(outE('created').count()).min()mean()示例1:
1
2// 计算所有“person”的“age”的均值
g.V().hasLabel('person').values('age').mean()示例2:
1
2// 计算所有“person”的“created”出边数的均值
g.V().hasLabel('person').map(outE('created').count()).mean()
数学运算说明
在Gremlin中有一个专门负责科学计算功能的step math()。math() 不同于常见的函数组合和嵌套形式,提供了一种易于读取的基于字符串的数学处理器。
math()支持by(),其中多个by()按照在math()运算表达式中首次引用变量的顺序应用。- 保留变量
_是指传入math()的当前遍历器对象。
math()支持的运算符包括:+,-,*,/,%,^。
math()支持的内嵌函数包括:
abs: absolute value,绝对值acos: arc cosine,反余弦asin: arc sine,反正弦atan: arc tangent,反正切cbrt: cubic root,立方根ceil: nearest upper integer,向上最接近的整数cos: cosine,余弦cosh: hyperbolic cosine,双曲余弦exp: euler’s number raised to the power (e^x),以e为底的指数floor: nearest lower integer,向下最近接的整数log: logarithmus naturalis (base e),以e为底的对数log10: logarithm (base 10),以10为底的对数log2: logarithm (base 2),以2为底的对数sin: sine,正弦sinh: hyperbolic sine,双曲正弦sqrt: square root,平方根tan: tangent,正切tanh: hyperbolic tangent,双曲正切signum: signum function,签名功能
实例说明
math中的floor语句1
2
3
4// 比如按照年龄段进行统计
g.V().hasLabel('person')
.groupCount().by(values('age').math('floor(_/10)*10'))
.order(local).by(values,desc)
更多资料可以先参考TinkerPop官网对于math()step的实例说明
路径选取与过滤说明
Gremlin支持从走过的路径里选取部分数据作为结果,并且可以在选取时进行条件过滤。
下面讲解实现上述功能的具体Step:
as()+select(): 对路径中结果进行选取,首先通过as(label)对任意步骤打上标签,然后使用select(label)来选取若干历史步骤的结果作为新结果。此外还可通过select().by(property)来指定根据什么维度进行选取。as()+where(): 以条件匹配的方式进行路径结果选取,只有符合条件的路径才能被选取出来。as()+match(): 以模式匹配的方式进行路径结果选取,只有符合模式的路径才能被选取出来。as()+dedup(): 根据路径中的若干步骤的结果进行去重,只有首次出现的路径段才能被选取出来。
实例讲解
下面通过实例来深入理解每一个操作。
as()...select():对路径中结果进行选取示例1:
1
2
3
4
5// 从路径中选取第1步和第3步的结果作为最终结果
g.V('2:HugeGraph').as('a')
.out().as('b')
.out().as('c')
.select('a', 'c')
对比:不选取时获取的完整路径
1
2
3
4g.V('2:HugeGraph').as('a')
.out().as('b')
.out().as('c')
.path()
示例2:
1
2
3
4// 从集合中选择最后一个元素
g.V('2:HugeGraph').as("a")
.repeat(out().as("a")).times(2)
.select(last, "a")
试一试:
1
2select(all, "a")
select(first, "a")示例3:
1
2
3
4
5
6// 通过by()来指定选取的维度
g.V('2:HugeGraph').as('a')
.out().as('b')
.out().as('c')
.select('a', 'c')
.by('name').by('name')
示例4(特殊用法:map选择):
1
2// 从map中选择指定key的值
g.V().valueMap().select('tag').dedup()
as()...where():以条件匹配的方式进行路径结果选取示例1:
1
2
3
4
5// 选取满足第1步和第3步“lang”属性相等的路径
g.V('2:HugeGraph').as('a')
.out().as('b').out().as('c')
.where('a', eq('c')).by('lang')
.select('a', 'b', 'c').by(id)
as()+match():以模式匹配的方式进行路径结果选取示例1:
1
2
3
4
5
6
7// 选取满足两个模式的路径:
// 1.第3步有OUT节点
// 2.第3步的OUT节点的指定路径不允许回到第二步的节点
g.V('2:HugeGraph').as('a').out().as('b')
.match(__.as('b').out().as('c'),
__.not(__.as('c').out().in('define').as('b')))
.select('a','b','c').by(id)
as()+debup():路径去重示例1:
1
2
3
4// 以路径中的前3步作为去重依据,对路径进行去重
g.V('2:HugeGraph').as('a')
.out().as('b').out().as('c').in()
.dedup('a', 'b', 'c').path()
综合运用
查询支持Gremlin语言的软件,至少由2个相互认识的且在北京的作者完成
1
2
3
4
5
6
7
8
9
10
11
12// 获取支持Gremlin语言的软件,
// 并且作者是至少为2个相互认识的人,
// 且这两个作者都在北京
g.V('3:Gremlin').in('supports').as('software')
.match(
__.as('software').in('created').as('person1'),
__.as('person1').both('knows').as('person2'),
__.as('person2').out('created').as('software'),
__.as('person1').has('addr', 'Beijing'),
__.as('person2').has('addr', 'Beijing')
)
.select('software').dedup()
查询支持Gremlin语言的软件的作者,并按边权重排序
1
2
3
4
5
6
7
8// 获取支持Gremlin语言的软件,
// 并查找其作者,并对中间经过的边打标签
// 按照边的权重进行排序
// 选取软件、权重、作者作为结果
g.V('3:Gremlin').in('supports').as('s')
.inE('created').as('e').outV().as('t')
.order().by(select('e').by('weight'), decr)
.select('s', 'e', 't').by('name').by('weight')
分支操作说明
在对图进行遍历分析时,有时需要根据某些条件对当前的对象集合进行不同的操作,也就是if-then-else语法结构。Gremlin中有一类step可以满足这种分支需求,这组step叫做branch step。branch()是这类step的基础,比较抽象,而choose()是典型的branch step。
choose()的基本使用方法有两类:
- 单独使用,
choose(predicate, true-traversal, false-traversal):根据predicate判断,当前对象满足时,继续true-traversal,否则继续false-traversal - 与option配合使用,
choose(traversal).option(value1, traversal1).option(...)...:根据对象通过traversal的结果决定后续操作,如果结果是value1,则该对象继续traversal1,以此类推
option()不是一种Gremlin step,只是一种辅助语法,可与choose()配合使用。
实例讲解
if-then-else型choose()语句1
2
3
4
5
6
7
8// 查找所有的“person”类型的顶点
// 如果“age”属性小于等于20,输出他的朋友的名字
// 如果“age”属性大于20,输出他开发的软件的名字
// choose(condition, true-action, false-action)
g.V().hasLabel('person')
.choose(values('age').is(lte(20)),
__.in('knows'),
__.out('created')).values('name')option()型choose()语句1
2
3
4
5
6
7
8
9
10// 查找所有的“person”类型的顶点
// 如果“age”属性等于0,输出名字
// 如果“age”属性等于28,输出年龄
// 如果“age”属性等于29,输出他开发的软件的名字
// choose(predicate).option().option()...
