简介
了解一下Docker和k8s。综合转载于:
- 有哪些通俗易懂的例子可以解释 IaaS、PaaS、SaaS 的区别? - 何足道的回答 - 知乎
- 一文快速了解 Docker 和 Kubernetes
- Docker 教程
- docker&k8s入门详解
- docker restart、start、stop与容器文件系统
- openstack,docker,mesos,k8s什么关系? - 张乾的回答 - 知乎
- Docker不香吗,为啥还要K8s?
- k8s常见命令
- 交互式教程
- K8S系列:集群架构与组件
On-Premises、IaaS、PaaS、SaaS与Serverless

云计算中的三个“高大上”的概念:IaaS、PaaS和SaaS,这几个术语并不好理解。
换个例子理解,一个“吃货”是怎样吃到披萨的呢?
在家自己做
这真是个麻烦事,你的准备很多东西,发面、做面团、进烤箱。简单列一下,需要下图所示的一切:

买好速食披萨回家自己做着吃
你只需要从披萨店里买回成品,回家烘焙就好了,在自己的餐桌上吃。和自己在家做不同,你需要一个pizza供应商。

打电话叫外卖将披萨送到家中
打个电话,pizza就送到家门口。

在披萨店吃披萨
你什么都不需要准备,连餐桌也是pizza店的。

总结一下,吃货可以通过如下途径吃披萨:

好了,现在忘掉pizza!
假设你是一家超牛X的技术公司,根本不需要别人提供服务,你拥有基础设施、应用等等其它一切,你把它们分为三层:基础设施(infrastructure)、平台(platform)和软件(software),如下图:

这其实就是云计算的三个分层,基础设施在最下端,平台在中间,软件在顶端,分别是分别是Infrastructure-as-a-Service(IaaS),Platform-as-a-Service(PaaS),Software-as-a-Service(SaaS),别的一些“软”的层可以在这些层上面添加。
而你的公司什么都有,现在所处的状态叫本地部署(On-Premises),就像在自己家做pizza一样。几年前如果你想在办公室或者公司的网站上运行一些企业应用,你需要去买服务器,或者别的高昂的硬件来控制本地应用,让你的业务运行起来,这就叫本地部署。
假如你家BOSS突然有一天想明白了,只是为了吃上pizza,为什么非要自己做呢?于是,准备考虑一家云服务供应商,这个云服务供应商能提供哪些服务呢?其所能提供的云服务也就是云计算的三个分层:IaaS、PaaS和SaaS,就像pizza店提供三种服务:买成品回家做、外卖和到披萨店吃。
用一张图来表示就是这样的。

现在我们来谈谈具体细节。
IaaS:Infrastructure-as-a-Service(基础设施即服务)
有了IaaS,你可以将硬件外包到别的地方去。IaaS公司会提供场外服务器,存储和网络硬件,你可以租用。节省了维护成本和办公场地,公司可以在任何时候利用这些硬件来运行其应用。
一些大的IaaS公司包括Amazon,Microsoft,VMWare,Rackspace和Red Hat。不过这些公司又都有自己的专长,比如Amazon和微软给你提供的不只是IaaS,他们还会将其计算能力出租给你来host你的网站。
PaaS:Platform-as-a-Service(平台即服务)
第二层就是所谓的PaaS,某些时候也叫做中间件。你公司所有的开发都可以在这一层进行,节省了时间和资源。
PaaS公司在网上提供各种开发和分发应用的解决方案,比如虚拟服务器和操作系统。这节省了你在硬件上的费用,也让分散的工作室之间的合作变得更加容易。网页应用管理,应用设计,应用虚拟主机,存储,安全以及应用开发协作工具等。
一些大的PaaS提供者有Google App Engine,Microsoft Azure,Force.com,Heroku,Engine Yard。最近兴起的公司有AppFog,Mendix和Standing Cloud。
SaaS:Software-as-a-Service(软件即服务)
第三层也就是所谓SaaS。这一层是和你的生活每天接触的一层,大多是通过网页浏览器来接入。任何一个远程服务器上的应用都可以通过网络来运行,就是SaaS了。
你消费的服务完全是从网页如Netflix,MOG,Google Apps,Box.net,Dropbox或者苹果的iCloud那里进入这些分类。尽管这些网页服务是用作商务和娱乐或者两者都有,但这也算是云技术的一部分。
一些用作商务的SaaS应用包括Citrix的Go To Meeting,Cisco的WebEx,Salesforce的CRM,ADP,Workday和SuccessFactors。
Serverless:无服务,不需要服务器。站在用户的角度考虑问题,用户只需要使用云服务器即可,在云服务器所在的基础环境,软件环境都不需要用户关心。
云原生
为了让应用程序(项目,服务软件)都运行在云上的解决方案,这样的方案叫做云原生。
云原生有如下特点:
- 容器化,所有服务都必须部署在容器中
- 微服务,Web 服务架构式服务架构
- CI/CD
- DevOps
Docker
什么是Docker
Docker 是一个开源的应用容器引擎,是一种资源虚拟化技术,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的 Linux 机器上。虚拟化技术演历路径可分为三个时代:
物理机时代,多个应用程序可能跑在一台物理机器上

虚拟机时代,一台物理机器启动多个虚拟机实例,一个虚拟机跑多个应用程序

容器化时代,一台物理机上启动多个容器实例,一个容器跑多个应用程序

在没有 Docker 的时代,我们会使用硬件虚拟化(虚拟机)以提供隔离。这里,虚拟机通过在操作系统上建立了一个中间虚拟软件层 Hypervisor ,并利用物理机器的资源虚拟出多个虚拟硬件环境来共享宿主机的资源,其中的应用运行在虚拟机内核上。但是,虚拟机对硬件的利用率存在瓶颈,因为虚拟机很难根据当前业务量动态调整其占用的硬件资源,加之容器化技术蓬勃发展使其得以流行。
Docker与虚拟机对比:
| 特性 | Docker | 虚拟机 |
|---|---|---|
| 启动速度 | 秒级 | 分钟级 |
| 交付/部署 | 开发、测试、生产环境一致 | - |
| 性能 | 近似物理机 | 性能损耗大 |
| 体量 | 极小(MB) | 较大(GB) |
| 迁移/扩展 | 跨平台、可复制 | - |
另外开发人员在实际的工作中,经常会遇到测试环境或生产环境与本地开发环境不一致的问题,轻则修复保持环境一致,重则可能需要返工。但 Docker 恰好解决了这一问题,它将软件程序和运行的基础环境分开。开发人员编码完成后将程序整合环境通过 DockerFile 打包到一个容器镜像中,从根本上解决了环境不一致的问题。
Docker架构
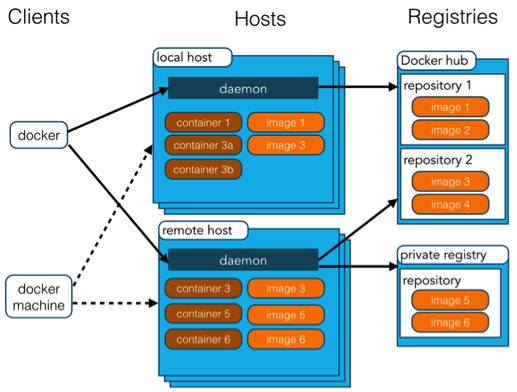
Docker 包括三个基本概念:
- 镜像(Image):Docker 镜像(Image),就相当于是一个 root 文件系统。比如官方镜像 ubuntu:16.04 就包含了完整的一套 Ubuntu16.04 最小系统的 root 文件系统。
- 容器(Container):镜像(Image)和容器(Container)的关系,就像是面向对象程序设计中的类和实例一样,镜像是静态的定义,容器是镜像运行时的实体。容器可以被创建、启动、停止、删除、暂停等。
- 仓库(Repository):仓库可看成一个代码控制中心,用来保存镜像。
Docker 使用客户端-服务器 (C/S) 架构模式,使用远程API来管理和创建Docker容器。
Docker 容器通过 Docker 镜像来创建。
容器与镜像的关系类似于面向对象编程中的对象与类。
| Docker | 面向对象 |
|---|---|
| 容器 | 对象 |
| 镜像 | 类 |
| 概念 | 说明 |
|---|---|
| Docker 镜像(Images) | Docker 镜像是用于创建 Docker 容器的模板,比如 Ubuntu 系统。 |
| Docker 容器(Container) | 容器是独立运行的一个或一组应用,是镜像运行时的实体。 |
| Docker 客户端(Client) | Docker 客户端通过命令行或者其他工具使用 Docker SDK (https://docs.docker.com/develop/sdk/) 与 Docker 的守护进程通信。 |
| Docker 主机(Host) | 一个物理或者虚拟的机器用于执行 Docker 守护进程和容器。 |
| Docker Registry | Docker 仓库用来保存镜像,可以理解为代码控制中的代码仓库。Docker Hub(https://hub.docker.com) 提供了庞大的镜像集合供使用。一个 Docker Registry 中可以包含多个仓库(Repository);每个仓库可以包含多个标签(Tag);每个标签对应一个镜像。通常,一个仓库会包含同一个软件不同版本的镜像,而标签就常用于对应该软件的各个版本。我们可以通过 <仓库名>:<标签> 的格式来指定具体是这个软件哪个版本的镜像。如果不给出标签,将以 latest 作为默认标签。 |
| Docker Machine | Docker Machine是一个简化Docker安装的命令行工具,通过一个简单的命令行即可在相应的平台上安装Docker,比如VirtualBox、 Digital Ocean、Microsoft Azure。 |
Docker安装
安装命令如下:
1 | curl -fsSL https://get.docker.com | bash -s docker --mirror Aliyun |
也可以使用国内 daocloud 一键安装命令:
1 | bashcurl -sSL https://get.daocloud.io/docker | sh |
容器使用
Docker 客户端
可以直接输入 docker 命令来查看到 Docker 客户端的所有命令选项。
1 | docker |

可以通过命令 docker command --help 更深入的了解指定的 Docker 命令使用方法。
例如我们要查看 docker stats指令的具体使用方法:
1 | docker stats --help |
获取镜像
如果本地没有 ubuntu 镜像,我们可以使用 docker pull 命令来载入 ubuntu 镜像:
1 | docker pull ubuntu |
Docker Hello World
Docker 允许你在容器内运行应用程序, 使用 docker run 命令来在容器内运行一个应用程序。
1 | docker run ubuntu /bin/echo "Hello world" |
各个参数解析:
- docker:Docker 的二进制执行文件。
- run:与前面的 docker 组合来运行一个容器。
- ubuntu:指定要运行的镜像,Docker 首先从本地主机上查找镜像是否存在,如果不存在,Docker 就会从镜像仓库 Docker Hub 下载公共镜像。
- /bin/echo “Hello world”:在启动的容器里执行的命令
以上命令完整的意思可以解释为:Docker 以 ubuntu15.10 镜像创建一个新容器,然后在容器里执行 bin/echo “Hello world”,然后输出结果。
启动容器
以下命令使用 ubuntu 镜像启动一个容器,参数为以命令行模式进入该容器:
1 | docker run -it ubuntu /bin/bash |
参数说明:
- -i:交互式操作。
- -t:终端。
- ubuntu:ubuntu 镜像。
- /bin/bash:放在镜像名后的是命令,这里我们希望有个交互式 Shell,因此用的是 /bin/bash。
要退出终端,直接输入 exit:
1 | exit |
后台运行
在大部分的场景下,我们希望 docker 的服务是在后台运行的,我们可以过 -d 指定容器的运行模式。
1 | docker run -itd --name ubuntu-test ubuntu /bin/bash |
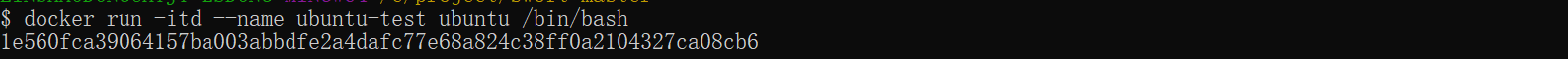

注:加了 -d 参数默认不会进入容器,想要进入容器需要使用指令 docker exec。
在输出中,我们没有看到期望的 “hello world”,而是一串长字符
1 | 2b1b7a428627c51ab8810d541d759f072b4fc75487eed05812646b8534a2fe63 |
这个长字符串叫做容器 ID,对每个容器来说都是唯一的,我们可以通过容器 ID 来查看对应的容器发生了什么。
首先,我们需要确认容器有在运行,可以通过 docker ps 来查看:
1 | docker ps |
输出详情介绍:
CONTAINER ID: 容器 ID。
IMAGE: 使用的镜像。
COMMAND: 启动容器时运行的命令。
CREATED: 容器的创建时间。
STATUS: 容器状态。
状态有7种:
- created(已创建)
- restarting(重启中)
- running 或 Up(运行中)
- removing(迁移中)
- paused(暂停)
- exited(停止)
- dead(死亡)
PORTS: 容器的端口信息和使用的连接类型(tcp\udp)。
NAMES: 自动分配的容器名称。
在宿主主机内使用 docker logs 命令,查看容器内的标准输出:
1 | docker logs |

停止一个容器
停止容器的命令如下:
1 | docker stop <容器 ID> |
停止的容器可以通过 docker restart 重启:
1 | docker start <容器 ID> |
docker start ...包含容器文件系统挂载的操作docker stop ...包含容器文件系统卸载的操作docker restart ...不包含容器文件系统的卸载与挂载操作,本质上restart不涉及文件系统的操作,因此restart命令并不是stop与start两个命令的顺序叠加,谨慎使用。
进入容器
在使用 -d 参数时,容器启动后会进入后台。此时想要进入容器,可以通过以下指令进入:
docker attach1
$ docker attach 1e560fca3906
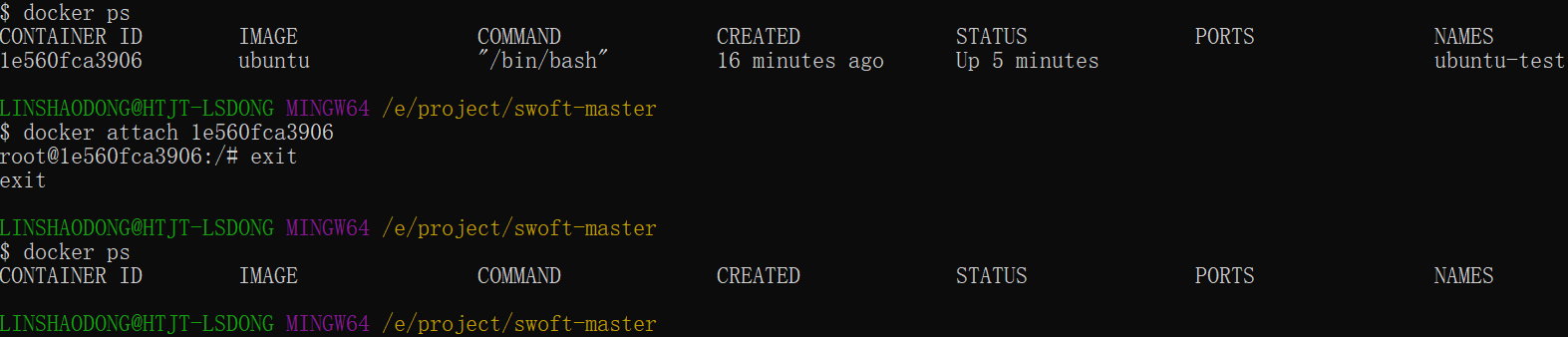
注意: 如果从这个容器退出,会导致容器的停止。
docker exec:推荐使用 docker exec 命令,因为这样退出容器终端,不会导致容器的停止。1
docker exec -it 243c32535da7 /bin/bash