g.V().hasLabel('person')
.choose(values('age'))
.option(0, values('name'))
.option(28, values('age'))
.option(29, __.out('created').values('name'))如果
choose(predicate, true-traversal, false-traversal)中false-traversal为空或者是identity(),则不满足条件的对象直接通过choose()1
2
3
4
5
6// 查找所有顶点,
// 类型为“person”的顶点输出其创建的软件的“name”属性
// 否则输出顶点自身的“name”属性
g.V().choose(hasLabel('person'),
out('created'))
.values('name')choose()和option()配合使用时,还提供了一个none,不满足其他选项的对象,执行none选项的traversal1
2
3
4
5
6
7// 查找所有类型为“person”的顶点,
// “name”属性为“Zhoney Zhang”的输出其“age”属性
// 否则输出顶点的“name”属性
g.V().hasLabel('person')
.choose(values('name'))
.option('Zhoney Zhang', values('age'))
.option(none, values('name'))branch()branch()有三种用法:- lambda方式,
branch{it.get()…} - Traversal方式,
branch(Traversal) - 特定branch step方式
1
2
3
4
5
6
7// 查询所有顶点
// “name”属性值为“HugeGraph”的顶点输出其“lang”属性
// “name”属性值不为“HugeGraph”的顶点输出其“name”属性
// lambda方式
g.V().branch {it.get().value('name')}
.option('HugeGraph', values('lang'))
.option(none, values('name'))1
2
3
4
5
6
7// 查询所有顶点
// “name”属性值为“HugeGraph”的顶点输出其“lang”属性
// “name”属性值不为“HugeGraph”的顶点输出其“name”属性
// traversal方式
g.V().branch(values('name'))
.option('HugeGraph', values('lang'))
.option(none, values('name'))1
2
3
4
5
6
7// 查询所有顶点
// “name”属性值为“HugeGraph”的顶点输出其“lang”属性
// “name”属性值不为“HugeGraph”的顶点输出其“name”属性
// 特定branch step方式
g.V().choose(has('name','HugeGraph'),
values('lang'),
values('name'))- lambda方式,







合并操作说明
coalesce: 可以接受任意数量的遍历器(traversal),按顺序执行,并返回第一个能产生输出的遍历器的结果;optional: 只能接受一个遍历器(traversal),如果该遍历器能产生一个结果,则返回该结果,否则返回调用optionalStep的元素本身。当连续使用.optional()时,如果在某一步返回了调用元素本身,则后续的.optional()不会继续执行;union: 可以接受任意数量的遍历器(traversal),并能够将各个遍历器的输出合并到一起;
实例讲解
下面通过实例来深入理解每一个操作。
coalesce()示例1:
1
2
3
4
5// 按优先级寻找到顶点“HugeGraph”的以下边和邻接点,找到一个就停止
// 1、“implements”出边和邻接点
// 2、“supports”出边和邻接点
// 3、“created”入边和邻接点
g.V('3:HugeGraph').coalesce(outE('implements'), outE('supports'), inE('created')).inV().path().by('name').by(label)HugeGraph这三类边都是存在的,按照优先级,返回了“implements”出边和邻接点。
示例2:
1
2
3
4
5// 按优先级寻找到顶点“HugeGraph”的以下边和邻接点,找到一个就停止(调换了示例1中的1和2的顺序)
// 1、“supports”出边和邻接点
// 2、“implements”出边和邻接点
// 3、“created”入边和邻接点
g.V('3:HugeGraph').coalesce(outE('supports'), outE('implements'), inE('created')).inV().path().by('name').by(label)这次由于“supports”放在了“implements”的前面,所以返回了“supports”出边和邻接点。
自己动手比较一下
outE('supports'), outE('implements'), inE('created')在.coalesce()中随意调换顺序的区别。optional()示例1:
1
2// 查找顶点"linary"的“created”出顶点,如果没有就返回"linary"自己
g.V('linary').optional(out('created'))示例2:
1
2// 查找顶点"linary"的“knows”出顶点,如果没有就返回"linary"自己
g.V('linary').optional(out('knows'))示例3:
1
2// 查找每个“person”顶点的出“knows”顶点,如果存在,然后以出“knows”顶点为起点,继续寻找其出“created”顶点,最后打印路径
g.V().hasLabel('person').optional(out('knows').optional(out('created'))).path()结果中的后面四个顶点因为没有出“knows”顶点,所以在第一步返回了自身后就停止了。
union()示例1:
1
2// 寻找顶点“linary”的出“created”顶点,邻接“knows”顶点,并将结果合并
g.V('linary').union(out('created'), both('knows')).path()示例2:
1
2// 寻找顶点“HugeGraph”的入“created”顶点(创作者),出“implements”和出“supports”顶点,并将结果合并
g.V('3:HugeGraph').union(__.in('created'), out('implements'), out('supports'), out('contains')).path()顶点“HugeGraph”没有“contains”边,所以只打印出了其作者(入“created”),它实现的框架(出“implements”)和支持的特性(出“supports”)。
结果聚集与展开说明
Gremlin在路径游走的时候,可以将某一步的所有结果收集到一个集合里面(我们称之为结果聚集),以备在后续步骤中使用;此外还可在需要的时候将聚集的结果展开。
下面讲解实现上述功能的具体Step:
aggregate(): 聚集路径中指定步骤的所有结果,通过aggregate(label)对任意步骤打上标签,在此之前的步骤的结果均会被收集到此标签所代表的集合中(但并不会影响路径的游走),可配合by及cap一起使用,通过cap(label)来获取该结果集合,此外还可通过select(label)或without(label)等其它方式读取。store(): 类似aggregate(),只是以Lazy的方式来收集。unfold(): 将集合展开平铺,路径将扩张。fold(): 将多个元素折叠为一个集合,路径将收缩。
实例讲解
下面通过实例来深入理解每一个操作。
aggregate():聚集路径中的结果示例1:
1
2
3// 收集第1步的结果到集合'x'中
// 注意:不影响后续结果
g.V('2:HugeGraph').out().aggregate('x')
示例2:
1
2
3
4
5// 收集第1步的结果到集合'x'中
// 并通过cap取出结果
// 与示例1比较,结果的层次更深了
g.V('2:HugeGraph').out()
.aggregate('x').cap('x')
试一试:将
cap('x')换为select('x')看看有什么区别示例3:
1
2
3
4// 通过by()来指定聚集的维度
g.V('2:HugeGraph').out()
.aggregate('x').by('name')
.cap('x')
store():以Lazy的方式来收集结果示例1:
1
2
3
4// 以Lazy方式收集,后续步骤使用limit限制时,
// 路径中取到第2个结果时将会停止,
// 因此集合中有2个元素。
g.V().store('x').by('name').limit(1).cap('x')
请试一试并比较:
g.V().aggregate('x').by('name').limit(1).cap('x')。unfold():以把集合展开、平铺示例1:
1
2
3
4// 将集合‘x’展开(层级变少了)
g.V('2:HugeGraph').out()
.aggregate('x').by('name')
.cap('x').unfold()
fold():将元素折叠为集合示例1:
1
2
3// 将属性折叠起来(层级变深)
g.V('2:HugeGraph').out()
.values('name').fold()
示例2:
1
2
3
4// 统计所有'name'属性的长度
// 其中通过lambuda表达式累加字符串长度
g.V('2:HugeGraph').out().values('name')
.fold(0) {a,b -> a + b.length()}
综合运用
查询一个软件的同类别软件,但不包括自身在内
1
2
3
4
5
6
7// 查询与HugeGraph类似支持Gremlin语言的软件
// 但不包含自身和一步邻居
// 比较:请看看去除where语句的效果
g.V('2:HugeGraph').aggregate('x')
.out().aggregate('x')
.out().in()
.where(without('x'))
查询2度之内的所有邻居的名称
1
2
3
4
5
6// 查询与HugeGraph的两度OUT邻居
// 并收集这些到‘a’集合里面,
// 最终以‘name’属性展示其邻居
g.V('2:HugeGraph').out().aggregate('a')
.out().aggregate('a').cap('a')
.unfold().values('name')
查询由多人合作的软件及其各作者的名称
1
2
3
4
5
6
7// 查询所有由3个以上作者完成的软件
// 并显示它的名称及其作者
g.V().as('software', 'authors')
.where(__.in('created').count().is(gte(3)))
.select('software', 'authors')
.by('name')
.by(__.in('created').values('name').fold())
模式匹配说明
Gremlin中的match()语句为图查询提供了一种基于“模式匹配”的方式,以便用更具描述性的方式进行图查询。match()语句通过多个模式片段traversal fragments来进行模式匹配。这些traversal fragments中会定义一些变量,只有满足所有用变量表示的约束的对象才能够通过,并被放到一个Map<String, Object>中,其中map的key为变量名(label),value为顶点、边、路径或者属性。match()语句的格式为:match(Traversal...)。其中可以有任意多个Traversal,每一个Traversal就是一个“匹配模式”traversal fragment。
match()语句中的“模式”通过MatchAlgorithm来选择匹配顺序,默认的MatchAlgorithm是CountMatchAlgorithm。CountMatchAlgorithm根据过滤强度动态调整“模式匹配”的执行计划(最能够减少规模的“模式”优先匹配),从而优化执行减少资源消耗。因此,当图的规模比较大且用户不知道满足特定模式的数据规模时,使用match()可以自动进行优化,减小操作规模。另外,对于一些图查询场景,相较于单路径遍历,match()语句的“模式匹配”更容易表达需求。
实例说明
match()语句通过模式匹配生成map<String, Object>1
2
3
4
5
6// 对每一个顶点,用以下模式去匹配,满足则生成一个map<String, Object>,不满足则过滤掉
// 模式1:“a”对应当前顶点,且创建了软件“HugeGraph”
// 模式2:“b”对应顶点软件“HugeGraph”
// 模式3:“c”对应创建软件“HugeGraph”的年龄为29的person顶点
g.V().match(__.as('a').out('created').has('name', 'HugeGraph').as('b'),
__.as('b').in('created').has('age', 29).as('c'))match()语句可以与select()语句配合使用,从Map<String, Object>中选取部分结果1
2