注意: 如果从这个容器退出,容器不会停止,这就是为什么推荐大家使用 docker exec 的原因。
导出容器
如果要导出本地某个容器,可以使用 docker export 命令。
1 | docker export 1e560fca3906 > ubuntu.tar |
导出容器 1e560fca3906 快照到本地文件 ubuntu.tar。这样将导出容器快照到本地文件。
导入容器
可以使用 docker import 从容器快照文件中再导入为镜像,以下实例将快照文件 ubuntu.tar 导入到镜像 test/ubuntu:v1:
1 | cat docker/ubuntu.tar | docker import - test/ubuntu:v1 |
此外,也可以通过指定 URL 或者某个目录来导入,例如:
1 | docker import http://example.com/exampleimage.tgz example/imagerepo |
删除容器
删除容器使用 docker rm 命令:
1 | docker rm -f 1e560fca3906 |
下面的命令可以清理掉所有处于终止状态的容器。
1 | docker container prune |
运行一个 web 应用
尝试使用 docker 构建一个 web 应用程序。
我们将在docker容器中运行一个 Python Flask 应用来运行一个web应用。
1 | runoob@runoob:~# docker pull training/webapp # 载入镜像 |
参数说明:
- -d:让容器在后台运行。
- -P:将容器内部使用的网络端口随机映射到我们使用的主机上。
查看web应用容器
使用 docker ps 来查看我们正在运行的容器:
1 | docker ps |
这里多了端口信息。
1 | PORTS |
Docker 开放了 5000 端口(默认 Python Flask 端口)映射到主机端口 32769 上。
这时我们可以通过浏览器访问WEB应用

我们也可以通过 -p 参数来设置不一样的端口:
1 | docker run -d -p 5000:5000 training/webapp python app.py |
查看正在运行的容器
1 | runoob@runoob:~# docker ps |
容器内部的 5000 端口映射到我们本地主机的 5000 端口上。
网络端口的快捷方式
通过 docker ps 命令可以查看到容器的端口映射,Docker 还提供了另一个快捷方式 docker port,使用 docker port 可以查看指定 (ID 或者名字)容器的某个确定端口映射到宿主机的端口号。
上面我们创建的 web 应用容器 ID 为 bf08b7f2cd89 名字为 wizardly_chandrasekhar。
我可以使用 docker port bf08b7f2cd89 或 docker port wizardly_chandrasekhar 来查看容器端口的映射情况。
1 | docker port bf08b7f2cd89 |
查看web应用程序日志
docker logs [ID或者名字]:可以查看容器内部的标准输出。
1 | docker logs -f bf08b7f2cd89 |
- -f:让
docker logs像使用tail -f一样来输出容器内部的标准输出。
从上面,我们可以看到应用程序使用的是 5000 端口并且能够查看到应用程序的访问日志。
查看web应用程序容器的进程
我们还可以使用 docker top 来查看容器内部运行的进程。
1 | docker top wizardly_chandrasekhar |
检查web应用程序
使用 docker inspect 来查看 Docker 的底层信息。它会返回一个 JSON 文件记录着 Docker 容器的配置和状态信息。
1 | docker inspect wizardly_chandrasekhar |
移除web应用容器
使用 docker rm 命令来删除不需要的容器
1 | docker rm wizardly_chandrasekhar |
删除容器时,容器必须是停止状态,否则会报如下错误:
1 | docker rm wizardly_chandrasekhar |
镜像使用
当运行容器时,使用的镜像如果在本地中不存在,docker 就会自动从 docker 镜像仓库中下载,默认是从 Docker Hub 公共镜像源下载。
列出镜像列表
我们可以使用 docker images 来列出本地主机上的镜像。
1 | docker images |
各个选项说明:
- REPOSITORY:表示镜像的仓库源
- TAG:镜像的标签
- IMAGE ID:镜像ID
- CREATED:镜像创建时间
- SIZE:镜像大小
同一仓库源可以有多个 TAG,代表这个仓库源的不同个版本,如 ubuntu 仓库源里,有 15.10、14.04 等多个不同的版本,我们使用 REPOSITORY:TAG 来定义不同的镜像。
如果你不指定一个镜像的版本标签,例如你只使用 ubuntu,docker 将默认使用 ubuntu:latest 镜像。
获取新的镜像
当我们在本地主机上使用一个不存在的镜像时 Docker 就会自动下载这个镜像。如果想预先下载这个镜像,可以使用 docker pull 命令来下载它。
1 | docker pull ubuntu:13.10 |
下载完成后,我们可以直接使用这个镜像来运行容器。
查找镜像
可以从 Docker Hub 网站来搜索镜像,Docker Hub 网址为: https://hub.docker.com/。
我们也可以使用 docker search 命令来搜索镜像。比如我们需要一个 httpd 的镜像来作为我们的 web 服务。我们可以通过 docker search 命令搜索 httpd 来寻找适合我们的镜像。
1 | docker search httpd |

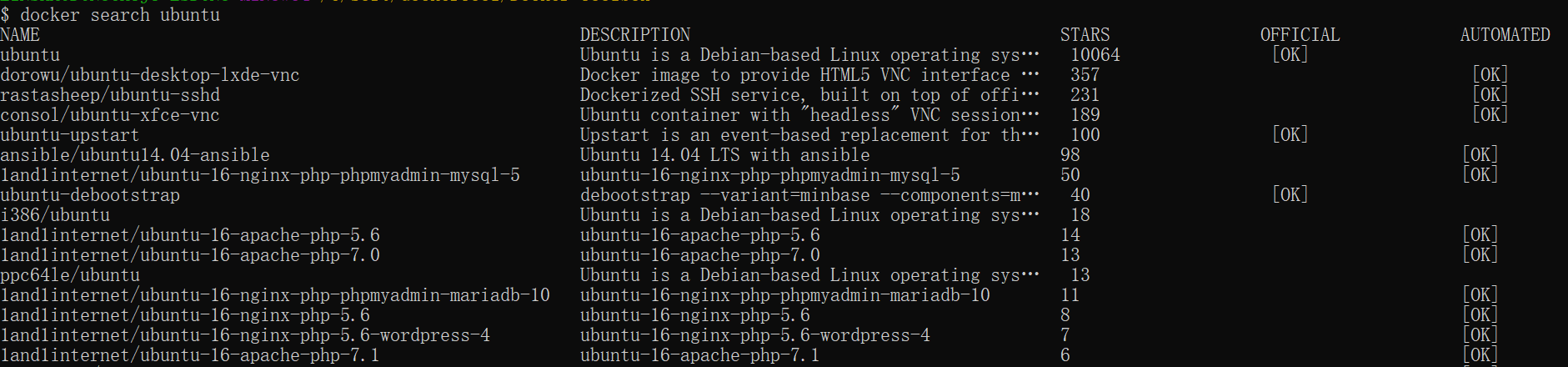
NAME:镜像仓库源的名称
DESCRIPTION:镜像的描述
OFFICIAL:是否 docker 官方发布
stars:类似 Github 里面的 star,表示点赞、喜欢的意思。
AUTOMATED:自动构建。
删除镜像
镜像删除使用 docker rmi 命令,比如我们删除 hello-world 镜像:
1 | $ docker rmi hello-world |
创建镜像
当我们从 docker 镜像仓库中下载的镜像不能满足我们的需求时,我们可以通过以下两种方式对镜像进行更改。
- 1、从已经创建的容器中更新镜像,并且提交这个镜像
- 2、使用 Dockerfile 指令来创建一个新的镜像
更新镜像
更新镜像之前,需要使用镜像来创建一个容器。
1 | docker run -t -i ubuntu:15.10 /bin/bash |
在运行的容器内使用 apt-get update 命令进行更新。
在完成操作之后,输入 exit 命令来退出这个容器。
此时 ID 为 e218edb10161 的容器,是按我们的需求更改的容器。可以通过命令 docker commit 来提交容器副本。
1 | docker commit -m="has update" -a="runoob" e218edb10161 runoob/ubuntu:v2 |
各个参数说明:
- -m:提交的描述信息
- -a:指定镜像作者
- e218edb10161:容器 ID
- runoob/ubuntu:v2:指定要创建的目标镜像名
可以使用 docker images 命令来查看我们的新镜像 runoob/ubuntu:v2:
1 | docker images |
使用我们的新镜像 runoob/ubuntu 来启动一个容器
1 | docker run -t -i runoob/ubuntu:v2 /bin/bash |
构建镜像
使用命令 docker build , 从零开始来创建一个新的镜像。为此,我们需要创建一个 Dockerfile 文件,其中包含一组指令来告诉 Docker 如何构建我们的镜像。
1 | cat Dockerfile |
每一个指令都会在镜像上创建一个新的层,每一个指令的前缀都必须是大写的。
第一条FROM,指定使用哪个镜像源
RUN 指令告诉docker 在镜像内执行命令,安装了什么。
然后,我们使用 Dockerfile 文件,通过 docker build 命令来构建一个镜像。
1 | docker build -t runoob/centos:6.7 . |
参数说明:
- -t :指定要创建的目标镜像名
- . :Dockerfile 文件所在目录,可以指定Dockerfile 的绝对路径
使用 docker images 查看创建的镜像已经在列表中存在,镜像ID为860c279d2fec
1 | docker images |
设置镜像标签
可以使用 docker tag 命令,为镜像添加一个新的标签。
1 | docker tag 860c279d2fec runoob/centos:dev |
docker tag 镜像ID,这里是 860c279d2fec,用户名称、镜像源名(repository name)和新的标签名(tag)。
使用 docker images 命令可以看到,ID为860c279d2fec的镜像多一个标签。
1 | docker images |
容器连接
前面实现了通过网络端口来访问运行在 docker 容器内的服务。
容器中可以运行一些网络应用,要让外部也可以访问这些应用,可以通过 -P 或 -p 参数来指定端口映射。
下面我们来实现通过端口连接到一个 docker 容器。
网络端口映射
我们创建了一个 python 应用的容器。
1 | docker run -d -P training/webapp python app.py |
另外,我们可以指定容器绑定的网络地址,比如绑定 127.0.0.1。
我们使用 -P 绑定端口号,使用 docker ps 可以看到容器端口 5000 绑定主机端口 32768。
1 | docker ps |
我们也可以使用 -p 标识来指定容器端口绑定到主机端口。
两种方式的区别是:
- -P:是容器内部端口随机映射到主机的高端口。
- -p :是容器内部端口绑定到指定的主机端口。
1 | docker run -d -p 5000:5000 training/webapp python app.py |
另外,我们可以指定容器绑定的网络地址,比如绑定 127.0.0.1。
1 | docker run -d -p 127.0.0.1:5001:5000 training/webapp python app.py |
这样我们就可以通过访问 127.0.0.1:5001 来访问容器的 5000 端口。
上面的例子中,默认都是绑定 tcp 端口,如果要绑定 UDP 端口,可以在端口后面加上 /udp。
1 | docker run -d -p 127.0.0.1:5000:5000/udp training/webapp python app.py |
docker port 命令可以让我们快捷地查看端口的绑定情况。
1 | docker port adoring_stonebraker 5000 |
容器互联
端口映射并不是唯一把 docker 连接到另一个容器的方法。
docker 有一个连接系统允许将多个容器连接在一起,共享连接信息。
docker 连接会创建一个父子关系,其中父容器可以看到子容器的信息。
容器命名
当我们创建一个容器的时候,docker 会自动对它进行命名。另外,我们也可以使用 —name 标识来命名容器,例如:
1 | docker run -d -P --name runoob training/webapp python app.py |
我们可以使用 docker ps 命令来查看容器名称。
1 | docker ps -l |
新建网络
下面先创建一个新的 Docker 网络。
1 | $ docker network create -d bridge test-net |

参数说明:
- -d:参数指定 Docker 网络类型,有 bridge、overlay。
其中 overlay 网络类型用于 Swarm mode,在本小节中你可以忽略它。
连接容器
运行一个容器并连接到新建的 test-net 网络:
1 | $ docker run -itd --name test1 --network test-net ubuntu /bin/bash |
打开新的终端,再运行一个容器并加入到 test-net 网络:
1 | $ docker run -itd --name test2 --network test-net ubuntu /bin/bash |

下面通过 ping 来证明 test1 容器和 test2 容器建立了互联关系。
如果 test1、test2 容器内中无 ping 命令,则在容器内执行以下命令安装 ping。即学即用:可以在一个容器里安装好,提交容器到镜像,在以新的镜像重新运行以上俩个容器。
1 | apt-get update |
在 test1 容器输入以下命令:

同理在 test2 容器也会成功连接到:

这样,test1 容器和 test2 容器建立了互联关系。
如果你有多个容器之间需要互相连接,推荐使用 Docker Compose,后面会介绍。
配置 DNS
我们可以在宿主机的 /etc/docker/daemon.json 文件中增加以下内容来设置全部容器的 DNS:
1 | { |
设置后,启动容器的 DNS 会自动配置为 114.114.114.114 和 8.8.8.8。
配置完,需要重启 docker 才能生效。
查看容器的 DNS 是否生效可以使用以下命令,它会输出容器的 DNS 信息:
1 | docker run -it --rm ubuntu cat etc/resolv.conf |

手动指定容器的配置
如果只想在指定的容器设置 DNS,则可以使用以下命令:
1 | $ docker run -it --rm -h host_ubuntu --dns=114.114.114.114 --dns-search=test.com ubuntu |
参数说明:
—rm:容器退出时自动清理容器内部的文件系统。
-h HOSTNAME 或者 —hostname=HOSTNAME: 设定容器的主机名,它会被写到容器内的 /etc/hostname 和 /etc/hosts。
—dns=IP_ADDRESS: 添加 DNS 服务器到容器的
/etc/resolv.conf中,让容器用这个服务器来解析所有不在 /etc/hosts 中的主机名。—dns-search=DOMAIN: 设定容器的搜索域,当设定搜索域为
.example.com时,在搜索一个名为host的主机时,DNS 不仅搜索 host,还会搜索host.example.com。

如果在容器启动时没有指定 —dns 和 —dns-search,Docker 会默认用宿主主机上的 /etc/resolv.conf 来配置容器的 DNS。
仓库管理
仓库(Repository)是集中存放镜像的地方。以下介绍一下 Docker Hub。当然不止 docker hub,只是远程的服务商不一样,操作都是一样的。
Docker Hub
目前 Docker 官方维护了一个公共仓库 Docker Hub。大部分需求都可以通过在 Docker Hub 中直接下载镜像来实现。
注册
在 https://hub.docker.com 免费注册一个 Docker 账号。
登录
登录需要输入用户名和密码,登录成功后,我们就可以从 docker hub 上拉取自己账号下的全部镜像。
1 | docker login |
退出
退出 docker hub 可以使用以下命令:
1 | docker logout |
拉取镜像
你可以通过 docker search 命令来查找官方仓库中的镜像,并利用 docker pull 命令来将它下载到本地。
以 ubuntu 为关键词进行搜索:
1 | docker search ubuntu |
使用 docker pull 将官方 ubuntu 镜像下载到本地:
1 | docker pull ubuntu |
推送镜像
用户登录后,可以通过 docker push 命令将自己的镜像推送到 Docker Hub。
以下命令中的 username请替换为你的 Docker 账号用户名。
1 | $ docker tag ubuntu:18.04 username/ubuntu:18.04 |
Dockerfile
什么是Dockerfile?
Dockerfile 是一个用来构建镜像的文本文件,文本内容包含了一条条构建镜像所需的指令和说明。
使用Dockerfile定制镜像
这里仅讲解如何运行 Dockerfile 文件来定制一个镜像,具体 Dockerfile 文件内指令详解,将在下一节中介绍,这里你只要知道构建的流程即可。
下面以定制一个 nginx 镜像(构建好的镜像内会有一个
/usr/share/nginx/html/index.html文件)在一个空目录下,新建一个名为 Dockerfile 文件,并在文件内添加以下内容:
1
2FROM nginx
RUN echo '这是一个本地构建的nginx镜像' > /usr/share/nginx/html/index.html
FROM和RUN指令的作用FROM:定制的镜像都是基于 FROM 的镜像,这里的 nginx 就是定制需要的基础镜像。后续的操作都是基于 nginx。
RUN:用于执行后面跟着的命令行命令。有以下俩种格式:
shell 格式:
1
2RUN <命令行命令>
# <命令行命令> 等同于,在终端操作的 shell 命令。exec 格式:
1
2
3RUN ["可执行文件", "参数1", "参数2"]
# 例如:
# RUN ["./test.php", "dev", "offline"] 等价于 RUN ./test.php dev offline
注意:Dockerfile 的指令每执行一次都会在 docker 上新建一层。所以过多无意义的层,会造成镜像膨胀过大。例如:
1
2
3
4FROM centos
RUN yum install wget
RUN wget -O redis.tar.gz "http://download.redis.io/releases/redis-5.0.3.tar.gz"
RUN tar -xvf redis.tar.gz以上执行会创建 3 层镜像。可简化为以下格式:
1
2
3
4FROM centos
RUN yum install wget \
&& wget -O redis.tar.gz "http://download.redis.io/releases/redis-5.0.3.tar.gz" \
&& tar -xvf redis.tar.gz如上,以
&&符号连接命令,这样执行后,只会创建 1 层镜像。
开始构建镜像
在 Dockerfile 文件的存放目录下,执行构建动作。
以下示例,通过目录下的 Dockerfile 构建一个 nginx:v3(镜像名称:镜像标签)。
注:最后的 . 代表本次执行的上下文路径,下一节会介绍。
1 | docker build -t nginx:v3 . |

以上显示,说明已经构建成功。
上下文路径
上一节中,有提到指令最后一个 . 是上下文路径,那么什么是上下文路径呢?
1 | docker build -t nginx:v3 . |
上下文路径,是指 docker 在构建镜像,有时候想要使用到本机的文件(比如复制),docker build 命令得知这个路径后,会将路径下的所有内容打包。
解析:由于 docker 的运行模式是 C/S。我们本机是 C,docker 引擎是 S。实际的构建过程是在 docker 引擎下完成的,所以这个时候无法用到我们本机的文件。这就需要把我们本机的指定目录下的文件一起打包提供给 docker 引擎使用。
如果未说明最后一个参数,那么默认上下文路径就是 Dockerfile 所在的位置。
注意:上下文路径下不要放无用的文件,因为会一起打包发送给 docker 引擎,如果文件过多会造成过程缓慢。
指令详解
COPY
复制指令,从上下文目录中复制文件或者目录到容器里指定路径。
格式:
1 | COPY [--chown=<user>:<group>] <源路径1>... <目标路径> |
[—chown=
: ]:可选参数,用户改变复制到容器内文件的拥有者和属组。 <源路径>:源文件或者源目录,这里可以是通配符表达式,其通配符规则要满足 Go 的 filepath.Match 规则。例如:
1
2COPY hom* /mydir/
COPY hom?.txt /mydir/<目标路径>:容器内的指定路径,该路径不用事先建好,路径不存在的话,会自动创建。
ADD
ADD 指令和 COPY 的使用格式一致(同样需求下,官方推荐使用 COPY)。功能也类似,不同之处如下:
- ADD 的优点:在执行 <源文件> 为 tar 压缩文件的话,压缩格式为 gzip, bzip2 以及 xz 的情况下,会自动复制并解压到 <目标路径>。
- ADD 的缺点:在不解压的前提下,无法复制 tar 压缩文件。会令镜像构建缓存失效,从而可能会令镜像构建变得比较缓慢。具体是否使用,可以根据是否需要自动解压来决定。
CMD
类似于 RUN 指令,用于运行程序,但二者运行的时间点不同:
- CMD 在
docker run时运行。 - RUN 是在
docker build。
作用:为启动的容器指定默认要运行的程序,程序运行结束,容器也就结束。CMD 指令指定的程序可被 docker run 命令行参数中指定要运行的程序所覆盖。
注意:如果 Dockerfile 中如果存在多个 CMD 指令,仅最后一个生效。
格式:
1 | CMD <shell 命令> |
推荐使用第二种格式,执行过程比较明确。第一种格式实际上在运行的过程中也会自动转换成第二种格式运行,并且默认可执行文件是 sh。
ENTRYPOINT
类似于 CMD 指令,但其不会被 docker run 的命令行参数指定的指令所覆盖,而且这些命令行参数会被当作参数送给 ENTRYPOINT 指令指定的程序。
但是,如果运行 docker run 时使用了 --entrypoint 选项,将覆盖 CMD 指令指定的程序。
优点:在执行 docker run 的时候可以指定 ENTRYPOINT 运行所需的参数。
注意:如果 Dockerfile 中如果存在多个 ENTRYPOINT 指令,仅最后一个生效。
格式:
1 | ENTRYPOINT ["<executeable>","<param1>","<param2>",...] |
可以搭配 CMD 命令使用:一般是变参才会使用 CMD ,这里的 CMD 等于是在给 ENTRYPOINT 传参,以下示例会提到。
示例:
假设已通过 Dockerfile 构建了 nginx:test 镜像:
1 | FROM nginx |
不传参运行
1
docker run nginx:test
容器内会默认运行以下命令,启动主进程。
1
nginx -c /etc/nginx/nginx.conf
传参运行
1
docker run nginx:test -c /etc/nginx/new.conf
容器内会默认运行以下命令,启动主进程(
/etc/nginx/new.conf:假设容器内已有此文件)1
nginx -c /etc/nginx/new.conf
ENV
设置环境变量,定义了环境变量,那么在后续的指令中,就可以使用这个环境变量。
格式:
1 | ENV <key> <value> |
以下示例设置 ·NODE_VERSION = 7.2.0· , 在后续的指令中可以通过 ·$NODE_VERSION· 引用:
1 | ENV NODE_VERSION 7.2.0 |
ARG
构建参数,与 ENV 作用一至。不过作用域不一样。ARG 设置的环境变量仅对 Dockerfile 内有效,也就是说只有 docker build 的过程中有效,构建好的镜像内不存在此环境变量。
构建命令 docker build 中可以用 --build-arg <参数名>=<值> 来覆盖。
格式:
1 | ARG <参数名>[=<默认值>] |
VOLUME
定义匿名数据卷。在启动容器时忘记挂载数据卷,会自动挂载到匿名卷。
作用:
- 避免重要的数据,因容器重启而丢失,这是非常致命的。
- 避免容器不断变大。
格式:
1 | VOLUME ["<路径1>", "<路径2>"...] |
在启动容器 docker run 的时候,我们可以通过 -v 参数修改挂载点。
EXPOSE
仅仅只是声明端口。
作用:
- 帮助镜像使用者理解这个镜像服务的守护端口,以方便配置映射。
- 在运行时使用随机端口映射时,也就是
docker run -P时,会自动随机映射 EXPOSE 的端口。
格式:
1 | EXPOSE <端口1> [<端口2>...] |
WORKDIR
指定工作目录。用 WORKDIR 指定的工作目录,会在构建镜像的每一层中都存在。(WORKDIR 指定的工作目录,必须是提前创建好的)。
docker build 构建镜像过程中的,每一个 RUN 命令都是新建的一层。只有通过 WORKDIR 创建的目录才会一直存在。
格式:
1 | WORKDIR <工作目录路径> |
USER
用于指定执行后续命令的用户和用户组,这边只是切换后续命令执行的用户(用户和用户组必须提前已经存在)。
格式:
1 | USER <用户名>[:<用户组>] |
HEALTHCHECK
用于指定某个程序或者指令来监控 docker 容器服务的运行状态。
格式:
1 | HEALTHCHECK [选项] CMD <命令>:设置检查容器健康状况的命令 |
ONBUILD
用于延迟构建命令的执行。简单的说,就是 Dockerfile 里用 ONBUILD 指定的命令,在本次构建镜像的过程中不会执行(假设镜像为 test-build)。当有新的 Dockerfile 使用了之前构建的镜像 FROM test-build ,这时执行新镜像的 Dockerfile 构建时候,会执行 test-build 的 Dockerfile 里的 ONBUILD 指定的命令。
格式:
1 | ONBUILD <其它指令> |
LABEL
LABEL 指令用来给镜像添加一些元数据(metadata),以键值对的形式,语法格式如下:
1 | LABEL <key>=<value> <key>=<value> <key>=<value> ... |
比如我们可以添加镜像的作者:
1 | LABEL org.opencontainers.image.authors="runoob" |
实现原理
Docker 是如何进行资源虚拟化的,并且如何实现资源隔离的,其核心技术原理主要有(内容部分参考自 Docker 核心技术与实现原理):
1、Namespace
在日常使用 Linux 或者 macOS 时,我们并没有运行多个完全分离的服务器的需要,但是如果我们在服务器上启动了多个服务,这些服务其实会相互影响的,每一个服务都能看到其他服务的进程,也可以访问宿主机器上的任意文件,这是很多时候我们都不愿意看到的,我们更希望运行在同一台机器上的不同服务能做到完全隔离,就像运行在多台不同的机器上一样。
命名空间(Namespaces)是 Linux 为我们提供的用于分离进程树、网络接口、挂载点以及进程间通信等资源的方法。Linux 的命名空间机制提供了以下七种不同的命名空间,通过这七个选项我们能在创建新的进程时设置新进程应该在哪些资源上与宿主机器进行隔离。
- CLONE_NEWCGROUP
- CLONE_NEWIPC
- CLONE_NEWNET
- CLONE_NEWNS
- CLONE_NEWPID
- CLONE_NEWUSER
- CLONE_NEWUTS

在 Linux 系统中,有两个特殊的进程,一个是 pid 为 1 的 /sbin/init 进程,另一个是 pid 为 2 的 kthreadd 进程,这两个进程都是被 Linux 中的上帝进程 idle 创建出来的,其中前者负责执行内核的一部分初始化工作和系统配置,也会创建一些类似 getty 的注册进程,而后者负责管理和调度其他的内核进程。
当在宿主机运行 Docker,通过docker run或docker start创建新容器进程时,会传入 CLONE_NEWPID 实现进程上的隔离。

接着,在方法createSpec的setNamespaces中,完成除进程命名空间之外与用户、网络、IPC 以及 UTS 相关的命名空间的设置。
1 | func (daemon *Daemon) createSpec(c *container.Container) (*specs.Spec, error) { |
网络
当 Docker 容器完成命名空间的设置,其网络也变成了独立的命名空间,与宿主机的网络互联便产生了限制,这就导致外部很难访问到容器内的应用程序服务。Docker 提供了 4 种网络模式,通过--net指定。
- host
- container
- none
- bridge
由于后续介绍 Kubernetes 利用了 Docker 的 bridge 网络模式,所以仅介绍该模式。Linux 中为了方便各网络命名空间的网络互相访问,设置了 Veth Pair 和网桥来实现,Docker 也是基于此方式实现了网络通信。
下图中 eth0 与 veth9953b75 是一个 Veth Pair,eth0 与 veth3e84d4f 为另一个 Veth Pair。Veth Pair 在容器内一侧会被设置为 eth0 模拟网卡,另一侧连接 Docker0 网桥,这样就实现了不同容器间网络的互通。加之 Docker0 为每个容器配置的 iptables 规则,又实现了与宿主机外部网络的互通。

解决了进程和网络隔离的问题,但是 Docker 容器中的进程仍然能够访问或者修改宿主机器上的其他目录,这是我们不希望看到的。
在新的进程中创建隔离的挂载点命名空间需要在 clone 函数中传入 CLONE_NEWNS,这样子进程就能得到父进程挂载点的拷贝,如果不传入这个参数子进程对文件系统的读写都会同步回父进程以及整个主机的文件系统。当一个容器需要启动时,它一定需要提供一个根文件系统(rootfs),容器需要使用这个文件系统来创建一个新的进程,所有二进制的执行都必须在这个根文件系统中,并建立一些符号链接来保证 IO 不会出现问题。