3
4
5
6
7
8// 对每一个顶点,用以下模式去匹配,满足则生成一个map<String, Object>,不满足则过滤掉
// 模式1:“a”对应当前顶点,且创建了软件“HugeGraph”
// 模式2:“b”对应顶点软件“HugeGraph”
// 模式3:“c”对应创建软件“HugeGraph”的年龄为29的person顶点
// 并选取map中的“a"和”c",对应的对象以”name“属性的值代替
g.V().match(__.as('a').out('created').has('name', 'HugeGraph').as('b'),
__.as('b').in('created').has('age', 29).as('c'))
.select('a', 'c').by('name')match()语句可以与where()语句配合使用,过滤结果1
2
3
4
5
6
7
8
9
10// 对每一个顶点,用以下模式去匹配,满足则生成一个map<String, Object>,不满足则过滤掉
// 模式1:“a”对应当前顶点,且创建了软件“HugeGraph”
// 模式2:“b”对应顶点软件“HugeGraph”
// 模式3:“c”对应创建软件“HugeGraph”的年龄为29的person顶点
// 模式4:”a“和”c“对应的对象不相等
// 并选取map中的“a"和”c",对应的对象以”name“属性的值代替
g.V().match(__.as('a').out('created').has('name', 'HugeGraph').as('b'),
__.as('b').in('created').has('age', 29).as('c'))
.where('a', neq('c'))
.select('a', 'c').by('name')match()语句中可以使用外部的label1
2
3
4
5
6
7
8
9// 对每一个顶点打标签”a“,"a"经过一条OUT方向的”knows“边到达的顶点打标签”b“
// 对”b“中的每一个顶点用以下模式去匹配,满足则生成一个map<String, Object>,不满足则过滤掉
// 模式1:”b“通过一条OUT方向的”created“边到达顶点”c“
// 模式2:”c“不能通过一条IN方向的”created“边到达”a“
// 选取map中的“a",”b“,”c",对应的对象以”name“属性的值代替
g.V().as('a').out('knows').as('b')
.match(__.as('b').out('created').as('c'),
__.not(__.as('c').in('created').as('a')))
.select('a','b','c').by('name')注意
match(__.as('b').out('created').as('c')中的__.as(b)是读取label标识的对象,as('c')是为新的对象打上label标识。




随机过滤与注入说明
随机过滤说明
Gremlin支持对遍历器(traversal)上的结果进行采样或者做随机过滤。
sample: 接受一个整数值,从前一步的遍历器中采样(随机)出最多指定数目的结果;coin: 字面意思是抛硬币过滤,接受一个浮点值,该浮点值表示硬币出现正面的概率。coin Step 对前一步的遍历器中的每个元素都抛一次硬币,出现正面则可以通过,反面则被拦截。
sampleStep后能接上byStep,能以指定的属性为判断依据进行随机过滤。
注入说明
Gremlin允许在遍历器中注入一些默认值或自定义值,比如在分支 Step 中给 else 路径的元素一个默认值,又或者在遍历器过程中人为地加上一些额外的元素。
constant: 通常用在choose或coalesceStep中做辅助输出,为那些不满足条件的元素提供一个默认值;inject: 能够在流(遍历器)的任何位置注入与当前遍历器同输出类型的对象,当然,也可以作为流的起始 Step 产生数据。
inject只是在查询过程中添加一些额外的元素,并没有把数据真正地插入到图中。
实例讲解
下面通过实例来深入理解每一个操作。
sample()示例1:
1
2// 从所有顶点的出边中随机选择2条
g.V().outE().sample(2)由于
sample是随机采样,所以运行结果每次都可能不一样。另外,sample(n)表示最多采样n个,如果上一步不够n个元素自然结果是会小于n的。示例2:
1
2// 从所以顶点的“name”属性中随机选取3个
g.V().values('name').sample(3)示例3:
1
2// 从所有的“person”中根据“age”随机选择3个
g.V().hasLabel('person').sample(3).by('age')示例4:与
local联合使用做随机漫游(从某个顶点出发,随机选一条边,走到边上的邻接点;再以该点为起点,继续随机选择边,走到邻接点……)1
2
3
4
5// 从顶点“HugeGraph”出发做3次随机漫游
g.V('3:HugeGraph')
.repeat(local(bothE().sample(1).otherV()))
.times(3)
.path()第1次:从“HugeGraph”沿着“Szhoney>2>>S3:HugeGraph”走到“zhoney”
第2次:从“zhoney”沿着“Sjaveme>1>>Szhoney”走到“javeme”
第3次:从“javeme”沿着“Sjaveme>1>>Slinary”走到“linary”coin()示例1:
1
2// 每个顶点按0.5的概率过滤
g.V().coin(0.5)这一次输出了5个顶点,而总共是有12个顶点的,为什么不是输出6个呢?学过概率论的应该都知道,不解释。我又多执行了两次,输出顶点数分别是5和7。
示例2:
1
2// 每个顶点按0.0的概率过滤
g.V().coin(0.0)示例3:
1
2// 每个顶点按1.0的概率过滤
g.V().coin(1.0).count()避免输出太长,加上
count。constant()示例1:
1
2
3
4// 输出所有“person”类顶点的“name”属性,否则输出“inhuman”(非人类)
g.V().choose(hasLabel('person'),
values('name'),
constant('inhuman'))示例2:
1
2
3// 与示例1功能相同,使用“coalesce”Step 实现
g.V().coalesce(hasLabel('person').values('name'),
constant('inhuman'))inject()示例1:
1
2// 给顶点“HugeGraph”的作者添加一个叫“Tom”的人
g.V('3:HugeGraph').in('created').values('name').inject('Tom')示例2:
1
2
3// 在示例1的基础上计算每个元素的长度(“name”属性值的长度)
g.V('3:HugeGraph').in('created').values('name').inject('Tom')
.map {it.get().length()}可以看到,注入的元素“Tom”与原生的元素一样参与了计算。
示例3:
1
2
3// 在示例2的基础上计算走过的路径
g.V('3:HugeGraph').in('created').values('name').inject('Tom')
.map {it.get().length()}.path()这里又能看出注入元素“Tom”与原生的元素的区别,由于“Tom”是在获取“name”属性这一步时才注入的,所以之前的从顶点“HugeGraph”出发,获取其“created”的入顶点这两步“Tom”是没有的。
示例4:
1
2// 使用inject创建出两个元素(顶点的id),并使用该元素作为id获取顶点及其属性“name”
inject('javeme', 'linary', 'zhoney').map {g.V(it.get()).next()}.values('name')1
2// 使用inject创建出一个“person”(顶点label),并使用该元素作为label获取顶点及其属性“name”
inject('person').flatMap {g.V().hasLabel(it.get())}.values('name')
结果存取口袋说明
Gremlin在路径遍历的时候,可以将中间结果存放到一个叫口袋(sack)的结构里面,以备在后续步骤中使用;此外在放入数据到口袋的时候,还可以做一些灵活的操作比如:分裂(split)、合并(merge)等。sack相关step属于Gremlin语言里面的高级操作,在处理较为复杂的任务时可以灵活的实现一些特殊功能。
下面讲解实现上述功能的具体Step:
withSack(): 创建一个口袋,并给定一个初始结构,比如可以是一个返回Map或者随机数的lambda函数,也可以是一个对象或常数;另外还可以提供lambda分裂函数,以指定当traverser分裂时的行为,比如进行clone操作。sack(): 将数据放入口袋,或者从口袋取出数据。当传入lambda合并函数作为参数时,可指定放入口袋的行为如何执行;当不传入参数时表示读取口袋中的内容。
实例讲解
下面通过实例来深入理解每一个操作。
withSack()…sack(): 利用口袋来存取结果示例1:
1
2
3// 创建一个包含常数1的口袋,
// 并且在最终取出口袋中的值
g.withSack(1).V().sack()
示例2:
1
2
3
4// 创建一个包含随机数的口袋,
// 并且在最终取出口袋中的值
g.withSack{new Random().nextFloat()}
.V().sack()
试一试:将
g.withSack{}的大括号换为小括号g.withSack()看看有什么区别。示例3:
1
2
3
4// 通过sum求和的方式把数据放入口袋
g.withSack(0).V()
.repeat(outE().sack(sum).by('weight').inV())
.times(3).sack()
试一试:通过以下gremlin查看路径及其权重:
1
2
3g.withSack(0).V()
.repeat(outE().sack(sum).by('weight').inV())
.times(3).path().by().by('weight')示例4:
1
2
3
4
5
6
7// 通过lambda函数来指定放入口袋的行为
// 注意:提供的初始值为Map类型,而且
// 当traverser分裂时会拷贝Map
g.withSack{[:]}{it.clone()}
.V().out().out().dedup()
.sack{m,v -> m[v.value('name')] = v.value('lang'); m}
.sack()
试一试:去掉分裂函数后看看效果:
1
2
3
4g.withSack{[:]}
.V().out().out().dedup()
.sack{m,v -> m[v.value('name')] = v.value('lang'); m}
.sack()示例5:
1
2
3
4// 平均获取口袋中的值
g.withSack(1.0).V('javeme')
.out('knows').out('created')
.barrier(normSack).sack()
综合运用
获取路径并计算路径权重之和
1
2
3
4
5
6// 获取路径的同时通过sack(sum)计算权重之和
// 最终通过select把权重和路径选取出来
g.withSack(0).V()
.repeat(outE().sack(sum).by('weight').inV().as('p'))
.times(3).sack().as('w')
.select('w', 'p').by().by{p->p.toString()}.limit(3)
获取路径并根据路径权重之和排序
1
2
3
4
5
6// 获取路径的同时通过sack(sum)计算权重之和
// 最终通过order().by(sack())根据总权重排序
g.withSack(0).V()
.repeat(outE().sack(sum).by('weight').inV())
.times(3).order().by(sack(),decr)
.path().limit(3)
遍历栅栏说明
Gremlin在路径遍历的时候,可以将栅栏barrier插入到懒加载的遍历流水线中,以使得barrier之前的步骤都执行完成之后再继续往下执行。barrier主要有2个好处:1、可以强制改变深度优先搜索为广度优先搜索,2、由于通过层的bulking模式可以优化大量重复的数据访问。
下面讲解实现上述功能的具体Step:
barrier(): 在某个位置插入一个栅栏,以强制该位置之前的步骤必须都执行完成才可以继续往后执行,比如g.V().both().barrier().both()只有在第一个both()全部完成之后才会执行第二个both()。
实例讲解
下面通过实例来深入理解每一个操作。
barrier(): 遍历时设置栅栏示例1:
1
2
3
4
5
6
7
8// 将所有顶点打印出来
// 打印完一轮之后再打印一轮
def list=[]
g.V().sideEffect{list.add("first: "+it)}
.barrier()
.sideEffect{list.add("second: "+it)}
.iterate()
list
对比无barrier时的效果:
1
2
3
4
5
6
7// 打印first后打印second,
// 直到一轮所有的顶点都完成
def list=[]