另外,通过 Linux 的chroot命令能够改变当前的系统根目录结构,通过改变当前系统的根目录,我们能够限制用户的权利,在新的根目录下并不能够访问旧系统根目录的结构个文件,也就建立了一个与原系统完全隔离的目录结构。
2、Control Groups(CGroups)
Control Groups(CGroups)提供了宿主机上物理资源的隔离,例如 CPU、内存、磁盘 I/O 和网络带宽。主要由这几个组件构成:
- 控制组(CGroup):一个 CGroup 包含一组进程,并可以在这个 CGroup 上增加 Linux Subsystem 的各种参数配置,将一组进程和一组 Subsystem 关联起来。
- Subsystem 子系统:是一组资源控制模块,比如 CPU 子系统可以控制 CPU 时间分配,内存子系统可以限制 CGroup 内存使用量。可以通过
lssubsys -a命令查看当前内核支持哪些 Subsystem。 - Hierarchy 层级树:主要功能是把 CGroup 串成一个树型结构,使 CGruop 可以做到继承,每个 Hierarchy 通过绑定对应的 Subsystem 进行资源调度。
- Task:在 CGroups 中,task 就是系统的一个进程。一个任务可以加入某个 CGroup,也可以从某个 CGroup 迁移到另外一个 CGroup。
在 Linux 的 Docker 安装目录下有一个 docker 目录,当启动一个容器时,就会创建一个与容器标识符相同的 CGroup,举例来说当前的主机就会有以下层级关系:

每一个 CGroup 下面都有一个 tasks 文件,其中存储着属于当前控制组的所有进程的 pid,作为负责 cpu 的子系统,cpu.cfs_quota_us 文件中的内容能够对 CPU 的使用作出限制,如果当前文件的内容为 50000,那么当前控制组中的全部进程的 CPU 占用率不能超过 50%。
当我们使用 Docker 关闭掉正在运行的容器时,Docker 的子控制组对应的文件夹也会被 Docker 进程移除。
3、UnionFS
联合文件系统(Union File System),它可以把多个目录内容联合挂载到同一个目录下,而目录的物理位置是分开的。UnionFS 可以把只读和可读写文件系统合并在一起,具有写时复制功能,允许只读文件系统的修改可以保存到可写文件系统当中。Docker 之前使用的为 AUFS(Advanced Union FS),现为 Overlay2。
Docker 中的每一个镜像都是由一系列只读的层组成的,Dockerfile 中的每一个命令都会在已有的只读层上创建一个新的层:
1 | FROM ubuntu:15.04 |
容器中的每一层都只对当前容器进行了非常小的修改,上述的 Dockerfile 文件会构建一个拥有四层 layer 的镜像:
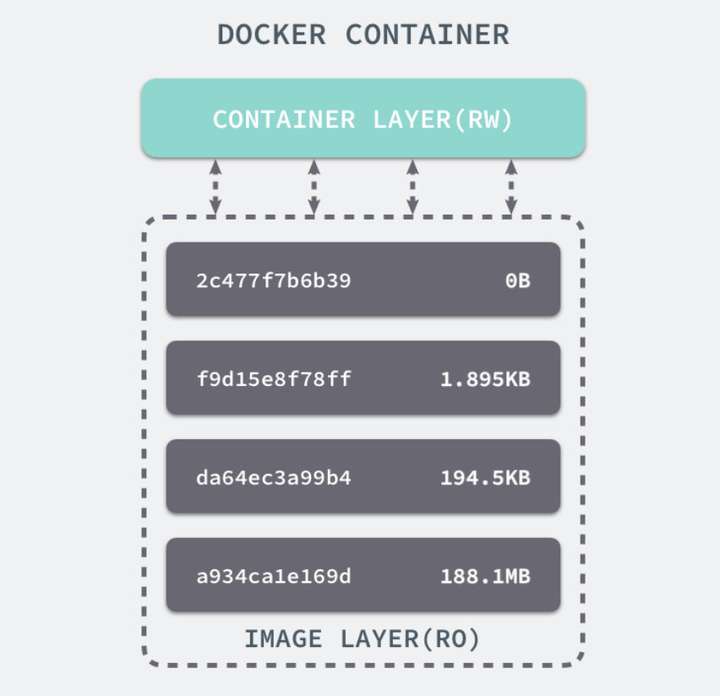
当镜像被命令创建时就会在镜像的最上层添加一个可写的层,也就是容器层,所有对于运行时容器的修改其实都是对这个容器读写层的修改。容器和镜像的区别就在于,所有的镜像都是只读的,而每一个容器其实等于镜像加上一个可读写的层,也就是同一个镜像可以对应多个容器。

Docker Compose
Compose简介
Compose 是用于定义和运行多容器 Docker 应用程序的工具。通过 Compose,您可以使用 YML 文件来配置应用程序需要的所有服务。然后,使用一个命令,就可以从 YML 文件配置中创建并启动所有服务。
Compose 使用的三个步骤:
- 使用 Dockerfile 定义应用程序的环境。
- 使用 docker-compose.yml 定义构成应用程序的服务,这样它们可以在隔离环境中一起运行。
- 最后,执行 docker-compose up 命令来启动并运行整个应用程序。
docker-compose.yml 的配置案例如下(配置参数参考下文):
1 | # yaml 配置实例 |
Compose 安装
Linux 上我们可以从 Github 上下载它的二进制包来使用,最新发行的版本地址:https://github.com/docker/compose/releases。
运行以下命令以下载 Docker Compose 的当前稳定版本:
1 | sudo curl -L "https://github.com/docker/compose/releases/download/1.24.1/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose |
要安装其他版本的 Compose,请替换 1.24.1。
将可执行权限应用于二进制文件:
1 | $ sudo chmod +x /usr/local/bin/docker-compose |
创建软链:
1 | $ sudo ln -s /usr/local/bin/docker-compose /usr/bin/docker-compose |
测试是否安装成功:
1 | $ docker-compose --version |
注意: 对于 alpine,需要以下依赖包: py-pip,python-dev,libffi-dev,openssl-dev,gcc,libc-dev,和 make。
使用
1、准备
创建一个测试目录:
1 | $ mkdir composetest |
在测试目录中创建一个名为 app.py 的文件,并复制粘贴以下内容:
1 | import time |
在此示例中,redis 是应用程序网络上的 redis 容器的主机名,该主机使用的端口为 6379。
在 composetest 目录中创建另一个名为 requirements.txt 的文件,内容如下:
1 | flask |
2、创建 Dockerfile 文件
在 composetest 目录中,创建一个名为 Dockerfile 的文件,内容如下:
1 | FROM python:3.7-alpine |
Dockerfile 内容解释:
FROM python:3.7-alpine:从 Python 3.7 映像开始构建镜像。
WORKDIR /code:将工作目录设置为 /code。
```
ENV FLASK_APP app.py
ENV FLASK_RUN_HOST 0.0.0.01
2
3
4
5
6
7
8
设置 flask 命令使用的环境变量。
- RUN apk add --no-cache gcc musl-dev linux-headers:安装 gcc,以便诸如 MarkupSafe 和 SQLAlchemy 之类的 Python 包可以编译加速。
- ```
COPY requirements.txt requirements.txt
RUN pip install -r requirements.txt复制 requirements.txt 并安装 Python 依赖项。
COPY . .:将 . 项目中的当前目录复制到 . 镜像中的工作目录。
CMD [“flask”, “run”]:容器提供默认的执行命令为:flask run。
3、创建 docker-compose.yml
在测试目录中创建一个名为 docker-compose.yml 的文件,然后粘贴以下内容:
1 | # yaml 配置 |
该 Compose 文件定义了两个服务:web 和 redis。
- web:该 web 服务使用从 Dockerfile 当前目录中构建的镜像。然后,它将容器和主机绑定到暴露的端口 5000。此示例服务使用 Flask Web 服务器的默认端口 5000 。
- redis:该 redis 服务使用 Docker Hub 的公共 Redis 映像。
4、使用 Compose 命令构建和运行您的应用
在测试目录中,执行以下命令来启动应用程序:
1 | docker-compose up |
如果你想在后台执行该服务可以加上 -d 参数:
1 | docker-compose up -d |
yml 配置指令参考
version
指定本 yml 依从的 compose 哪个版本制定的。
build
指定为构建镜像上下文路径:
例如 webapp 服务,指定为从上下文路径 ./dir/Dockerfile 所构建的镜像:
1 | version: "3.7" |
或者,作为具有在上下文指定的路径的对象,以及可选的 Dockerfile 和 args:
1 | version: "3.7" |
- context:上下文路径。
- dockerfile:指定构建镜像的 Dockerfile 文件名。
- args:添加构建参数,这是只能在构建过程中访问的环境变量。
- labels:设置构建镜像的标签。
- target:多层构建,可以指定构建哪一层。
cap_add,cap_drop
添加或删除容器拥有的宿主机的内核功能。
1 | cap_add: |
cgroup_parent
为容器指定父 cgroup 组,意味着将继承该组的资源限制。
1 | cgroup_parent: m-executor-abcd |
command
覆盖容器启动的默认命令。
1 | command: ["bundle", "exec", "thin", "-p", "3000"] |
container_name
指定自定义容器名称,而不是生成的默认名称。
1 | container_name: my-web-container |
depends_on
设置依赖关系。
- docker-compose up :以依赖性顺序启动服务。在以下示例中,先启动 db 和 redis ,才会启动 web。
- docker-compose up SERVICE :自动包含 SERVICE 的依赖项。在以下示例中,docker-compose up web 还将创建并启动 db 和 redis。
- docker-compose stop :按依赖关系顺序停止服务。在以下示例中,web 在 db 和 redis 之前停止。
1 | version: "3.7" |
注意:web 服务不会等待 redis和db 完全启动 之后才启动。
deploy
指定与服务的部署和运行有关的配置。只在 swarm 模式下才会有用。
1 | version: "3.7" |
可以选参数:
endpoint_mode:访问集群服务的方式。
1
2
3
4endpoint_mode: vip
# Docker 集群服务一个对外的虚拟 ip。所有的请求都会通过这个虚拟 ip 到达集群服务内部的机器。
endpoint_mode: dnsrr
# DNS 轮询(DNSRR)。所有的请求会自动轮询获取到集群 ip 列表中的一个 ip 地址。labels:在服务上设置标签。可以用容器上的 labels(跟 deploy 同级的配置) 覆盖 deploy 下的 labels。
mode:指定服务提供的模式。
replicated:复制服务,复制指定服务到集群的机器上。
global:全局服务,服务将部署至集群的每个节点。
图解:下图中黄色的方块是 replicated 模式的运行情况,灰色方块是 global 模式的运行情况。
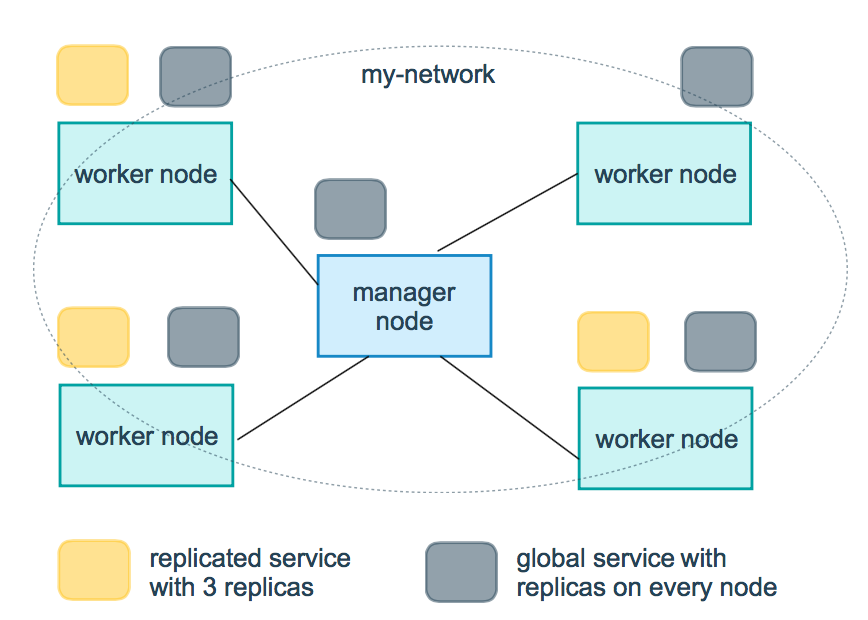
replicas:mode 为 replicated 时,需要使用此参数配置具体运行的节点数量。
resources:配置服务器资源使用的限制,例如上例子,配置 redis 集群运行需要的 cpu 的百分比 和 内存的占用。避免占用资源过高出现异常。
restart_policy:配置如何在退出容器时重新启动容器。
- condition:可选 none,on-failure 或者 any(默认值:any)。
- delay:设置多久之后重启(默认值:0)。
- max_attempts:尝试重新启动容器的次数,超出次数,则不再尝试(默认值:一直重试)。
- window:设置容器重启超时时间(默认值:0)。
rollback_config:配置在更新失败的情况下应如何回滚服务。
- parallelism:一次要回滚的容器数。如果设置为0,则所有容器将同时回滚。
- delay:每个容器组回滚之间等待的时间(默认为0s)。
- failure_action:如果回滚失败,该怎么办。其中一个 continue 或者 pause(默认pause)。
- monitor:每个容器更新后,持续观察是否失败了的时间 (ns|us|ms|s|m|h)(默认为0s)。
- max_failure_ratio:在回滚期间可以容忍的故障率(默认为0)。
- order:回滚期间的操作顺序。其中一个 stop-first(串行回滚),或者 start-first(并行回滚)(默认 stop-first )。
update_config:配置应如何更新服务,对于配置滚动更新很有用。
- parallelism:一次更新的容器数。
- delay:在更新一组容器之间等待的时间。
- failure_action:如果更新失败,该怎么办。其中一个 continue,rollback 或者pause (默认:pause)。
- monitor:每个容器更新后,持续观察是否失败了的时间 (ns|us|ms|s|m|h)(默认为0s)。
- max_failure_ratio:在更新过程中可以容忍的故障率。
- order:回滚期间的操作顺序。其中一个 stop-first(串行回滚),或者 start-first(并行回滚)(默认stop-first)。
注:仅支持 V3.4 及更高版本。
devices
指定设备映射列表。
1 | devices: |
dns
自定义 DNS 服务器,可以是单个值或列表的多个值。
1 | dns: 8.8.8.8 |
dns_search
自定义 DNS 搜索域。可以是单个值或列表。
1 | dns_search: example.com |
entrypoint
覆盖容器默认的 entrypoint。
1 | entrypoint: /code/entrypoint.sh |
也可以是以下格式:
1 | entrypoint: |
env_file
从文件添加环境变量。可以是单个值或列表的多个值。
1 | env_file: .env |
也可以是列表格式:
1 | env_file: |
environment
添加环境变量。您可以使用数组或字典、任何布尔值,布尔值需要用引号引起来,以确保 YML 解析器不会将其转换为 True 或 False。
1 | environment: |
expose
暴露端口,但不映射到宿主机,只被连接的服务访问。
仅可以指定内部端口为参数:
1 | expose: |
extra_hosts
添加主机名映射。类似 docker client —add-host。
1 | extra_hosts: |
以上会在此服务的内部容器中 /etc/hosts 创建一个具有 ip 地址和主机名的映射关系:
1 | 162.242.195.82 somehost |
healthcheck
用于检测 docker 服务是否健康运行。
1 | healthcheck: |
image
指定容器运行的镜像。以下格式都可以:
1 | image: redis |
logging
服务的日志记录配置。
driver:指定服务容器的日志记录驱动程序,默认值为json-file。有以下三个选项
1 | driver: "json-file" |
仅在 json-file 驱动程序下,可以使用以下参数,限制日志得数量和大小。
1 | logging: |
当达到文件限制上限,会自动删除旧的文件。
syslog 驱动程序下,可以使用 syslog-address 指定日志接收地址。
1 | logging: |
network_mode
设置网络模式。
1 | network_mode: "bridge" |
配置容器连接的网络,引用顶级 networks 下的条目 。
1 | services: |
- aliases :同一网络上的其他容器可以使用服务名称或此别名来连接到对应容器的服务。
restart
- no:是默认的重启策略,在任何情况下都不会重启容器。
- always:容器总是重新启动。
- on-failure:在容器非正常退出时(退出状态非0),才会重启容器。
- unless-stopped:在容器退出时总是重启容器,但是不考虑在Docker守护进程启动时就已经停止了的容器
1 | restart: "no" |
注:swarm 集群模式,请改用 restart_policy。
secrets
存储敏感数据,例如密码:
1 | version: "3.1" |
security_opt
修改容器默认的 schema 标签。
1 | security-opt: |
stop_grace_period
指定在容器无法处理 SIGTERM (或者任何 stop_signal 的信号),等待多久后发送 SIGKILL 信号关闭容器。
1 | stop_grace_period: 1s # 等待 1 秒 |
默认的等待时间是 10 秒。
stop_signal
设置停止容器的替代信号。默认情况下使用 SIGTERM 。
以下示例,使用 SIGUSR1 替代信号 SIGTERM 来停止容器。
1 | stop_signal: SIGUSR1 |
sysctls
设置容器中的内核参数,可以使用数组或字典格式。
1 | sysctls: |
tmpfs
在容器内安装一个临时文件系统。可以是单个值或列表的多个值。
1 | tmpfs: /run |
ulimits
覆盖容器默认的 ulimit。
1 | ulimits: |
volumes
将主机的数据卷或着文件挂载到容器里。
1 | version: "3.7" |
Docker Machine
简介
Docker Machine 是一种可以让您在虚拟主机上安装 Docker 的工具,并可以使用 docker-machine 命令来管理主机。
Docker Machine 也可以集中管理所有的 docker 主机,比如快速的给 100 台服务器安装上 docker。
Docker Machine 管理的虚拟主机可以是机上的,也可以是云供应商,如阿里云,腾讯云,AWS,或 DigitalOcean。
使用 docker-machine 命令,您可以启动,检查,停止和重新启动托管主机,也可以升级 Docker 客户端和守护程序,以及配置 Docker 客户端与您的主机进行通信。
安装
安装 Docker Machine 之前你需要先安装 Docker。
Docker Machine 可以在多种平台上安装使用,包括 Linux 、MacOS 以及 windows。
安装命令
1 | base=https://github.com/docker/machine/releases/download/v0.16.0 && |
查看是否安装成功:
1 | docker-machine version |
使用
本章通过 virtualbox 来介绍 docker-machine 的使用方法。其他云服务商操作与此基本一致。具体可以参考每家服务商的指导文档。
1、列出可用的机器
可以看到目前只有这里默认的 default 虚拟机。
1 | docker-machine ls |

2、创建机器
创建一台名为 test 的机器。
1 | $ docker-machine create --driver virtualbox test |
- —driver:指定用来创建机器的驱动类型,这里是 virtualbox。
3、查看机器的 ip
1 | docker-machine ip test |

4、停止机器
1 | docker-machine stop test |
5、启动机器
1 | docker-machine start test |
6、进入机器
1 | docker-machine ssh test |
参数说明
docker-machine active:查看当前激活状态的 Docker 主机。
1
2
3
4
5
6
7
8
9
10
11$ docker-machine ls
NAME ACTIVE DRIVER STATE URL
dev - virtualbox Running tcp://192.168.99.103:2376
staging * digitalocean Running tcp://203.0.113.81:2376
$ echo $DOCKER_HOST
tcp://203.0.113.81:2376
$ docker-machine active
stagingconfig:查看当前激活状态 Docker 主机的连接信息。
create:创建 Docker 主机
env:显示连接到某个主机需要的环境变量
inspect: 以 json 格式输出指定Docker的详细信息
ip: 获取指定 Docker 主机的地址
kill: 直接杀死指定的 Docker 主机
ls: 列出所有的管理主机
provision: 重新配置指定主机
regenerate-certs: 为某个主机重新生成 TLS 信息
restart: 重启指定的主机
rm: 删除某台 Docker 主机,对应的虚拟机也会被删除
ssh: 通过 SSH 连接到主机上,执行命令
scp: 在 Docker 主机之间以及 Docker 主机和本地主机之间通过 scp 远程复制数据
mount: 使用 SSHFS 从计算机装载或卸载目录
start: 启动一个指定的 Docker 主机,如果对象是个虚拟机,该虚拟机将被启动
status: 获取指定 Docker 主机的状态(包括:Running、Paused、Saved、Stopped、Stopping、Starting、Error)等
stop: 停止一个指定的 Docker 主机
upgrade: 将一个指定主机的 Docker 版本更新为最新
url: 获取指定 Docker 主机的监听 URL
version: 显示 Docker Machine 的版本或者主机 Docker 版本
help: 显示帮助信息
Swarm 集群管理
简介
Docker Swarm 是 Docker 的集群管理工具。它将 Docker 主机池转变为单个虚拟 Docker 主机。 Docker Swarm 提供了标准的 Docker API,所有任何已经与 Docker 守护程序通信的工具都可以使用 Swarm 轻松地扩展到多个主机。
支持的工具包括但不限于以下各项:
- Dokku
- Docker Compose
- Docker Machine
- Jenkins
原理
如下图所示,swarm 集群由管理节点(manager)和工作节点(work node)构成。
- swarm mananger:负责整个集群的管理工作包括集群配置、服务管理等所有跟集群有关的工作。
- work node:即图中的 available node,主要负责运行相应的服务来执行任务(task)。

使用
以下示例,均以 Docker Machine 和 virtualbox 进行介绍,确保你的主机已安装 virtualbox。
1、创建 swarm 集群管理节点(manager)
创建 docker 机器:
1 | docker-machine create -d virtualbox swarm-manager |
初始化 swarm 集群,进行初始化的这台机器,就是集群的管理节点。
1 | docker-machine ssh swarm-manager |

以上输出,证明已经初始化成功。需要把以下这行复制出来,在增加工作节点时会用到:
1 | docker swarm join --token SWMTKN-1-4oogo9qziq768dma0uh3j0z0m5twlm10iynvz7ixza96k6jh9p-ajkb6w7qd06y1e33yrgko64sk 192.168.99.107:2377 |
2、创建 swarm 集群工作节点(worker)
这里直接创建好俩台机器,swarm-worker1 和 swarm-worker2 。

分别进入两个机器里,指定添加至上一步中创建的集群,这里会用到上一步复制的内容。

以上数据输出说明已经添加成功。
上图中,由于上一步复制的内容比较长,会被自动截断,实际上在图运行的命令如下:
1 | docker swarm join --token SWMTKN-1-4oogo9qziq768dma0uh3j0z0m5twlm10iynvz7ixza96k6jh9p-ajkb6w7qd06y1e33yrgko64sk 192.168.99.107:2377 |
3、查看集群信息
进入管理节点,执行:docker info 可以查看当前集群的信息。
1 | $ docker info |

通过画红圈的地方,可以知道当前运行的集群中,有三个节点,其中有一个是管理节点。
4、部署服务到集群中
注意:跟集群管理有关的任何操作,都是在管理节点上操作的。
以下例子,在一个工作节点上创建一个名为 helloworld 的服务,这里是随机指派给一个工作节点:
1 | docker service create --replicas 1 --name helloworld alpine ping docker.com |

5、查看服务部署情况
查看 helloworld 服务运行在哪个节点上,可以看到目前是在 swarm-worker1 节点:
1 | docker service ps helloworld |

查看 helloworld 部署的具体信息:
1 | docker service inspect --pretty helloworld |

6、扩展集群服务
将上述的 helloworld 服务扩展到俩个节点。
1 | docker service scale helloworld=2 |

可以看到已经从一个节点,扩展到两个节点。

7、删除服务
1 | docker service rm helloworld |

查看是否已删除:

8、滚动升级服务
以下实例,我们将介绍 redis 版本如何滚动升级至更高版本。
创建一个 3.0.6 版本的 redis。
1 | docker service create --replicas 1 --name redis --update-delay 10s redis:3.0.6 |

滚动升级 redis 。
1 | docker@swarm-manager:~$ docker service update --image redis:3.0.7 redis |

看图可以知道 redis 的版本已经从 3.0.6 升级到了 3.0.7,说明服务已经升级成功。
9、停止某个节点接收新的任务
查看所有的节点:
1 | docker node ls |

可以看到目前所有的节点都是 Active, 可以接收新的任务分配。
停止节点 swarm-worker1:
1 | docker node update --availability drain swarm-worker1 |

注意:swarm-worker1 状态变为 Drain。不会影响到集群的服务,只是 swarm-worker1 节点不再接收新的任务,集群的负载能力有所下降。
可以通过以下命令重新激活节点:
1 | docker node update --availability active swarm-worker1 |

OpenStack、Docker、k8s与Mesos
可以简单理解为OpenStack是对虚拟机的管理编排,k8s是对Docker容器的管理编排。
- OpenStack:公认的云计算IaaS平台,其管理的核心目标对象是机器(虚拟机或物理机),当然也可以管理存储和网络,但那些也大都是围绕着机器所提供的配套资源。近年来容器技术火了之后,OpenStack也开始通过各种方式增加对容器的支持,但目前OpenStack还不被视为管理容器的主流平台。
- Docker:这里假定指的是Docker engine(也叫做Docker daemon,或最新的名字:Moby),它是一种容器运行时(container runtime)的实现,而且是最主流的实现,几乎就是容器业界的事实标准。Docker是用来创建和管理容器的,它和容器的关系就好比Hypervisor(比如:KVM)和虚拟机之间的关系。当然,Docker公司对Docker engine本身的定位和期望不仅仅在于在单机上管理容器,所以近年来一直在向Docker engine中加入各种各样的高级功能,比如:组建多节点的Docker集群、容器编排、服务发现,等等。
- Kubernetes(K8s):搭建容器集群和进行容器编排的主流开源项目(亲爹是Google),适合搭建PaaS平台。容器是Kubernetes管理的核心目标对象,它和容器的关系就好比OpenStack和虚拟机之间的关系,而它和Docker的关系就好比OpenStack和Hypervisor之间的关系。一般来说,Kubernetes是和Docker配合使用的,Kubernetes调用每个节点上的Docker去创建和管理容器,所以,可以认为Kubernetes是大脑,而Docker是四肢。
- Mesos:Mesos是一个通用资源管理平台,它所管理的核心目标对象既不是虚拟机/物理机,也不是容器,而是各种各样的计算资源(CPU、memory、disk、port、GPU等等)。Mesos会收集各个节点上的计算资源然后提供给运行在它之上的应用框架(比如:Spark、Marathon、甚至是Kubernetes)来使用,应用框架可以将收到的计算资源以自己喜欢的任何方式创建成计算任务来完成特定工作(比如:创建一个大数据任务计算个π什么的)。由于容器技术近年来的火热,Mesos也对容器进行非常深层次的支持,它内部完整地实现了一个容器运行时(类似于Docker),所以,上层的应用框架可以方便地把自己的计算任务以容器的方式在Mesos管理的计算集群中运行起来。使用Mesos的门槛相对较高(需要应用框架编写代码调用Mesos的API和其集成),但一旦用起来之后灵活性和可扩展性更高,因为Mesos并不限制应用框架如何使用计算资源(可以以容器的方式使用,也可以是其它方式,比如:传统的进程),主动权完全在应用框架自己手中。作为对比,Kubernetes只能管理容器,所有任务都必须以容器的方式来运行。为了解决门槛较高的问题(当然也是为了赚钱),Mesosphere(Mesos这个开源项目背后的商业公司)推出了DC/OS,其核心就是Mesos加一个内置的应用框架Marathon(可以用做容器编排),能够达到开箱即用的效果,安装好之后立刻就可以创建和管理容器和非容器类的任务了。
Kubernetes(k8s)
1、为什么要 Kubernetes
尽管 Docker 为容器化的应用程序提供了开放标准,但随着容器越来越多出现了一系列新问题:
- 单机不足以支持更多的容器
- 分布式环境下容器如何通信?
- 如何协调和调度这些容器?
- 如何在升级应用程序时不会中断服务?
- 如何监视应用程序的运行状况?
- 如何批量重新启动容器里的程序?
- …
Kubernetes 应运而生。
2、什么是 Kubernetes
Kubernetes 是一个全新的基于容器技术的分布式架构方案,这个方案虽然还很新,但却是 Google 十几年来大规模应用容器技术的经验积累和升华的重要成果,确切的说是 Google 一个久负盛名的内部使用的大规模集群管理系统——Borg 的开源版本,其目的是实现资源管理的自动化以及跨数据中心的资源利用率最大化。
Kubernetes 具有完备的集群管理能力,包括多层次的安全防护和准入机制、多租户应用支撑能力、透明的服务注册和服务发现机制、内建的智能负载均衡器、强大的故障发现和自我修复能力、服务滚动升级和在线扩容能力、可扩展的资源自动调度机制,以及多力度的资源配额管理能力。同时,Kubernetes 提供了完善的管理工具,这些工具涵盖了包括开发、部署测试、运维监控在内的各个环节,不仅是一个全新的基于容器技术的分布式架构解决方案,还是一个一站式的完备分布式系统开发和支撑平台。
3、Kubernetes 术语
1. Pod
Pod 是 Kubernetes 最重要的基本概念,可由多个容器(一般而言一个容器一个进程,不建议一个容器多个进程)组成,它是系统中资源分配和调度的最小单位。下图是 Pod 的组成示意图,其中有一个特殊的 Pause 容器:

Pause 容器的状态标识了一个 Pod 的状态,也就是代表了 Pod 的生命周期。另外 Pod 中其余容器共享 Pause 容器的命名空间,使得 Pod 内的容器能够共享 Pause 容器的 IP,以及实现文件共享。以下是一个 Pod 的定义:
1 | apiVersion: v1 # 分组和版本 |
EndPoint : PodIP + containerPort,代表一个服务进程的对外通信地址。一个 Pod 也存在具有多个 Endpoint 的情况,比如当我们把 Tomcat 定义为一个 Pod 时,可以对外暴露管理端口与服务端口这两个 Endpoint。
2. Label
Label 是 Kubernetes 系统中的一个核心概念,一个 Label 表示一个 key=value 的键值对,key、value 的值由用户指定。Label 可以被附加到各种资源对象上,例如 Node、Pod、Service、RC 等,一个资源对象可以定义任意数量的 Label,同一个 Label 也可以被添加到任意数量的资源对象上。Label 通常在资源对象定义时确定,也可以在对象创建后动态添加或者删除。给一个资源对象定义了 Label 后,我们随后可以通过 Label Selector 查询和筛选拥有这个 Label 的资源对象,来实现多维度的资源分组管理功能,以便灵活、方便地进行资源分配、调 度、配置、部署等管理工作。
Label Selector 当前有两种表达式,基于等式的和基于集合的:
name=redis-slave:匹配所有具有标签name=redis-slave的资源对象。env!=production:匹配所有不具有标签env=production的资源对象。name in(redis-master, redis-slave):name=redis-master或者name=redis-slave的资源对象。name not in(php-frontend):匹配所有不具有标签name=php-frontend的资源对象。
以 myWeb Pod 为例:
1 | apiVersion: v1 # 分组和版本 |
当一个 Service 的 selector 中指明了这个 Pod 时,该 Pod 就会与该 Service 绑定
1 | apiVersion: v1 |
3. Replication Controller
Replication Controller,简称 RC,简单来说,它其实定义了一个期望的场景,即声明某种 Pod 的副本数量在任意时刻都符合某个预期值。
RC 的定义包括如下几个部分:
- Pod 期待的副本数量
- 用于筛选目标 Pod 的 Label Selector
- 当 Pod 的副本数小于预期数量时,用于创建新 Pod 的模版(template)
1 | apiVersion: v1 |
当提交这个 RC 在集群中后,Controller Manager 会定期巡检,确保目标 Pod 实例的数量等于 RC 的预期值,过多的数量会被停掉,少了则会创建补充。通过kubectl scale可以动态指定 RC 的预期副本数量。
目前,RC 已升级为新概念——Replica Set(RS),两者当前唯一区别是,RS 支持了基于集合的 Label Selector,而 RC 只支持基于等式的 Label Selector。RS 很少单独使用,更多是被 Deployment 这个更高层的资源对象所使用,所以可以视作 RS+Deployment 将逐渐取代 RC 的作用。
4. Deployment
Deployment 和 RC 相似度超过 90%,无论是作用、目的、Yaml 定义还是具体命令行操作,所以可以将其看作是 RC 的升级。而 Deployment 相对于 RC 的一个最大区别是我们可以随时知道当前 Pod“部署”的进度。实际上由于一个 Pod 的创建、调度、绑定节点及在目 标 Node 上启动对应的容器这一完整过程需要一定的时间,所以我们期待系统启动 N 个 Pod 副本的目标状态,实际上是一个连续变化的“部署过程”导致的最终状态。
1 | apiVersion: v1 |
5. Horizontal Pod Autoscaler
除了手动执行kubectl scale完成 Pod 的扩缩容之外,还可以通过 Horizontal Pod Autoscaling(HPA)横向自动扩容来进行自动扩缩容。其原理是追踪分析目标 Pod 的负载变化情况,来确定是否需要针对性地调整目标 Pod 数量。当前,HPA 有两种方式作为 Pod 负载的度量指标:
- CPUUtilizationPercentage,目标 Pod 所有副本自身的 CPU 利用率的平均值。
- 应用程序自定义的度量指标,比如服务在每秒内的相应请求数(TPS 或 QPS)。
1 | apiVersion: autoscaling/v1 |
根据上边定义,当 Pod 副本的 CPUUtilizationPercentage 超过 90%时就会出发自动扩容行为,数量约束为 1 ~ 3 个。
6. StatefulSet
在 Kubernetes 系统中,Pod 的管理对象 RC、Deployment、DaemonSet 和 Job 都面向无状态的服务。
通常情况下,Deployment 被用来部署无状态服务,那么对于有状态服务的部署,使用 StatefulSet 进行有状态服务的部署。
什么是有状态服务?
- 有实时的数据需要存储。
- 有状态服务集群中,把某一个服务抽离出去,一段时间后再加入机器网络,如果集群网络无法使用。
什么是无状态服务?
- 没有实时的数据需要存储。
- 无状态服务集群中,把某一个服务抽离出去,一段时间后再加入机器网络,对集群服务没有任何影响。
但现实中有很多服务是有状态的,特别是 一些复杂的中间件集群,例如 MySQL 集群、MongoDB 集群、Akka 集 群、ZooKeeper 集群等,这些应用集群有 4 个共同点。
- 每个节点都有固定的身份 ID,通过这个 ID,集群中的成员可 以相互发现并通信。
- 集群的规模是比较固定的,集群规模不能随意变动。
- 集群中的每个节点都是有状态的,通常会持久化数据到永久存储中。
- 如果磁盘损坏,则集群里的某个节点无法正常运行,集群功能受损。
因此,StatefulSet 具有以下特点:
- StatefulSet 里的每个 Pod 都有稳定、唯一的网络标识,可以用来发现集群内的其他成员。假设 StatefulSet 的名称为 kafka,那么第 1 个 Pod 叫 kafka-0,第 2 个叫 kafka-1,以此类推。
- StatefulSet 控制的 Pod 副本的启停顺序是受控的,操作第 n 个 Pod 时,前 n-1 个 Pod 已经是运行且准备好的状态。
- StatefulSet 里的 Pod 采用稳定的持久化存储卷,通过 PV 或 PVC 来 实现,删除 Pod 时默认不会删除与 StatefulSet 相关的存储卷(为了保证数据的安全)。
- StatefulSet 除了要与 PV 卷捆绑使用以存储 Pod 的状态数据,还要与 Headless Service 配合使用。
Headless Service : Headless Service 与普通 Service 的关键区别在于,它没有 Cluster IP,如果解析 Headless Service 的 DNS 域名,则返回的是该 Service 对应的全部 Pod 的 Endpoint 列表。
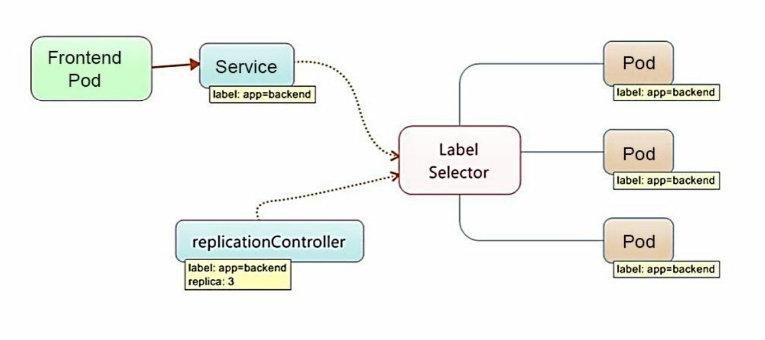
7. Service
Service 在 Kubernetes 中定义了一个服务的访问入口地址,前端的应用(Pod)通过这个入口地址访问其背后的一组由 Pod 副本组成的集群实例,Service 与其后端 Pod 副本集群之间则是通过 Label Selector 来实现无缝对接的。
1 | apiVersion: v1 |
Service 的负载均衡
在 Kubernetes 集群中,每个 Node 上会运行着 kube-proxy 组件,这其实就是一个负载均衡器,负责把对 Service 的请求转发到后端的某个 Pod 实例上,并在内部实现服务的负载均衡和会话保持机制。其主要的实现就是每个 Service 在集群中都被分配了一个全局唯一的 Cluster IP,因此我们对 Service 的网络通信根据内部的负载均衡算法和会话机制,便能与 Pod 副本集群通信。
Service 的服务发现
因为 Cluster IP 在 Service 的整个声明周期内是固定的,所以在 Kubernetes 中,只需将 Service 的 Name 和 其 Cluster IP 做一个 DNS 域名映射即可解决。
8. Volume
Volume 是 Pod 中能够被多个容器访问的共享目录,Kubernetes 中的 Volume 概念、用途、目的与 Docker 中的 Volumn 比较类似,但不等价。首先,其可被定义在 Pod 上,然后被 一个 Pod 里的多个容器挂载到具体的文件目录下;其次,Kubernetes 中的 Volume 与 Pod 的生命周期相同,但与容器的生命周期不相关,当容器终止或者重启时,Volume 中的数据也不会丢失。
1 | template: |
Kubernetes 提供了非常丰富的 Volume 类型:
- emptyDir,它的初始内容为空,并且无须指定宿主机上对应的目录文件,因为这是 Kubernetes 自动分配的一个目录,当 Pod 从 Node 上移除 emptyDir 中的数据也会被永久删除,适用于临时数据。
- hostPath,hostPath 为在 Pod 上挂载宿主机上的文件或目录,适用于持久化保存的数据,比如容器应用程序生成的日志文件。
- NFS,可使用 NFS 网络文件系统提供的共享目录存储数据。
- 其他云持久化盘等
9. Persistent Volume
在使用虚拟机的情况下,我们通常会先定义一个网络存储,然后从中划出一个“网盘”并挂接到虚拟机上。Persistent Volume(PV)和与之相关联的 Persistent Volume Claim(PVC)也起到了类似的作用。PV 可以被理解成 Kubernetes 集群中的某个网络存储对应的一块存储,它与 Volume 类似,但有以下区别:
- PV 只能是网络存储,不属于任何 Node,但可以在每个 Node 上访问。
- PV 并不是被定义在 Pod 上的,而是独立于 Pod 之外定义的。
1 | apiVersion: v1 |
accessModes,有几种类型:
- ReadWriteOnce:读写权限,并且只能被单个 Node 挂载。
- ReadOnlyMany:只读权限,允许被多个 Node 挂载。
- ReadWriteMany:读写权限,允许被多个 Node 挂载。
如果 Pod 想申请某种类型的 PV,首先需要定义一个 PersistentVolumeClaim 对象,
1 | apiVersion: v1 |
然后在 Pod 的 Volume 中引用 PVC 即可。
1 | volumes: |
PV 有以下几种状态:
- Available:空闲
- Bound:已绑定到 PVC
- Relead:对应 PVC 被删除,但 PV 还没被回收
- Faild: PV 自动回收失败
10. Namespace
Namespace 在很多情况下用于实现多租户的资源隔离。分组的不同项目、小组或用户组,便于不同的分组在共享使用整个集群的资源的同时还能被分别管理。Kubernetes 集群在启动后会创建一个名为 default 的 Namespace,通过 kubectl 可以查看:

11. ConfigMap
我们知道,Docker 通过将程序、依赖库、数据及 配置文件“打包固化”到一个不变的镜像文件中的做法,解决了应用的部署的难题,但这同时带来了棘手的问题,即配置文件中的参数在运行期如何修改的问题。我们不可能在启动 Docker 容器后再修改容器里的配置文件,然后用新的配置文件重启容器里的用户主进程。为了解决这个问题,Docker 提供了两种方式:
- 在运行时通过容器的环境变量来传递参数;
- 通过 Docker Volume 将容器外的配置文件映射到容器内。
在大多数情况下,后一种方式更合适我们的系统,因为大多数应用通常从一个或多个配置文件中读取参数。但这种方式也有明显的缺陷:我们必须在目标主机上先创建好对应配置文件,然后才能映射到容器里。上述缺陷在分布式情况下变得更为严重,因为无论采用哪种方式, 写入(修改)多台服务器上的某个指定文件,并确保这些文件保持一致,都是一个很难完成的目标。针对上述问题, Kubernetes 给出了一个很巧妙的设计实现。
首先,把所有的配置项都当作 key-value 字符串,这些配置项可以作为 Map 表中的一个项,整个 Map 的数据可以被持久化存储在 Kubernetes 的 ETCD 数据库中,然后提供 API 以方便 Kubernetes 相关组件或客户应用 CRUD 操作这些数据,上述专门用来保存配置参数的 Map 就是 Kubernetes ConfigMap 资源对象。Kubernetes 提供了一种内建机制,将存储在 ETCD 中的 ConfigMap 通过 Volume 映射的方式变成目标 Pod 内的配置文件,不管目标 Pod 被调度到哪台服务器上,都会完成自动映射。进一步地,如果 ConfigMap 中的 key-value 数据被修改,则映射到 Pod 中的“配置文件”也会随之自动更新。

4、Kubernetes 的架构

Kubernetes 由 Master 节点、 Node 节点以及外部的 ETCD 集群组成,集群的状态、资源对象、网络等信息存储在 ETCD 中,Mater 节点管控整个集群,包括通信、调度等,Node 节点为工作真正执行的节点,并向主节点报告。Master 节点由以下组件构成:
1. Master 组件
API Server——提供 HTTP Rest 接口,是所有资源增删改查和集群控制的唯一入口。在集群中表现为名称是 kubernetes 的 service。可以通过 Dashboard 的 UI 或 kubectl 工具来与其交互。
- 集群管理的 API 入口;
- 资源配额控制入口;
- 提供完备的集群安全机制。
Controller Manager——资源对象的控制自动化中心。即监控 Node,当故障时转移资源对象,自动修复集群到期望状态。
Scheduler——负责 Pod 的调度,调度到最优的 Node。
2. Node 组件
- kubelet——负责 Pod 内容器的创建、启停,并与 Master 密切协作实现集群管理(注册自己,汇报 Node 状态)。
- kube-proxy——实现 k8s Service 的通信与负载均衡。
- Docker Engine——Docker 引擎,负责本机容器的创建和管理。
5、Kubernetes 架构模块实现原理
Kubernetes 设计理念和功能其实就是一个类似 Linux 的分层架构,如下图所示:

- 核心层:Kubernetes 最核心的功能,对外提供 API 构建高层的应用,对内提供插件式应用执行环境
- 应用层:部署(无状态应用、有状态应用、批处理任务、集群应用等)和路由(服务发现、DNS 解析等)
- 管理层:系统度量(如基础设施、容器和网络的度量),自动化(如自动扩展、动态 Provision 等)以及策略管理RBAC、Quota、PSP、NetworkPolicy 等
- 接口层:kubectl 命令行工具、客户端 SDK 以及集群联邦
- 生态系统:在接口层之上的庞大容器集群管理调度的生态系统,可以划分为两个范畴。
1. API Server
Kubernetes API Server 通过一个名为 kube-apiserver 的进程提供服务,该进程运行在 Master 上。在默认情况下,kube-apiserver 进程在本机的 8080 端口(对应参数—insecure-port)提供 REST 服务。我们可以同时启动 HTTPS 安全端口(—secure-port=6443)来启动安全机制,加强 REST API 访问的安全性。
由于 API Server 是 Kubernetes 集群数据的唯一访问入口,因此安全性与高性能就成为 API Server 设计和实现的两大核心目标。通过采用 HTTPS 安全传输通道与 CA 签名数字证书强制双向认证的方式,API Server 的安全性得以保障。此外,为了更细粒度地控制用户或应用对 Kubernetes 资源对象的访问权限,Kubernetes 启用了 RBAC 访问控制策略。Kubernetes 的设计者综合运用以下方式来最大程度地保证 API Server 的性 能。
- API Server 拥有大量高性能的底层代码。在 API Server 源码中使用协程(Coroutine)+队列(Queue)这种轻量级的高性能并发代码, 使得单进程的 API Server 具备了超强的多核处理能力,从而以很快的速度并发处理大量的请求。
- 普通 List 接口结合异步 Watch 接口,不但完美解决了 Kubernetes 中各种资源对象的高性能同步问题,也极大提升了 Kubernetes 集群实时响应各种事件的灵敏度。
- 采用了高性能的 etcd 数据库而非传统的关系数据库,不仅解决了数据的可靠性问题,也极大提升了 API Server 数据访问层的性能。在 常见的公有云环境中,一个 3 节点的 etcd 集群在轻负载环境中处理一个请 求的时间可以低于 1ms,在重负载环境中可以每秒处理超过 30000 个请求。
2. 安全认证
RBAC
Role-Based Access Control(RBAC),基于角色的访问控制。
4 种资源对象
- Role
- RoleBinding
- ClusterRole
- ClusterRoleBinding
Role 与 ClusterRole
一个角色就是一组权限的集合,都是以许可形式,不存在拒绝的规则。Role 作用于一个命名空间中,ClusterRole 作用于整个集群。
1 | apiVersion: rbac.authorization.k8s.io/v1beta1 |
RoleBinding 和 ClusterRoleBinding 是把 Role 和 ClusterRole 的权限绑定到 ServiceAccount 上。
1 | kind: ClusterRoleBinding |
ServiceAccount
Service Account 也是一种账号,但它并不是给 Kubernetes 集群的用户 (系统管理员、运维人员、租户用户等)用的,而是给运行在 Pod 里的进程用的,它为 Pod 里的进程提供了必要的身份证明。在每个 Namespace 下都有一个名为 default 的默认 Service Account 对象,在这个 Service Account 里面有一个名为 Tokens 的可以当作 Volume 被挂载到 Pod 里的 Secret,当 Pod 启动时,这个 Secret 会自动被挂载到 Pod 的指定目录下,用来协助完成 Pod 中的进程访问 API Server 时的身份鉴权。
3. Controller Manager
下边介绍几种 Controller Manager 的实现组件
ResourceQuota Controller
kubernetes 的配额管理使用过 Admission Control 来控制的,提供了两种约束,LimitRanger 和 ResourceQuota。LimitRanger 作用于 Pod 和 Container 之上(limit和request),ResourceQuota 则作用于 Namespace。 资源配额,分三个层次:
- 容器级别,对容器的 CPU、memory 做限制
- Pod 级别,对一个 Pod 内所有容器的可用资源做限制
- Namespace 级别,为 namespace 做限制,包括:
- pod数量
- RC数量
- Service数量
- ResourceQuota数量
- Secrete数量
- PV数量
Namespace Controller
管理 Namespace 的创建删除.
Endpoints Controller
Endpoints 表示一个 service 对应的所有 Pod 副本的访问地址,而 Endpoints Controller 就是负责生成和维护所有 Endpoints 对象的控制器。
- 负责监听 Service 和对应 Pod 副本的变化,若 Service 被创建、更新、删除,则相应创建、更新、删除与 Service 同名的 Endpoints 对象。
- EndPoints 对象被 Node 上的 kube-proxy 使用。
4. Scheduler
Kubernetes Scheduler 的作用是将待调度的 Pod(API 新创建的 Pod、Controller Manager 为补足副本而创建的 Pod 等)按照特定的调度算法和调度策略绑定(Binding)到集群中某个合适的 Node 上,并将绑定信息写入 etcd 中。Kubernetes Scheduler 当前提供的默认调度流程分为以下两步。
- 预选调度过程,即遍历所有目标 Node,筛选出符合要求的候选节点。为此,Kubernetes 内置了多种预选策略(xxx Predicates)供用户选择。
- 确定最优节点,在第 1 步的基础上,采用优选策略(xxx Priority)计算出每个候选节点的积分,积分最高者胜出。
5. 网络
Kubernetes 的网络利用了 Docker 的网络原理,并在此基础上实现了跨 Node 容器间的网络通信。
同一个 Node 下 Pod 间通信模型:

不同 Node 下 Pod 间的通信模型(CNI 模型实现):

CNI 提供了一种应用容器的插件化网络解决方案,定义对容器网络进行操作和配置的规范,通过插件的形式对 CNI 接口进行实现,以 Flannel 举例,完成了 Node 间容器的通信模型。

可以看到,Flannel 首先创建了一个名为 flannel0 的网桥,而且这个 网桥的一端连接 docker0 网桥,另一端连接一个叫作 flanneld 的服务进程。flanneld 进程并不简单,它上连 etcd,利用 etcd 来管理可分配的 IP 地 址段资源,同时监控 etcd 中每个 Pod 的实际地址,并在内存中建立了一 个 Pod 节点路由表;它下连 docker0 和物理网络,使用内存中的 Pod 节点 路由表,将 docker0 发给它的数据包包装起来,利用物理网络的连接将 数据包投递到目标 flanneld 上,从而完成 Pod 到 Pod 之间的直接地址通信。
6. 服务发现
从 Kubernetes 1.11 版本开始,Kubernetes 集群的 DNS 服务由 CoreDNS 提供。CoreDNS 是 CNCF 基金会的一个项目,是用 Go 语言实现的高性能、插件式、易扩展的 DNS 服务端。