g.V().sideEffect{list.add("first: "+it)}
.sideEffect{list.add("second: "+it)}
.iterate()
list
示例2:
1
2
3
4
5
6
7
8
9
10// 禁用自动barrier策略
g = g.withoutStrategies(LazyBarrierStrategy)
g.V()
.both().barrier()
.both().barrier()
.both().barrier()
.both().barrier()
.both().barrier()
.groupCount()
.order(local).by(values, decr)
对比无barrier时的效果(消耗时间更长):
1
2
3
4
5
6
7
8
9
10
11
12// 通过lambda函数来指定放入口袋的行为
// 注意:提供的初始值为Map类型,而且
// 当traverser分裂时会拷贝Map
g = g.withoutStrategies(LazyBarrierStrategy)
g.V()
.both()
.both()
.both()
.both()
.both()
.groupCount()
.order(local).by(values, decr)
注意:LazyBarrierStrategy是默认策略,该策略会在合适的地方插入barrier,因此这里先禁用了该策略。
barrier()相关Step:事实上除了可显示的插入barrier栅栏外,还有不少Step会隐式插入barrier,包括
order(),sample(),dedup(),aggregate(),fold(),count(),sum(),max(),min(),group(),groupCount(),cap()等。
综合运用
计算特征向量中心性(Eigenvector Centrality)
1
2
3
4
5// 利用隐式barrier计算特征向量中心性
// 包括groupCount、cap,按照降序排序
g.V().repeat(both().groupCount('m'))
.times(5).cap('m')
.order(local).by(values, decr)
局部操作local说明
通过Gremlin进行图遍历通常是当前step处理前一step传递过来的对象流。很多操作是针对传递过来的对象流中的全部对象进行操作,但也有很多时候需要针对对象流中的单个对象而非对象流中的全部对象进行一些操作。这种对单个对象的局部操作,可以使用local()语句实现。
另外,有一些step默认的操作是针对对象流中的全部对象,但也可以通过参数来改变默认操作,允许针对对象流中的单个对象进行操作,包括count(),max(),mean(),min(),sum(),order(),tail(),limit(),range(),sample(),skip()和dedup()等。
实例说明
local的作用说明
是否使用
local()的区别可以参见如下示意图:
实例1:
1
2
3
4
5// 不使用local()
g.V().hasLabel('person').as('person')
.properties('age').order().by(value).limit(2)
.value().as('age')
.select('person','age').by('name').by()实例2:
1
2
3
4
5// 使用local()
g.V().hasLabel('person').as('person')
.local(properties('age').order().by(value).limit(2))
.value().as('age')
.select('person','age').by('name').by()这里应该是“所有人根据年龄排序选出最小的两个”变为“每个人根据年龄排序选出最小的两个”,所以就变成每个人都输出。
为了跟TinkerPop官网的示意图配合,例子中的”age“属性只有一个,使用
order().by().limit(2)有些多余。以参数的形式指定局部操作
实例1
count():1
2
3// 查询软件HugeGraph的属性Map
g.V().hasLabel('software').has('name', 'HugeGraph')
.propertyMap()1
2
3// 查询软件HugeGraph的属性个数
g.V().hasLabel('software').has('name', 'HugeGraph')
.propertyMap().count(local)试一下不加
local结果是什么。实例2
max()、min()、mean()、sum():1
2// 数目最多的顶点类型的顶点数目
g.V().groupCount().by(label).select(values).max(local)min()、mean()、sum()等与max()使用local参数的方法基本一致,不再赘述。试一下不加
local结果是什么。实例3
limit()、tail()、range()、skip():1
2// 所有顶点的属性列表中的第一个属性
g.V().valueMap().limit(local, 1)tail()、range()、skip()与limit()使用local参数的方法基本一致,不再赘述。试一下不加
local结果是什么。实例4
dedup():1
2// 所有顶点一步邻居中所有的software
g.V().both().group().by(label).select('software').dedup(local)试一下不加
local结果是什么。实例5
order():1
2// 所有顶点按类型计数并按数目由多到少排序
g.V().groupCount().by(label).order(local).by(values, decr)实例6
sample():1
2// 所有顶点作为一个集合,从中采样2个
g.V().fold().sample(local,2)









遍历终止说明
Gremlin 中有一类特殊的操作,它能够终止遍历器的“遍历”行为,使其执行并返回结果。在这里要强调的一点:原生的 Gremlin 语句通常都是用遍历器连接起来的,但其实这些连接的过程并不会执行 Gremlin 语句,只有走到了terminalStep 时才会执行。这个模式类似于 Spark 中对RDD的map和action操作。