6、常用命令

基础命令
create:根据文件或者输入来创建资源
1
2
3# 创建Deployment和Service资源
kubectl create -f javak8s-deployment.yaml
kubectl create -f javak8s-service.yamldelete:删除资源
1
2
3
4
5# 根据yaml文件删除对应的资源,但是yaml文件并不会被删除,这样更加高效
kubectl delete -f javak8s-deployment.yaml
kubectl delete -f javak8s-service.yaml
# 也可以通过具体的资源名称来进行删除,使用这个删除资源,需要同时删除pod和service资源才行
kubectl delete 具体的资源名称get:获得资源信息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43# 查看所有的资源信息
kubectl get all
# 查看pod列表
kubectl get pod
# 显示pod节点的标签信息
kubectl get pod --show-labels
# 根据指定标签匹配到具体的pod
kubectl get pods -l app=example
# 查看node节点列表
kubectl get node
# 显示node节点的标签信息
kubectl get node --show-labels
# 查看pod详细信息,也就是可以查看pod具体运行在哪个节点上(ip地址信息)
kubectl get pod -o wide
# 查看服务的详细信息,显示了服务名称,类型,集群ip,端口,时间等信息
kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
go-service NodePort 10.10.10.247 <none> 8089:33702/TCP 29m
java-service NodePort 10.10.10.248 <none> 8082:32823/TCP 5h17m
kubernetes ClusterIP 10.10.10.1 <none> 443/TCP 5d16h
nginx-service NodePort 10.10.10.146 <none> 88:34823/TCP 2d19h
# 查看命名空间
kubectl get ns
# 查看所有pod所属的命名空间
kubectl get pod --all-namespaces
# 查看所有pod所属的命名空间并且查看都在哪些节点上运行
kubectl get pod --all-namespaces -o wide
# 查看目前所有的replica set,显示了所有的pod的副本数,以及他们的可用数量以及状态等信息
kubectl get rs
NAME DESIRED CURRENT READY AGE
go-deployment-58c76f7d5c 1 1 1 32m
java-deployment-76889f56c5 1 1 1 5h21m
nginx-deployment-58d6d6ccb8 3 3 3 2d19h
# 查看目前所有的deployment
kubectl get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
go-deployment 1/1 1 1 34m
java-deployment 1/1 1 1 5h23m
nginx-deployment 3/3 3 3 2d19h
# 查看已经部署了的所有应用,可以看到容器,以及容器所用的镜像,标签等信息
kubectl get deploy -o wide
NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
nginx 3/3 3 3 16m nginx nginx:1.10 app=examplerun:在集群中创建并运行一个或多个容器镜像。
1
2
3
4# 基本语法
kubectl run NAME --image=image [--env="key=value"] [--port=port] [--replicas=replicas] [--dry-run=bool] [--overrides=inline-json] [--command] -- [COMMAND] [args...]
# 示例,运行一个名称为nginx,副本数为3,标签为app=example,镜像为nginx:1.10,端口为80的容器实例
kubectl run nginx --replicas=3 --labels="app=example" --image=nginx:1.10 --port=80expose:创建一个service服务,并且暴露端口让外部可以访问
1
2# 创建一个nginx服务并且暴露端口让外界可以访问
kubectl expose deployment nginx --port=88 --type=NodePort --target-port=80 --name=nginx-service关于expose的详细用法参见:http://docs.kubernetes.org.cn/475.html
set: 配置应用的一些特定资源,也可以修改应用已有的资源
1
# 使用kubectl set --help查看,它的子命令,env,image,resources,selector,serviceaccount,subject。
set命令详情参见:http://docs.kubernetes.org.cn/669.html
kubectl set resources
1
resources (-f FILENAME | TYPE NAME) ([--limits=LIMITS & --requests=REQUESTS]
这个命令用于设置资源的一些范围限制。
资源对象中的Pod可以指定计算资源需求(CPU-单位m、内存-单位Mi),即使用的最小资源请求(Requests),限制(Limits)的最大资源需求,Pod将保证使用在设置的资源数量范围。
对于每个Pod资源,如果指定了Limits(限制)值,并省略了Requests(请求),则Requests默认为Limits的值。
可用资源对象包括(支持大小写):replicationcontroller、deployment、daemonset、job、replicaset。
例如:
1
2
3
4
5
6# 将deployment的nginx容器cpu限制为“200m”,将内存设置为“512Mi”
kubectl set resources deployment nginx -c=nginx --limits=cpu=200m,memory=512Mi
# 为nginx中的所有容器设置 Requests和Limits
kubectl set resources deployment nginx --limits=cpu=200m,memory=512Mi --requests=cpu=100m,memory=256Mi
# 删除nginx中容器的计算资源值
kubectl set resources deployment nginx --limits=cpu=0,memory=0 --requests=cpu=0,memory=0kubectl set selector
设置资源的selector(选择器)。如果在调用”set selector”命令之前已经存在选择器,则新创建的选择器将覆盖原来的选择器。
selector必须以字母或数字开头,最多包含63个字符,可使用:字母、数字、连字符” - “ 、点”.”和下划线” _ “。如果指定了—resource-version,则更新将使用此资源版本,否则将使用现有的资源版本。
注意:目前selector命令只能用于Service对象。
1
kubectl set selector (-f FILENAME | TYPE NAME) EXPRESSIONS [--resource-version=version]
kubectl set image命令
用于更新现有资源的容器镜像。
可用资源对象包括:pod (po)、replicationcontroller (rc)、deployment (deploy)、daemonset (ds)、job、replicaset (rs)。
1
2
3
4
5
6
7
8
9
10# 语法
kubectl set image (-f FILENAME | TYPE NAME) CONTAINER_NAME_1=CONTAINER_IMAGE_1 ... CONTAINER_NAME_N=CONTAINER_IMAGE_N
# 将deployment中的nginx容器镜像设置为“nginx:1.9.1”。
kubectl set image deployment/nginx busybox=busybox nginx=nginx:1.9.1
# 所有deployment和rc的nginx容器镜像更新为“nginx:1.9.1”
kubectl set image deployments,rc nginx=nginx:1.9.1 --all
# 将daemonset abc的所有容器镜像更新为“nginx:1.9.1”
kubectl set image daemonset abc *=nginx:1.9.1
# 从本地文件中更新nginx容器镜像
kubectl set image -f path/to/file.yaml nginx=nginx:1.9.1 --local -o yaml
explain:用于显示资源文档信息
1
kubectl explain rs
edit:用于编辑资源信息
1
2
3
4# 编辑Deployment nginx的一些信息
kubectl edit deployment nginx
# 编辑service类型的nginx的一些信息
kubectl edit service/nginx
设置命令
label:用于更新(增加、修改或删除)资源上的 label(标签)
- label 必须以字母或数字开头,可以使用字母、数字、连字符、点和下划线,最长63个字符。
- 如果—overwrite 为 true,则可以覆盖已有的 label,否则尝试覆盖 label 将会报错。
- 如果指定了—resource-version,则更新将使用此资源版本,否则将使用现有的资源版本。
1
2
3
4
5
6
7
8
9
10
11
12# 语法
kubectl label [--overwrite] (-f FILENAME | TYPE NAME) KEY_1=VAL_1 ... KEY_N=VAL_N [--resource-version=version]
# 给名为foo的Pod添加label unhealthy=true
kubectl label pods foo unhealthy=true
# 给名为foo的Pod修改label 为 'status' / value 'unhealthy',且覆盖现有的value
kubectl label --overwrite pods foo status=unhealthy
# 给 namespace 中的所有 pod 添加 label
kubectl label pods --all status=unhealthy
# 仅当resource-version=1时才更新 名为foo的Pod上的label
kubectl label pods foo status=unhealthy --resource-version=1
# 删除名为“bar”的label 。(使用“ - ”减号相连)
kubectl label pods foo bar-annotate:更新一个或多个资源的Annotations信息。也就是注解信息,可以方便的查看做了哪些操作。
- Annotations由key/value组成。
- Annotations的目的是存储辅助数据,特别是通过工具和系统扩展操作的数据,更多介绍在这里。
- 如果—overwrite为true,现有的annotations可以被覆盖,否则试图覆盖annotations将会报错。
- 如果设置了—resource-version,则更新将使用此resource version,否则将使用原有的resource version。
1
2
3
4
5
6
7
8
9
10
11
12
13
14# 语法
kubectl annotate [--overwrite] (-f FILENAME | TYPE NAME) KEY_1=VAL_1 ... KEY_N=VAL_N [--resource-version=version]
# 更新Pod“foo”,设置annotation “description”的value “my frontend”,如果同一个annotation多次设置,则只使用最后设置的value值
kubectl annotate pods foo description='my frontend'
# 根据“pod.json”中的type和name更新pod的annotation
kubectl annotate -f pod.json description='my frontend'
# 更新Pod"foo",设置annotation“description”的value“my frontend running nginx”,覆盖现有的值
kubectl annotate --overwrite pods foo description='my frontend running nginx'
# 更新 namespace中的所有pod
kubectl annotate pods --all description='my frontend running nginx'
# 只有当resource-version为1时,才更新pod ' foo '
kubectl annotate pods foo description='my frontend running nginx' --resource-version=1
# 通过删除名为“description”的annotations来更新pod ' foo '。#不需要- overwrite flag。
kubectl annotate pods foo description-completion:用于设置kubectl命令自动补全
1
2$ source <(kubectl completion bash) # setup autocomplete in bash, bash-completion package should be installed first.
$ source <(kubectl completion zsh) # setup autocomplete in zsh
部署命令
rollout:用于对资源进行管理
可用资源包括:deployments,daemonsets。
子命令:
1
2
3
4
5
6# 语法
kubectl rollout SUBCOMMAND
# 回滚到之前的deployment
kubectl rollout undo deployment/abc
# 查看daemonet的状态
kubectl rollout status daemonset/foorolling-update:执行指定ReplicationController的滚动更新。
该命令创建了一个新的RC, 然后一次更新一个pod方式逐步使用新的PodTemplate,最终实现Pod滚动更新,new-controller.json需要与之前RC在相同的namespace下。
1
2
3
4
5
6
7
8
9
10# 语法
kubectl rolling-update OLD_CONTROLLER_NAME ([NEW_CONTROLLER_NAME] --image=NEW_CONTAINER_IMAGE | -f NEW_CONTROLLER_SPEC)
# 使用frontend-v2.json中的新RC数据更新frontend-v1的pod
kubectl rolling-update frontend-v1 -f frontend-v2.json
# 使用JSON数据更新frontend-v1的pod
cat frontend-v2.json | kubectl rolling-update frontend-v1 -f -
# 其他的一些滚动更新
kubectl rolling-update frontend-v1 frontend-v2 --image=image:v2
kubectl rolling-update frontend --image=image:v2
kubectl rolling-update frontend-v1 frontend-v2 --rollbackscale:扩容或缩容 Deployment、ReplicaSet、Replication Controller或 Job 中Pod数量
scale也可以指定多个前提条件,如:当前副本数量或 —resource-version ,进行伸缩比例设置前,系统会先验证前提条件是否成立。这个就是弹性伸缩策略
1
2
3
4
5
6
7
8
9
10
11# 语法
kubectl scale [--resource-version=version] [--current-replicas=count] --replicas=COUNT (-f FILENAME | TYPE NAME)
# 将名为foo中的pod副本数设置为3。
kubectl scale --replicas=3 rs/foo
kubectl scale deploy/nginx --replicas=30
# 将由“foo.yaml”配置文件中指定的资源对象和名称标识的Pod资源副本设为3
kubectl scale --replicas=3 -f foo.yaml
# 如果当前副本数为2,则将其扩展至3。
kubectl scale --current-replicas=2 --replicas=3 deployment/mysql
# 设置多个RC中Pod副本数量
kubectl scale --replicas=5 rc/foo rc/bar rc/bazautoscale: 这个比scale更加强大,也是弹性伸缩策略 ,它是根据流量的多少来自动进行扩展或者缩容
指定Deployment、ReplicaSet或ReplicationController,并创建已经定义好资源的自动伸缩器。使用自动伸缩器可以根据需要自动增加或减少系统中部署的pod数量。
1
2
3
4
5
6# 语法
kubectl autoscale (-f FILENAME | TYPE NAME | TYPE/NAME) [--min=MINPODS] --max=MAXPODS [--cpu-percent=CPU] [flags]
# 使用 Deployment “foo”设定,使用默认的自动伸缩策略,指定目标CPU使用率,使其Pod数量在2到10之间
kubectl autoscale deployment foo --min=2 --max=10
# 使用RC“foo”设定,使其Pod的数量介于1和5之间,CPU使用率维持在80%
kubectl autoscale rc foo --max=5 --cpu-percent=80
集群管理命令
certificate:用于证书资源管理,授权等
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15kubectl certificate --help
Modify certificate resources.
Available Commands:
approve Approve a certificate signing request
deny Deny a certificate signing request
Usage:
kubectl certificate SUBCOMMAND [options]
Use "kubectl <command> --help" for more information about a given command.
Use "kubectl options" for a list of global command-line options (applies to all commands).
# 例如,当有node节点要向master请求,那么是需要master节点授权的
kubectl certificate approve node-csr-81F5uBehyEyLWco5qavBsxc1GzFcZk3aFM3XW5rT3mw node-csr-Ed0kbFhc_q7qx14H3QpqLIUs0uKo036O2SnFpIheM18cluster-info:显示集群信息
1
2
3kubectl cluster-info
Kubernetes master is running at http://localhost:8080
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.top:用于查看资源的cpu,内存磁盘等资源的使用率
1
kubectl top pod --all-namespaces
它需要heapster运行才行。
cordon:用于标记某个节点不可调度
uncordon:用于标签节点可以调度
drain: 用于在维护期间排除节点。
taint:参见:https://blog.frognew.com/2018/05/taint-and-toleration.html
故障诊断和调试命令
describe:显示特定资源的详细信息
1
2
3
4
5
6# 语法
kubectl describe TYPE NAME_PREFIX
(首先检查是否有精确匹配TYPE和NAME_PREFIX的资源,如果没有,将会输出所有名称以NAME_PREFIX开头的资源详细信息)
支持的资源包括但不限于(大小写不限):pods (po)、services (svc)、 replicationcontrollers (rc)、nodes (no)、events (ev)、componentstatuses (cs)、 limitranges (limits)、persistentvolumes (pv)、persistentvolumeclaims (pvc)、 resourcequotas (quota)和secrets。
#查看my-nginx pod的详细状态
kubectl describe po my-nginxlogs:用于在一个pod中打印一个容器的日志,如果pod中只有一个容器,可以省略容器名
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22# 语法
kubectl logs [-f] [-p] POD [-c CONTAINER]
# 返回仅包含一个容器的pod nginx的日志快照
$ kubectl logs nginx
# 返回pod ruby中已经停止的容器web-1的日志快照
$ kubectl logs -p -c ruby web-1
# 持续输出pod ruby中的容器web-1的日志
$ kubectl logs -f -c ruby web-1
# 仅输出pod nginx中最近的20条日志
$ kubectl logs --tail=20 nginx
# 输出pod nginx中最近一小时内产生的所有日志
$ kubectl logs --since=1h nginx
# 参数选项
-c, --container="": 容器名。
-f, --follow[=false]: 指定是否持续输出日志(实时日志)。
--interactive[=true]: 如果为true,当需要时提示用户进行输入。默认为true。
--limit-bytes=0: 输出日志的最大字节数。默认无限制。
-p, --previous[=false]: 如果为true,输出pod中曾经运行过,但目前已终止的容器的日志。
--since=0: 仅返回相对时间范围,如5s、2m或3h,之内的日志。默认返回所有日志。只能同时使用since和since-time中的一种。
--since-time="": 仅返回指定时间(RFC3339格式)之后的日志。默认返回所有日志。只能同时使用since和since-time中的一种。
--tail=-1: 要显示的最新的日志条数。默认为-1,显示所有的日志。
--timestamps[=false]: 在日志中包含时间戳。exec:进入容器进行交互,在容器中执行命令
1
2
3
4
5
6
7
8
9# 语法
kubectl exec POD [-c CONTAINER] -- COMMAND [args...]
#命令选项
-c, --container="": 容器名。如果未指定,使用pod中的一个容器。
-p, --pod="": Pod名。
-i, --stdin[=false]: 将控制台输入发送到容器。
-t, --tty[=false]: 将标准输入控制台作为容器的控制台输入。
# 进入nginx容器,执行一些命令操作
kubectl exec -it nginx-deployment-58d6d6ccb8-lc5fp bashattach:连接到一个正在运行的容器。
1
2
3
4
5
6
7
8
9
10
11
12
13
14#语法
kubectl attach POD -c CONTAINER
# 参数选项
-c, --container="": 容器名。如果省略,则默认选择第一个 pod
-i, --stdin[=false]: 将控制台输入发送到容器。
-t, --tty[=false]: 将标准输入控制台作为容器的控制台输入。
# 获取正在运行中的pod 123456-7890的输出,默认连接到第一个容器
kubectl attach 123456-7890
# 获取pod 123456-7890中ruby-container的输出
kubectl attach 123456-7890 -c ruby-container
# 切换到终端模式,将控制台输入发送到pod 123456-7890的ruby-container的“bash”命令,并将其输出到控制台/
# 错误控制台的信息发送回客户端。
kubectl attach 123456-7890 -c ruby-container -i -tcp:拷贝文件或者目录到pod容器中
用于pod和外部的文件交换,类似于docker 的cp,就是将容器中的内容和外部的内容进行交换。
其他命令
api-servions:打印受支持的api版本信息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25kubectl api-versions
admissionregistration.k8s.io/v1beta1
apiextensions.k8s.io/v1beta1
apiregistration.k8s.io/v1beta1
apps/v1
apps/v1beta1
apps/v1beta2
authentication.k8s.io/v1
authentication.k8s.io/v1beta1
authorization.k8s.io/v1
authorization.k8s.io/v1beta1
autoscaling/v1
autoscaling/v2beta1
batch/v1
batch/v1beta1
certificates.k8s.io/v1beta1
events.k8s.io/v1beta1
extensions/v1beta1
networking.k8s.io/v1
policy/v1beta1
rbac.authorization.k8s.io/v1
rbac.authorization.k8s.io/v1beta1
storage.k8s.io/v1
storage.k8s.io/v1beta1
v1help:用于查看命令帮助
1
2
3
4# 显示全部的命令帮助提示
kubectl --help
# 具体的子命令帮助,例如
kubectl create --helpconfig:用于修改kubeconfig配置文件(用于访问api,例如配置认证信息)
version:打印客户端和服务端版本信息
1
2
3kubectl version
Client Version: version.Info{Major:"1", Minor:"15", GitVersion:"v1.15.3", GitCommit:"2d3c76f9091b6bec110a5e63777c332469e0cba2", GitTreeState:"clean", BuildDate:"2019-08-19T11:13:54Z", GoVersion:"go1.12.9", Compiler:"gc", Platform:"linux/amd64"}
Server Version: version.Info{Major:"1", Minor:"9", GitVersion:"v1.9.0", GitCommit:"925c127ec6b946659ad0fd596fa959be43f0cc05", GitTreeState:"clean", BuildDate:"2017-12-15T20:55:30Z", GoVersion:"go1.9.2", Compiler:"gc", Platform:"linux/amd64"}plugin:运行一个命令行插件
高级命令
apply: 通过文件名或者标准输入对资源应用配置
通过文件名或控制台输入,对资源进行配置。 如果资源不存在,将会新建一个。可以使用 JSON 或者 YAML 格式。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16# 语法
kubectl apply -f FILENAME
# 将pod.json中的配置应用到pod
kubectl apply -f ./pod.json
# 将控制台输入的JSON配置应用到Pod
cat pod.json | kubectl apply -f -
选项
-f, --filename=[]: 包含配置信息的文件名,目录名或者URL。
--include-extended-apis[=true]: If true, include definitions of new APIs via calls to the API server. [default true]
-o, --output="": 输出模式。"-o name"为快捷输出(资源/name).
--record[=false]: 在资源注释中记录当前 kubectl 命令。
-R, --recursive[=false]: Process the directory used in -f, --filename recursively. Useful when you want to manage related manifests organized within the same directory.
--schema-cache-dir="~/.kube/schema": 非空则将API schema缓存为指定文件,默认缓存到'$HOME/.kube/schema'
--validate[=true]: 如果为true,在发送到服务端前先使用schema来验证输入。patch: 使用补丁修改,更新资源的字段,也就是修改资源的部分内容
1
2
3
4
5
6
7# 语法
kubectl patch (-f FILENAME | TYPE NAME) -p PATCH
# Partially update a node using strategic merge patch
kubectl patch node k8s-node-1 -p '{"spec":{"unschedulable":true}}'
# Update a container's image; spec.containers[*].name is required because it's a merge key
kubectl patch pod valid-pod -p '{"spec":{"containers":[{"name":"kubernetes-serve-hostname","image":"new image"}]}}'replace: 通过文件或者标准输入替换原有资源
1
2
3
4
5
6
7
8
9
10
11# 语法
kubectl replace -f FILENAME
# Replace a pod using the data in pod.json.
kubectl replace -f ./pod.json
# Replace a pod based on the JSON passed into stdin.
cat pod.json | kubectl replace -f -
# Update a single-container pod's image version (tag) to v4
kubectl get pod mypod -o yaml | sed 's/\(image: myimage\):.*$/\1:v4/' | kubectl replace -f -
# Force replace, delete and then re-create the resource
kubectl replace --force -f ./pod.jsonconvert: 不同的版本之间转换配置文件
1
2
3
4
5
6
7
8
9
10# 语法
kubectl convert -f FILENAME
# Convert 'pod.yaml' to latest version and print to stdout.
kubectl convert -f pod.yaml
# Convert the live state of the resource specified by 'pod.yaml' to the latest version
# and print to stdout in json format.
kubectl convert -f pod.yaml --local -o json
# Convert all files under current directory to latest version and create them all.
kubectl convert -f . | kubectl create -f -