hasNext: 判断遍历器是否含有元素(结果),返回布尔值;next: 不传参数时获取遍历器的下一个元素,也可以传入一个整数 n,则获取后面 n 个元素;tryNext:hasNext和next的结合版,返回一个Optional对象,如果有结果还需要调用get()方法才能拿到;toList: 将所有的元素放到一个List中返回;toSet: 将所有的元素放到一个Set中返回,会去除重复元素;toBulkSet: 将所有的元素放到一个能排序的List中返回,重复元素也会保留;fill: 传入一个集合对象,将所有的元素放入该集合并返回,其实toList、toSet和toBulkSet就是通过fillStep实现的;iterate: 这个 Step 在终止操作里面有点特殊,它并不完全符合终止操作的定义。它会在内部迭代完整个遍历器但是不返回结果。
那肯定有细心的同学要问了,前面我们介绍了那么多的 Step 很多都没有加terminalStep 啊,为什么也能返回结果呢?其实这是 Tinkerpop 的 Gremlin 解析引擎对遍历器对象调用了一个IteratorUtils.asList()方法,又调用了它内部的fill()方法(注意:不是上面讲到的fill()Step)。
实例讲解
下面通过实例来深入理解每一个操作。
hasNext()示例1:
1
2// 判断顶点“linary”是否包含“created”出顶点
g.V('linary').out('created').hasNext()示例2:
1
2// 判断顶点“linary”是否包含“knows”出顶点
g.V('linary').out('knows').hasNext()next()示例1:
1
2// 获取顶点“javeme”的“knows”出顶点集合的下一个(第1个)
g.V('javeme').out('knows').next()g.V('javeme').out('knows')返回的是一个遍历器(迭代器),每次执行这句话实际上都是获取的迭代器的第一个元素,那如果想获取第二个元素该怎么写呢?很简单,执行两次next()即可,但是这里的前提条件是遍历器中确实存在多个元素。示例2:
1
2
3
4// 获取顶点“javeme”的“knows”出顶点集合的下一个(第2个)
it = g.V('javeme').out('knows')
it.next()
it.next()示例3:
1
2// 获取顶点“javeme”的“knows”出顶点集合的前两个
g.V('javeme').out('knows').next(2)next()与next(n)使用中有一点小小的区别,就是当没有元素或者没有足够多的元素时,执行next()会报错,但是执行next(n)则是返回一个空集合(List)。tryNext()示例1:
1
2// 试图获取顶点“javeme”的“created”出顶点集合中的下一个
g.V('javeme').out('created').tryNext()这里细心的读者会发现结果与前面概述中说的有些不同。概述中说的是返回一个
Optional对象,要获取Optional对象里的值是需要调用它的get()方法的,怎么这里直接就把值给返回了呢?大家先别着急,我们再看一个例子。示例2:
1
2// 试图获取顶点“javeme”的“created”入顶点集合中的下一个
g.V('javeme').in('created').tryNext()这里更加令人费解,没有“created”入顶点时竟然直接报错了,其实这是
HugeGraph的实现中关于Optional的序列化所致。HugeGraph序列化Optional对象时会判断该对象内的值是否存在,如果存在则取出来序列化该值,否则填入一个null。详细代码见HugeGraphSONModule.java中关于OptionalSerializer的实现。
本文的重点在于学习Gremlin语法本身,下面给出上述两个示例的预期结果:1
2Optional[v[3:HugeGraph]]
Optional.emptytoList()示例1:
1
2// 获取所有“person”顶点的“created”出顶点集合,放入List中,允许包含重复结果
g.V().hasLabel('person').out('created').toList()示例2:
1
2// 获取所有“person”顶点的“created”入顶点集合,放入List中,允许包含重复结果
g.V().hasLabel('person').in('created').toList()结果与
next(n)有些类似。toSet()示例1:
1
2// 获取所有“person”顶点的“created”出顶点集合,放入Set中,不允许包含重复结果
g.V().hasLabel('person').out('created').toSet()相比于
toList,toSet去除了重复元素。示例2:
1
2// 获取所有“person”顶点的“created”入顶点集合,放入Set中,不允许包含重复结果
g.V().hasLabel('person').in('created').toSet()toBulkSet()示例1:
1
2// 获取所有“person”顶点的“created”出顶点集合,放入BulkSet中,允许包含重复结果,排序
g.V().hasLabel('person').out('created').toBulkSet()所谓的
BulkSet虽然名字上带有”Set”,但还是更像一个List,对比toList的结果,它实际上是把所有元素排了个序。fill()示例1:
1
2
3
4// 创建一个List,获取所有“person”顶点的“created”出顶点,并放入该List中
results = []
g.V().hasLabel('person').out('created').fill(results)
resultsiterate()示例1:
1
2
3// 迭代所有“person”顶点
it = g.V().hasLabel('person').iterate()
it.hasNext()调用了
iterate()后遍历器内部的元素就已经全部迭代过了,所以再调用hasNext()返回false。
转换操作说明
map: 可以接受一个遍历器 Step 或 Lamda 表达式,将遍历器中的元素映射(转换)成另一个类型的某个对象(一对一),以便进行下一步处理;flatMap: 可以接受一个遍历器 Step 或 Lamda 表达式,将遍历器中的元素映射(转换)成另一个类型的某个对象流或迭代器(一对多)。
实例讲解
下面通过实例来深入理解每一个操作。
map()示例1:
1
2
3// 获取顶点“3:HugeGraph”的入“created”顶点的“name”属性,其实可以理解为顶点对象转化成了属性值对象
g.V('3:HugeGraph').in('created').map(values('name'))
// g.V('3:HugeGraph').in('created').map {it.get().value('name')}自己动手将
g.V('3:HugeGraph').in('created').map {it.get().value('name')}的注视打开试试效果。示例2:
1
2// 先获取顶点“3:HugeGraph”的入“created”顶点,再将每个顶点转化为出边(一条)
g.V('3:HugeGraph').in('created').map(outE())注意:顶点“javeme”其实是有三条边的,但是这里只打印出了一条。因为
mapStep是一对一的转换,要想获取所有的边可以使用flatMap。flatMap()示例1:
1
2// 先获取顶点“3:HugeGraph”的入“created”顶点,再将每个顶点转化为出边(多条)
g.V('3:HugeGraph').in('created').flatMap(outE())注意:这一次就能打印出顶点“javeme”的全部三条边了。
附加操作说明
Gremlin在路径遍历的时候,可以在路径中做一些额外的附加操作,这个附加操作不会改变上一步的结果,会原封不动的传递到下一步去。附加操作看起来就像透明的,但实际上可以将附加操作的处理结果存储到外部变量中去。
下面讲解实现上述功能的具体Step:
sideEffect(): 在某个位置插入一个附加操作,以执行额外的操作,通常可与store、sack等配合使用。另外如下一些Step本质上也是sideEffect:group(string)、groupCount(string)、subgraph(string)、aggregate(string)、inject(string)、profile(string)等。withSideEffect():绑定初始值到变量上,等价于sideEffect的效果。
实例讲解
下面通过实例来深入理解每一个操作。
sideEffect(): 附加操作示例1:
1
2
3
4
5
6// 将所有顶点打印出来
// sideEffect本身不影响结果
def list=[]
g.V().hasLabel('person')
.sideEffect{list.add("vertex:"+it)}
.toList()
示例2:
1
2
3
4
5
6// 将sideEffect处理的结果打印出来
def list=[]
g.V().hasLabel('person')
.sideEffect{list.add("vertex:"+it)}
.toList()
list
注意:Gremlin中的最后一行内容表示输出的结果。
示例3:
1
2
3
4
5// 将sideEffect结果存到变量中
g.V().hasLabel('person')
.sideEffect(outE().count().store("o"))
.sideEffect(inE().count().store("i"))
.cap("o","i")
withSideEffect(): 绑定变量初始值示例1:
1
2
3
4
5// 初始化一个变量以供后续条件判断中使用
// 查找javeme的共同作者,且名称在初始集合中
g.withSideEffect('p',['Linary Li','Zhoney Zhang','Tom'])
.V('javeme').out('created').in('created')
.values('name').where(within('p'))
综合运用
计算度中心性(Degree Centrality)
1
2
3
4
5// 利用sideEffect计算3种度中心性
g.V().group('both').by().by(bothE().count())
.group('out').by().by(outE().count())
.group('in').by().by(inE().count())
.cap('both', 'out', 'in')
统计和分析说明
Gremlin提供了两种语句来帮助用户对执行的查询语句进行统计和分析工作:
explain(),详细描述原始的Gremlin语句在编译期是如何转变为最终要执行的step集合的profile(),统计Gremlin语句执行过程中的每个step消耗的时间和通过的对象等统计信息
TraversalStrategy是“遍历策略”,可以在编译期分析遍历(Traversal)的组成,并在遍历满足TraversalStrategy的条件时对遍历进行修改。这些修改往往都是为了能够更加高效的执行遍历。
遍历策略有5类:
Decoration,应用程序级别的策略Optimization,TinkerPop3级别的策略Provider optimization,图数据库实现级别的策略Finalization,遍历执行前的调整和清理策略Verification,判断遍历是否合法的验证策略
实例说明
实例1 explain():
1 | g.V().hasLabel('person').outE().identity().inV().count().is(gt(5)).explain() |

结果中:
original,表示Gremlin语句等价的最初的step列表intermediate,表示original转化在TraversalStrategy作用下的转化过程strategy,表示作用于上一轮的step列表的TraversalStrategycategory,表示strategy中的TraversalStrategy所属的级别,参见说明部分traversal,表示上一轮的step列表经过strategy中的TraversalStrategy处理之后的新的step列表
final,表示经过所有TraversalStrategy处理后的最终要执行的step列表
实例2 profile():
1 | g.V().out('created').profile() |

返回的结果中,metrics中每一条是一个执行的step,其中:
name是step的名字,例如”HugeGraphStep(vertex,[])”dur是step执行的时间,单位是毫秒annotations中的percentDur是当前step消耗的时间在总的执行时间中的比例counts中的traverserCount是当前step中的traverser的数目counts中的elementCount是当前step中的element的数目
traverserCount和elementCount的区别在于: traverserCount是同一step中相同的对象合并之后的数目,对象相同是指当前的对象是一样的,并不代表对象的path等其他数据也相同;相同的对象合并为bulk,可以减少重复工作,提高效率。elementCount是同一step中所有对象展开bulk之后的数目之和,即未去重的对象数目。因此,traverserCount总是小于等于elementCount。
profile()语句是一个“副作用”(side effect)语句,并非立刻执行。profile()语句还可以指定一个key,形式为profile(String),在执行完要统计的Gremlin语句后,通过key获取统计信息。例如:
1 | t=g.V().out('created').profile('metrics') |


